 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn for Few-shot Continual Active Learning
Nov 07, 2023

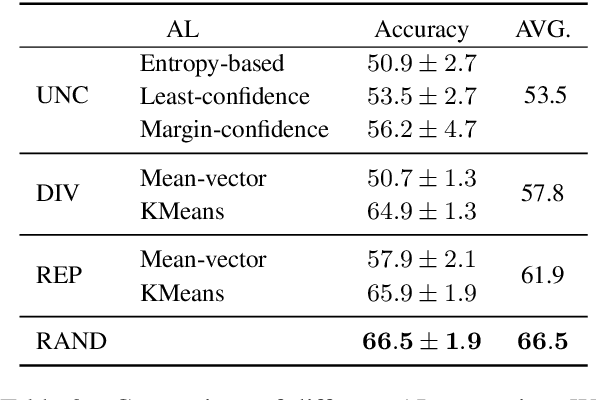
Continual learning strives to ensure stability in solving previously seen tasks while demonstrating plasticity in a novel domain. Recent advances in CL are mostly confined to a supervised learning setting, especially in NLP domain. In this work, we consider a few-shot continual active learning (CAL) setting where labeled data is inadequate, and unlabeled data is abundant but with a limited annotation budget. We propose a simple but efficient method, called Meta-Continual Active Learning. Specifically, we employ meta-learning and experience replay to address the trade-off between stability and plasticity. As a result, it finds an optimal initialization that efficiently utilizes annotated information for fast adaptation while preventing catastrophic forgetting of past tasks. We conduct extensive experiments to validate the effectiveness of the proposed method and analyze the effect of various active learning strategies and memory sample selection methods in a few-shot CAL setup. Our experiment results demonstrate that random sampling is the best default strategy for both active learning and memory sample selection to solve few-shot CAL problems.
Prototypes-Guided Memory Replay for Continual Learning
Aug 28, 2021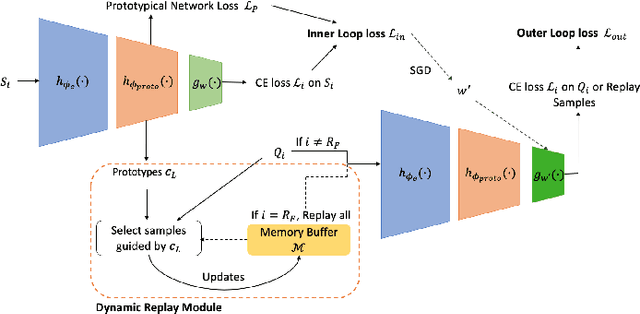
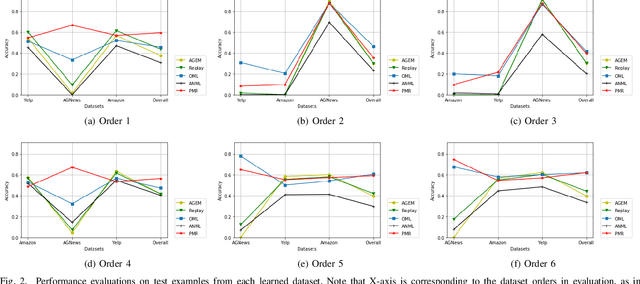
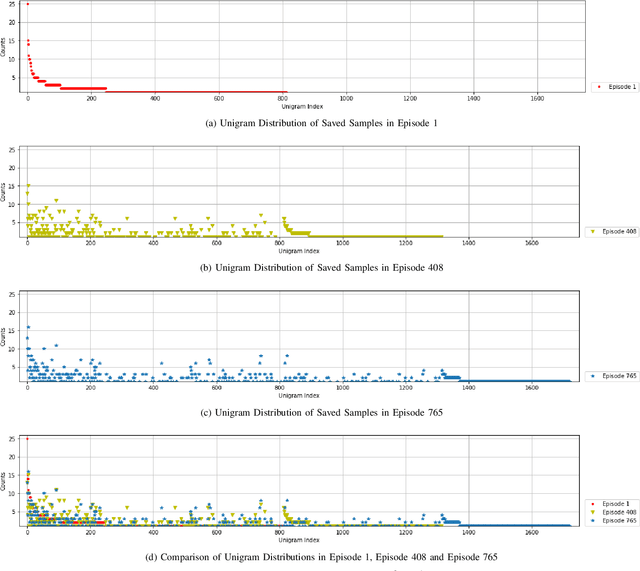
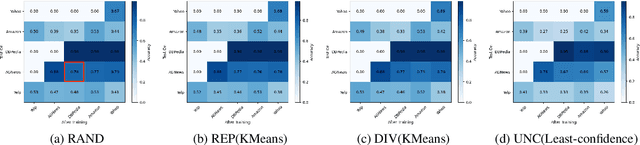
Continual learning (CL) refers to a machine learning paradigm that using only a small account of training samples and previously learned knowledge to enhance learning performance. CL models learn tasks from various domains in a sequential manner. The major difficulty in CL is catastrophic forgetting of previously learned tasks, caused by shifts in data distributions. The existing CL models often employ a replay-based approach to diminish catastrophic forgetting. Most CL models stochastically select previously seen samples to retain learned knowledge. However, occupied memory size keeps enlarging along with accumulating learned tasks. Hereby, we propose a memory-efficient CL method. We devise a dynamic prototypes-guided memory replay module, incorporating it into an online meta-learning model. We conduct extensive experiments on text classification and additionally investigate the effect of training set orders on CL model performance. The experimental results testify the superiority of our method in alleviating catastrophic forgetting and enabling efficient knowledge transfer.
Federated Learning Meets Natural Language Processing: A Survey
Jul 27, 2021Federated Learning aims to learn machine learning models from multiple decentralized edge devices (e.g. mobiles) or servers without sacrificing local data privacy. Recent Natural Language Processing techniques rely on deep learning and large pre-trained language models. However, both big deep neural and language models are trained with huge amounts of data which often lies on the server side. Since text data is widely originated from end users, in this work, we look into recent NLP models and techniques which use federated learning as the learning framework. Our survey discusses major challenges in federated natural language processing, including the algorithm challenges, system challenges as well as the privacy issues. We also provide a critical review of the existing Federated NLP evaluation methods and tools. Finally, we highlight the current research gaps and future directions.