 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-driven Gesture Generation via Deviation Feature in the Latent Space
Mar 27, 2025Gestures are essential for enhancing co-speech communication, offering visual emphasis and complementing verbal interactions. While prior work has concentrated on point-level motion or fully supervised data-driven methods, we focus on co-speech gestures, advocating for weakly supervised learning and pixel-level motion deviations. We introduce a weakly supervised framework that learns latent representation deviations, tailored for co-speech gesture video generation. Our approach employs a diffusion model to integrate latent motion features, enabling more precise and nuanced gesture representation. By leveraging weakly supervised deviations in latent space, we effectively generate hand gestures and mouth movements, crucial for realistic video production. Experiments show our method significantly improves video quality, surpassing current state-of-the-art techniques.
Teaching Embodied Reinforcement Learning Agents: Informativeness and Diversity of Language Use
Oct 31, 2024In real-world scenarios, it is desirable for embodied agents to have the ability to leverage human language to gain explicit or implicit knowledge for learning tasks. Despite recent progress, most previous approaches adopt simple low-level instructions as language inputs, which may not reflect natural human communication. It's not clear how to incorporate rich language use to facilitate task learning. To address this question, this paper studies different types of language inputs in facilitating reinforcement learning (RL) embodied agents. More specifically, we examine how different levels of language informativeness (i.e., feedback on past behaviors and future guidance) and diversity (i.e., variation of language expressions) impact agent learning and inference. Our empirical results based on four RL benchmarks demonstrate that agents trained with diverse and informative language feedback can achieve enhanced generalization and fast adaptation to new tasks. These findings highlight the pivotal role of language use in teaching embodied agents new tasks in an open world. Project website: https://github.com/sled-group/Teachable_RL
Implicit Contact Diffuser: Sequential Contact Reasoning with Latent Point Cloud Diffusion
Oct 21, 2024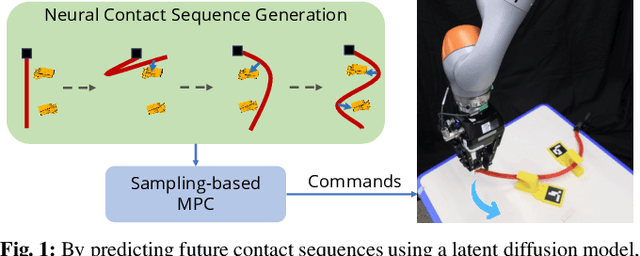
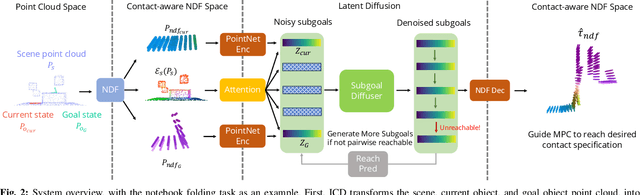
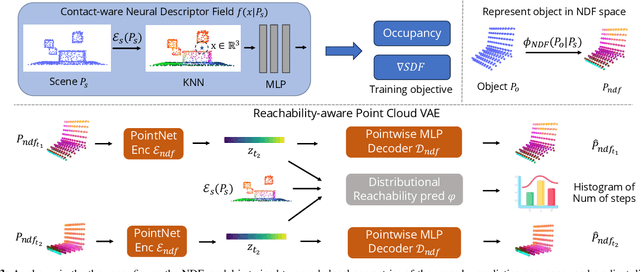
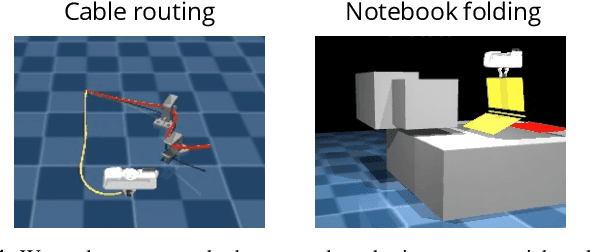
Long-horizon contact-rich manipulation has long been a challenging problem, as it requires reasoning over both discrete contact modes and continuous object motion. We introduce Implicit Contact Diffuser (ICD), a diffusion-based model that generates a sequence of neural descriptors that specify a series of contact relationships between the object and the environment. This sequence is then used as guidance for an MPC method to accomplish a given task. The key advantage of this approach is that the latent descriptors provide more task-relevant guidance to MPC, helping to avoid local minima for contact-rich manipulation tasks. Our experiments demonstrate that ICD outperforms baselines on complex, long-horizon, contact-rich manipulation tasks, such as cable routing and notebook folding. Additionally, our experiments also indicate that \methodshort can generalize a target contact relationship to a different environment. More visualizations can be found on our website $\href{https://implicit-contact-diffuser.github.io/}{https://implicit-contact-diffuser.github.io}$