 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatteryAgent: Synergizing Physics-Informed Interpretation with LLM Reasoning for Intelligent Battery Fault Diagnosis
Dec 31, 2025Fault diagnosis of lithium-ion batteries is critical for system safety. While existing deep learning methods exhibit superior detection accuracy, their "black-box" nature hinders interpretability. Furthermore, restricted by binary classification paradigms, they struggle to provide root cause analysis and maintenance recommendations. To address these limitations, this paper proposes BatteryAgent, a hierarchical framework that integrates physical knowledge features with the reasoning capabilities of Large Language Models (LLMs). The framework comprises three core modules: (1) A Physical Perception Layer that utilizes 10 mechanism-based features derived from electrochemical principles, balancing dimensionality reduction with physical fidelity; (2) A Detection and Attribution Layer that employs Gradient Boosting Decision Trees and SHAP to quantify feature contributions; and (3) A Reasoning and Diagnosis Layer that leverages an LLM as the agent core. This layer constructs a "numerical-semantic" bridge, combining SHAP attributions with a mechanism knowledge base to generate comprehensive reports containing fault types, root cause analysis, and maintenance suggestions. Experimental results demonstrate that BatteryAgent effectively corrects misclassifications on hard boundary samples, achieving an AUROC of 0.986, which significantly outperforms current state-of-the-art methods. Moreover, the framework extends traditional binary detection to multi-type interpretable diagnosis, offering a new paradigm shift from "passive detection" to "intelligent diagnosis" for battery safety management.
SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
HELLINGER-UCB: A novel algorithm for stochastic multi-armed bandit problem and cold start problem in recommender system
Apr 16, 2024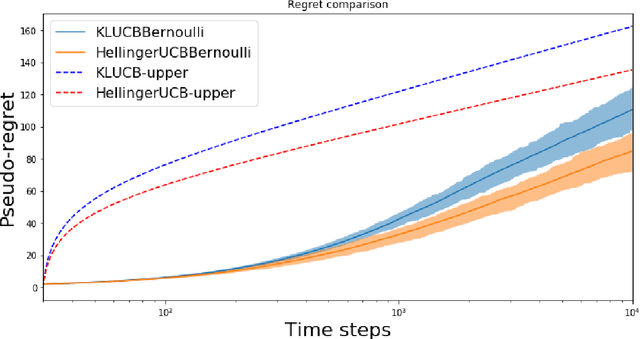

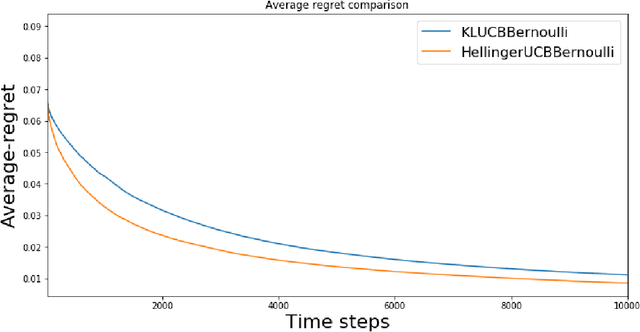
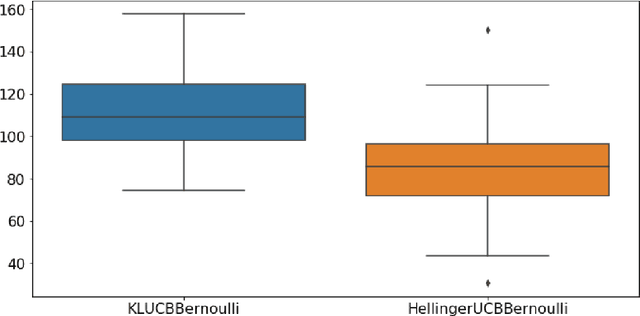
In this paper, we study the stochastic multi-armed bandit problem, where the reward is driven by an unknown random variable. We propose a new variant of the Upper Confidence Bound (UCB) algorithm called Hellinger-UCB, which leverages the squared Hellinger distance to build the upper confidence bound. We prove that the Hellinger-UCB reaches the theoretical lower bound. We also show that the Hellinger-UCB has a solid statistical interpretation. We show that Hellinger-UCB is effective in finite time horizons with numerical experiments between Hellinger-UCB and other variants of the UCB algorithm. As a real-world example, we apply the Hellinger-UCB algorithm to solve the cold-start problem for a content recommender system of a financial app. With reasonable assumption, the Hellinger-UCB algorithm has a convenient but important lower latency feature. The online experiment also illustrates that the Hellinger-UCB outperforms both KL-UCB and UCB1 in the sense of a higher click-through rate (CTR).
An Efficient and Robust System for Vertically Federated Random Forest
Jan 26, 2022As there is a growing interest in utilizing data across multiple resources to build better machine learning models, many vertically federated learning algorithms have been proposed to preserve the data privacy of the participating organizations. However, the efficiency of existing vertically federated learning algorithms remains to be a big problem, especially when applied to large-scale real-world datasets. In this paper, we present a fast, accurate, scalable and yet robust system for vertically federated random forest. With extensive optimization, we achieved $5\times$ and $83\times$ speed up over the SOTA SecureBoost model \cite{cheng2019secureboost} for training and serving tasks. Moreover, the proposed system can achieve similar accuracy but with favorable scalability and partition tolerance. Our code has been made public to facilitate the development of the community and the protection of user data privacy.
Fedlearn-Algo: A flexible open-source privacy-preserving machine learning platform
Jul 30, 2021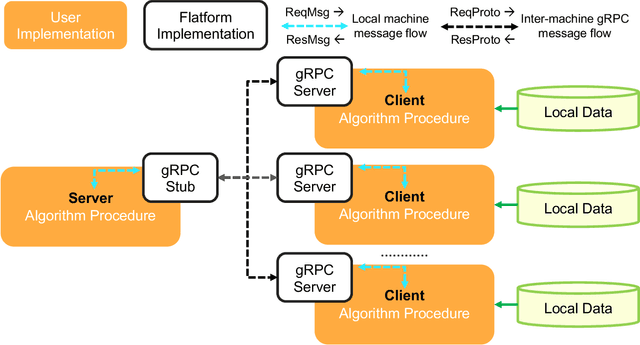
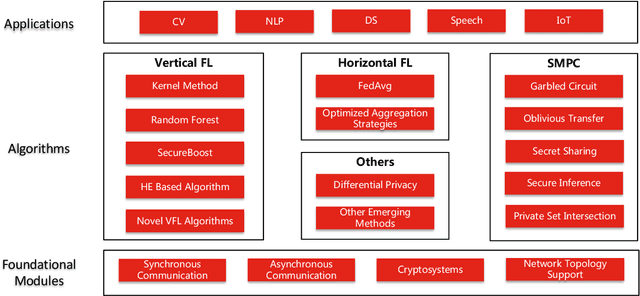
In this paper, we present Fedlearn-Algo, an open-source privacy preserving machine learning platform. We use this platform to demonstrate our research and development results on privacy preserving machine learning algorithms. As the first batch of novel FL algorithm examples, we release vertical federated kernel binary classification model and vertical federated random forest model. They have been tested to be more efficient than existing vertical federated learning models in our practice. Besides the novel FL algorithm examples, we also release a machine communication module. The uniform data transfer interface supports transferring widely used data formats between machines. We will maintain this platform by adding more functional modules and algorithm examples. The code is available at https://github.com/fedlearnAI/fedlearn-algo.