 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalse-Friend Detection and Entity Matching via Unsupervised Transliteration
Paper and Code
Nov 21, 2016
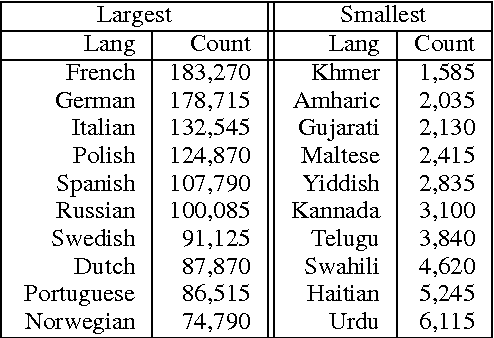
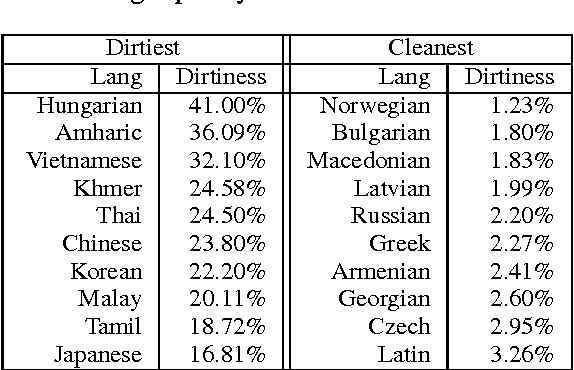

Transliterations play an important role in multilingual entity reference resolution, because proper names increasingly travel between languages in news and social media. Previous work associated with machine translation targets transliteration only single between language pairs, focuses on specific classes of entities (such as cities and celebrities) and relies on manual curation, which limits the expression power of transliteration in multilingual environment. By contrast, we present an unsupervised transliteration model covering 69 major languages that can generate good transliterations for arbitrary strings between any language pair. Our model yields top-(1, 20, 100) averages of (32.85%, 60.44%, 83.20%) in matching gold standard transliteration compared to results from a recently-published system of (26.71%, 50.27%, 72.79%). We also show the quality of our model in detecting true and false friends from Wikipedia high frequency lexicons. Our method indicates a strong signal of pronunciation similarity and boosts the probability of finding true friends in 68 out of 69 languages.