 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Selection with Heterogeneous Sensitivities
Jan 09, 2025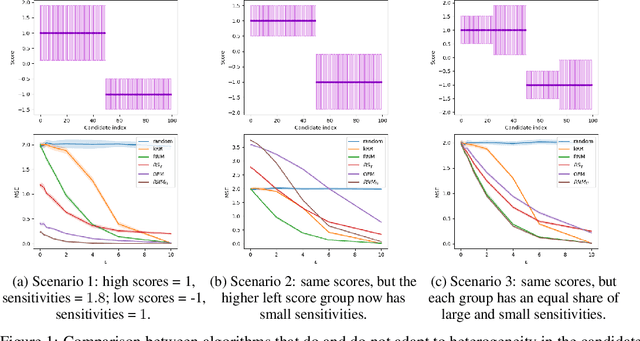
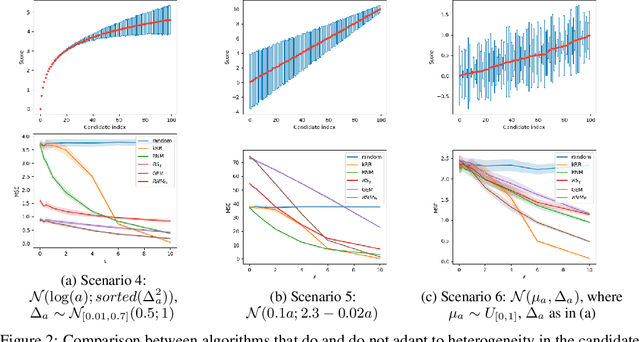
Differentially private (DP) selection involves choosing a high-scoring candidate from a finite candidate pool, where each score depends on a sensitive dataset. This problem arises naturally in a variety of contexts including model selection, hypothesis testing, and within many DP algorithms. Classical methods, such as Report Noisy Max (RNM), assume all candidates' scores are equally sensitive to changes in a single individual's data, but this often isn't the case. To address this, algorithms like the Generalised Exponential Mechanism (GEM) leverage variability in candidate sensitivities. However, we observe that while these algorithms can outperform RNM in some situations, they may underperform in others - they can even perform worse than random selection. In this work, we explore how the distribution of scores and sensitivities impacts DP selection mechanisms. In all settings we study, we find that there exists a mechanism that utilises heterogeneity in the candidate sensitivities that outperforms standard mechanisms like RNM. However, no single mechanism uniformly outperforms RNM. We propose using the correlation between the scores and sensitivities as the basis for deciding which DP selection mechanism to use. Further, we design a slight variant of GEM, modified GEM that generally performs well whenever GEM performs poorly. Relying on the correlation heuristic we propose combined GEM, which adaptively chooses between GEM and modified GEM and outperforms both in polarised settings.
Randomized algorithms for precise measurement of differentially-private, personalized recommendations
Aug 08, 2023



Personalized recommendations form an important part of today's internet ecosystem, helping artists and creators to reach interested users, and helping users to discover new and engaging content. However, many users today are skeptical of platforms that personalize recommendations, in part due to historically careless treatment of personal data and data privacy. Now, businesses that rely on personalized recommendations are entering a new paradigm, where many of their systems must be overhauled to be privacy-first. In this article, we propose an algorithm for personalized recommendations that facilitates both precise and differentially-private measurement. We consider advertising as an example application, and conduct offline experiments to quantify how the proposed privacy-preserving algorithm affects key metrics related to user experience, advertiser value, and platform revenue compared to the extremes of both (private) non-personalized and non-private, personalized implementations.