 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Image Segmentation with Cross-Modality Vision Transformers
Paper and Code
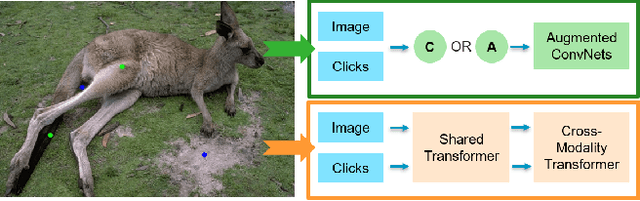
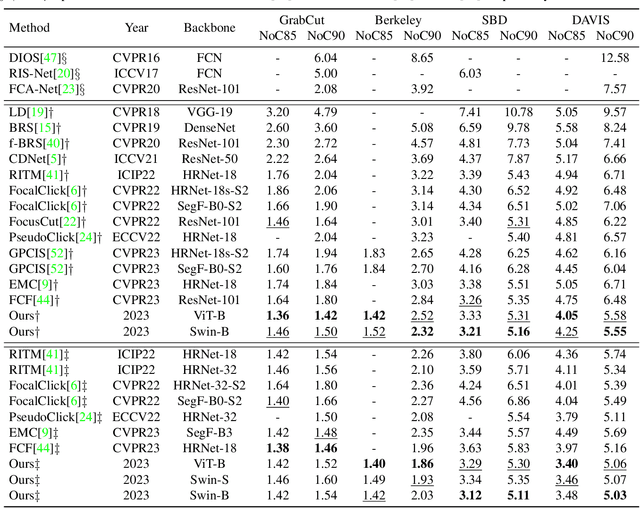
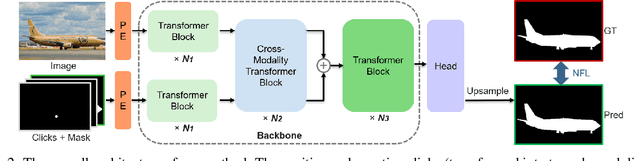
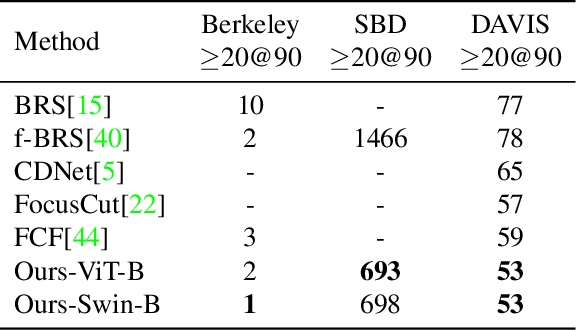
Interactive image segmentation aims to segment the target from the background with the manual guidance, which takes as input multimodal data such as images, clicks, scribbles, and bounding boxes. Recently, vision transformers have achieved a great success in several downstream visual tasks, and a few efforts have been made to bring this powerful architecture to interactive segmentation task. However, the previous works neglect the relations between two modalities and directly mock the way of processing purely visual information with self-attentions. In this paper, we propose a simple yet effective network for click-based interactive segmentation with cross-modality vision transformers. Cross-modality transformers exploits mutual information to better guide the learning process. The experiments on several benchmarks show that the proposed method achieves superior performance in comparison to the previous state-of-the-art models. The stability of our method in term of avoiding failure cases shows its potential to be a practical annotation tool. The code and pretrained models will be released under https://github.com/lik1996/iCMFormer.