 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the Hubbard model with Neural Quantum States
Jul 03, 2025The rapid development of neural quantum states (NQS) has established it as a promising framework for studying quantum many-body systems. In this work, by leveraging the cutting-edge transformer-based architectures and developing highly efficient optimization algorithms, we achieve the state-of-the-art results for the doped two-dimensional (2D) Hubbard model, arguably the minimum model for high-Tc superconductivity. Interestingly, we find different attention heads in the NQS ansatz can directly encode correlations at different scales, making it capable of capturing long-range correlations and entanglements in strongly correlated systems. With these advances, we establish the half-filled stripe in the ground state of 2D Hubbard model with the next nearest neighboring hoppings, consistent with experimental observations in cuprates. Our work establishes NQS as a powerful tool for solving challenging many-fermions systems.
Deep Learning based Multi-modal Computing with Feature Disentanglement for MRI Image Synthesis
May 06, 2021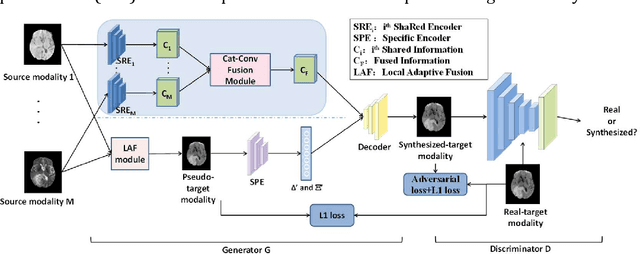
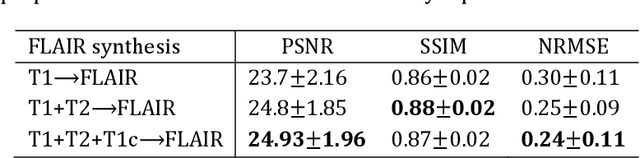
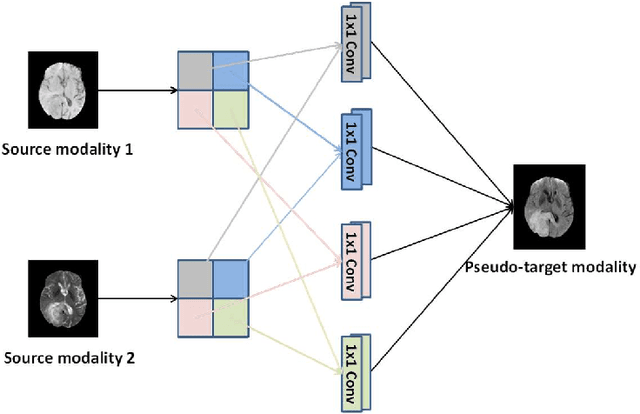
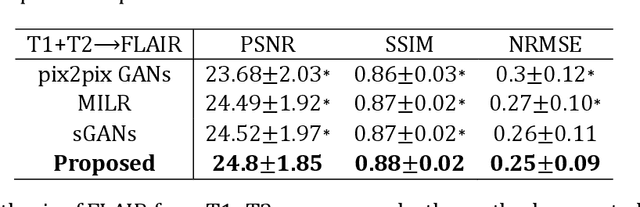
Purpose: Different Magnetic resonance imaging (MRI) modalities of the same anatomical structure are required to present different pathological information from the physical level for diagnostic needs. However, it is often difficult to obtain full-sequence MRI images of patients owing to limitations such as time consumption and high cost. The purpose of this work is to develop an algorithm for target MRI sequences prediction with high accuracy, and provide more information for clinical diagnosis. Methods: We propose a deep learning based multi-modal computing model for MRI synthesis with feature disentanglement strategy. To take full advantage of the complementary information provided by different modalities, multi-modal MRI sequences are utilized as input. Notably, the proposed approach decomposes each input modality into modality-invariant space with shared information and modality-specific space with specific information, so that features are extracted separately to effectively process the input data. Subsequently, both of them are fused through the adaptive instance normalization (AdaIN) layer in the decoder. In addition, to address the lack of specific information of the target modality in the test phase, a local adaptive fusion (LAF) module is adopted to generate a modality-like pseudo-target with specific information similar to the ground truth. Results: To evaluate the synthesis performance, we verify our method on the BRATS2015 dataset of 164 subjects. The experimental results demonstrate our approach significantly outperforms the benchmark method and other state-of-the-art medical image synthesis methods in both quantitative and qualitative measures. Compared with the pix2pixGANs method, the PSNR improves from 23.68 to 24.8. Conclusion: The proposed method could be effective in prediction of target MRI sequences, and useful for clinical diagnosis and treatment.