 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic 3D Embedding via View Alignment
Paper and Code
Jul 14, 2020

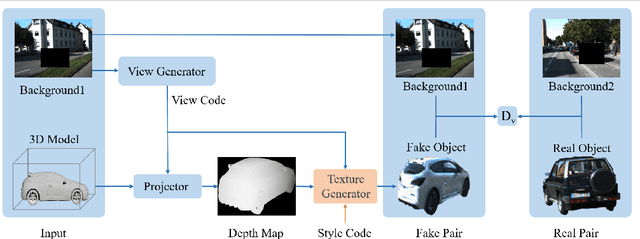

Recent advances in generative adversarial networks (GANs) have achieved great success in automated image composition that generates new images by embedding interested foreground objects into background images automatically. On the other hand, most existing works deal with foreground objects in two-dimensional (2D) images though foreground objects in three-dimensional (3D) models are more flexible with 360-degree view freedom. This paper presents an innovative View Alignment GAN (VA-GAN) that composes new images by embedding 3D models into 2D background images realistically and automatically. VA-GAN consists of a texture generator and a differential discriminator that are inter-connected and end-to-end trainable. The differential discriminator guides to learn geometric transformation from background images so that the composed 3D models can be aligned with the background images with realistic poses and views. The texture generator adopts a novel view encoding mechanism for generating accurate object textures for the 3D models under the estimated views. Extensive experiments over two synthesis tasks (car synthesis with KITTI and pedestrian synthesis with Cityscapes) show that VA-GAN achieves high-fidelity composition qualitatively and quantitatively as compared with state-of-the-art generation methods.