 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Early Exit in Reasoning Models
Apr 22, 2025Recent advances in large reasoning language models (LRLMs) rely on test-time scaling, which extends long chain-of-thought (CoT) generation to solve complex tasks. However, overthinking in long CoT not only slows down the efficiency of problem solving, but also risks accuracy loss due to the extremely detailed or redundant reasoning steps. We propose a simple yet effective method that allows LLMs to self-truncate CoT sequences by early exit during generation. Instead of relying on fixed heuristics, the proposed method monitors model behavior at potential reasoning transition points (e.g.,"Wait" tokens) and dynamically terminates the next reasoning chain's generation when the model exhibits high confidence in a trial answer. Our method requires no additional training and can be seamlessly integrated into existing o1-like reasoning LLMs. Experiments on multiple reasoning benchmarks MATH-500, AMC 2023, GPQA Diamond and AIME 2024 show that the proposed method is consistently effective on deepseek-series reasoning LLMs, reducing the length of CoT sequences by an average of 31% to 43% while improving accuracy by 1.7% to 5.7%.
AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding
Mar 16, 2025Multimodal Large Language Models (MLLMs) have revolutionized video understanding, yet are still limited by context length when processing long videos. Recent methods compress videos by leveraging visual redundancy uniformly, yielding promising results. Nevertheless, our quantitative analysis shows that redundancy varies significantly across time and model layers, necessitating a more flexible compression strategy. We propose AdaReTaKe, a training-free method that flexibly reduces visual redundancy by allocating compression ratios among time and layers with theoretical guarantees. Integrated into state-of-the-art MLLMs, AdaReTaKe improves processing capacity from 256 to 2048 frames while preserving critical information. Experiments on VideoMME, MLVU, LongVideoBench, and LVBench datasets demonstrate that AdaReTaKe outperforms existing methods by 2.3% and 2.8% for 7B and 72B models, respectively, with even greater improvements of 5.9% and 6.0% on the longest LVBench. Our code is available at https://github.com/SCZwangxiao/video-FlexReduc.git.
ReTaKe: Reducing Temporal and Knowledge Redundancy for Long Video Understanding
Dec 29, 2024Video Large Language Models (VideoLLMs) have achieved remarkable progress in video understanding. However, existing VideoLLMs often inherit the limitations of their backbone LLMs in handling long sequences, leading to challenges for long video understanding. Common solutions either simply uniformly sample videos' frames or compress visual tokens, which focus primarily on low-level temporal visual redundancy, overlooking high-level knowledge redundancy. This limits the achievable compression rate with minimal loss. To this end. we introduce a training-free method, $\textbf{ReTaKe}$, containing two novel modules DPSelect and PivotKV, to jointly model and reduce both temporal visual redundancy and knowledge redundancy for long video understanding. Specifically, DPSelect identifies keyframes with local maximum peak distance based on their visual features, which are closely aligned with human video perception. PivotKV employs the obtained keyframes as pivots and conducts KV-Cache compression for the non-pivot tokens with low attention scores, which are derived from the learned prior knowledge of LLMs. Experiments on benchmarks VideoMME, MLVU, and LVBench, show that ReTaKe can support 4x longer video sequences with minimal performance loss (<1%) and outperform all similar-size VideoLLMs with 3%-5%, even surpassing or on par with much larger ones. Our code is available at https://github.com/SCZwangxiao/video-ReTaKe
Controlling the Latent Diffusion Model for Generative Image Shadow Removal via Residual Generation
Dec 03, 2024Large-scale generative models have achieved remarkable advancements in various visual tasks, yet their application to shadow removal in images remains challenging. These models often generate diverse, realistic details without adequate focus on fidelity, failing to meet the crucial requirements of shadow removal, which necessitates precise preservation of image content. In contrast to prior approaches that aimed to regenerate shadow-free images from scratch, this paper utilizes diffusion models to generate and refine image residuals. This strategy fully uses the inherent detailed information within shadowed images, resulting in a more efficient and faithful reconstruction of shadow-free content. Additionally, to revent the accumulation of errors during the generation process, a crosstimestep self-enhancement training strategy is proposed. This strategy leverages the network itself to augment the training data, not only increasing the volume of data but also enabling the network to dynamically correct its generation trajectory, ensuring a more accurate and robust output. In addition, to address the loss of original details in the process of image encoding and decoding of large generative models, a content-preserved encoder-decoder structure is designed with a control mechanism and multi-scale skip connections to achieve high-fidelity shadow-free image reconstruction. Experimental results demonstrate that the proposed method can reproduce high-quality results based on a large latent diffusion prior and faithfully preserve the original contents in shadow regions.
Unsupervised convolutional neural network fusion approach for change detection in remote sensing images
Nov 07, 2023



With the rapid development of deep learning, a variety of change detection methods based on deep learning have emerged in recent years. However, these methods usually require a large number of training samples to train the network model, so it is very expensive. In this paper, we introduce a completely unsupervised shallow convolutional neural network (USCNN) fusion approach for change detection. Firstly, the bi-temporal images are transformed into different feature spaces by using convolution kernels of different sizes to extract multi-scale information of the images. Secondly, the output features of bi-temporal images at the same convolution kernels are subtracted to obtain the corresponding difference images, and the difference feature images at the same scale are fused into one feature image by using 1 * 1 convolution layer. Finally, the output features of different scales are concatenated and a 1 * 1 convolution layer is used to fuse the multi-scale information of the image. The model parameters are obtained by a redesigned sparse function. Our model has three features: the entire training process is conducted in an unsupervised manner, the network architecture is shallow, and the objective function is sparse. Thus, it can be seen as a kind of lightweight network model. Experimental results on four real remote sensing datasets indicate the feasibility and effectiveness of the proposed approach.
Superpixel Segmentation Using Gaussian Mixture Model
Feb 21, 2017
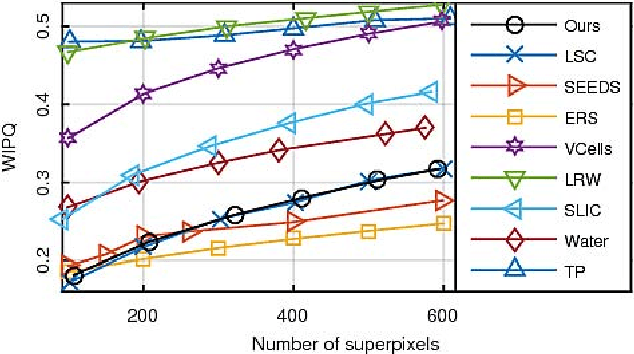


Superpixel segmentation algorithms are to partition an image into perceptually coherence atomic regions by assigning every pixel a superpixel label. Those algorithms have been wildly used as a preprocessing step in computer vision works, as they can enormously reduce the number of entries of subsequent algorithms. In this work, we propose an alternative superpixel segmentation method based on Gaussian mixture model (GMM) by assuming that each superpixel corresponds to a Gaussian distribution, and assuming that each pixel is generated by first randomly choosing one distribution from several Gaussian distributions which are defined to be related to that pixel, and then the pixel is drawn from the selected distribution. Based on this assumption, each pixel is supposed to be drawn from a mixture of Gaussian distributions with unknown parameters (GMM). An algorithm based on expectation-maximization method is applied to estimate the unknown parameters. Once the unknown parameters are obtained, the superpixel label of a pixel is determined by a posterior probability. The success of applying GMM to superpixel segmentation depends on the two major differences between the traditional GMM-based clustering and the proposed one: data points in our model may be non-identically distributed, and we present an approach to control the shape of the estimated Gaussian functions by adjusting their covariance matrices. Our method is of linear complexity with respect to the number of pixels. The proposed algorithm is inherently parallel and can get faster speed by adding simple OpenMP directives to our implementation. According to our experiments, our algorithm outperforms the state-of-the-art superpixel algorithms in accuracy and presents a competitive performance in computational efficiency.