 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalGuard: Conformal Inference under Graph Uncertainty
May 21, 2026Estimating treatment effects from observational data requires choosing an adjustment set, but valid adjustment depends on an unknown causal graph. Graph misspecification can cause under-coverage, while graph-agnostic conformal wrappers may regain nominal coverage only through large padding. We introduce CausalGuard, a structure-weighted conformal framework that calibrates after aggregating graph-conditional doubly robust pseudo-outcomes. Candidate DAGs are proposed from an LLM-derived edge prior, pruned by conditional-independence tests, and reweighted by Bayesian Information Criterion. A composite nonconformity score then calibrates the posterior-weighted pseudo-outcome. CausalGuard provides distribution-free finite-sample marginal coverage for this aggregated pseudo-outcome; under causal identification, overlap, conditional-mean nuisance stability, and concentration on target-aligned valid adjustment strategies, its conditional mean converges to the true Conditional Average Treatment Effect. Across five benchmarks, CausalGuard attains mean coverage above the nominal 90% level for the directly evaluable target and reduces width when graph-agnostic conformal baselines require large padding. Stress tests show that CausalGuard suppresses invalid collider adjustment and remains stable under misspecified priors when the retained candidate set is data-supported.
Overcoming Dynamics-Blindness: Training-Free Pace-and-Path Correction for VLA Models
May 14, 2026Vision-Language-Action (VLA) models achieve remarkable flexibility and generalization beyond classical control paradigms. However, most prevailing VLAs are trained under a single-frame observation paradigm, which leaves them structurally blind to temporal dynamics. Consequently, these models degrade severely in non-stationary scenarios, even when trained or finetuned on dynamic datasets. Existing approaches either require expensive retraining or suffer from latency bottlenecks and poor temporal consistency across action chunks. We propose Pace-and-Path Correction, a training-free, closed-form inference-time operator that wraps any chunked-action VLA. From a single quadratic cost, joint minimization yields a unified solution that decomposes orthogonally into two distinct channels. The pace channel compresses execution along the planned direction, while the path channel applies an orthogonal spatial offset, jointly absorbing the perceived dynamics within the chunk window. We evaluate our approach on a comprehensive diagnostic benchmark MoveBench designed to isolate motion as the sole controlled variable. Empirical results demonstrate that our framework consistently outperforms state-of-the-art training-free wrappers and dynamic-adaptive methods and improves success rates by up to 28.8% and 25.9% in absolute terms over foundational VLA models in dynamic-only and static-dynamic mixed environments, respectively.
A Novel Correlation-optimized Deep Learning Method for Wind Speed Forecast
Jun 09, 2023


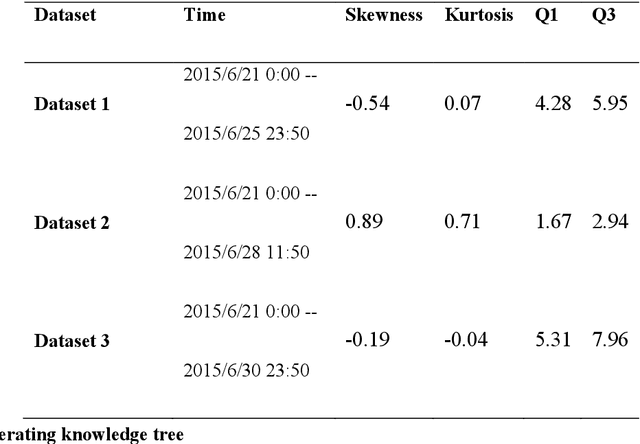
The increasing installation rate of wind power poses great challenges to the global power system. In order to ensure the reliable operation of the power system, it is necessary to accurately forecast the wind speed and power of the wind turbines. At present, deep learning is progressively applied to the wind speed prediction. Nevertheless, the recent deep learning methods still reflect the embarrassment for practical applications due to model interpretability and hardware limitation. To this end, a novel deep knowledge-based learning method is proposed in this paper. The proposed method hybridizes pre-training method and auto-encoder structure to improve data representation and modeling of the deep knowledge-based learning framework. In order to form knowledge and corresponding absorbers, the original data is preprocessed by an optimization model based on correlation to construct multi-layer networks (knowledge) which are absorbed by sequence to sequence (Seq2Seq) models. Specifically, new cognition and memory units (CMU) are designed to reinforce traditional deep learning framework. Finally, the effectiveness of the proposed method is verified by three wind prediction cases from a wind farm in Liaoning, China. Experimental results show that the proposed method increases the stability and training efficiency compared to the traditional LSTM method and LSTM/GRU-based Seq2Seq method for applications of wind speed forecasting.
Attenuating Random Noise in Seismic Data by a Deep Learning Approach
Oct 28, 2019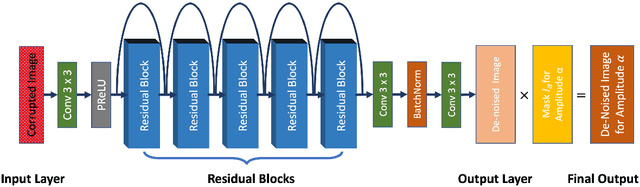
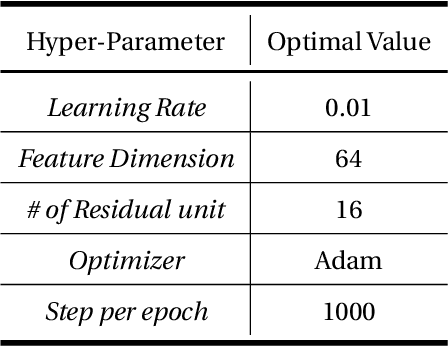
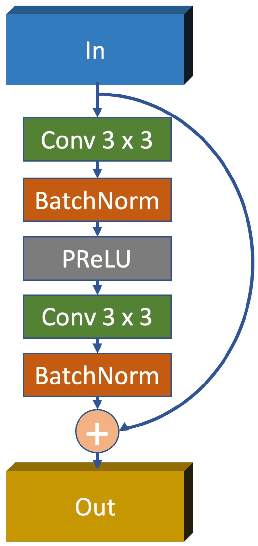
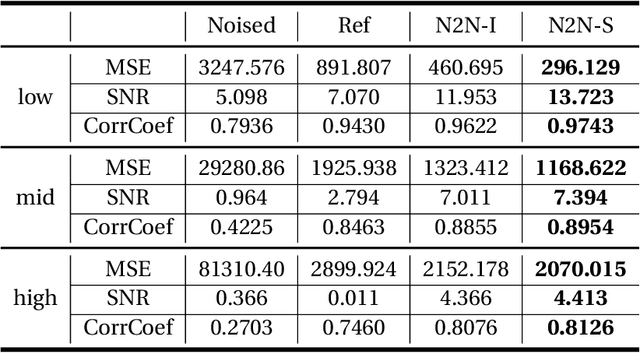
In the geophysical field, seismic noise attenuation has been considered as a critical and long-standing problem, especially for the pre-stack data processing. Here, we propose a model to leverage the deep-learning model for this task. Rather than directly applying an existing de-noising model from ordinary images to the seismic data, we have designed a particular deep-learning model, based on residual neural networks. It is named as N2N-Seismic, which has a strong ability to recover the seismic signals back to intact condition with the preservation of primary signals. The proposed model, achieving with great success in attenuating noise, has been tested on two different seismic datasets. Several metrics show that our method outperforms conventional approaches in terms of Signal-to-Noise-Ratio, Mean-Squared-Error, Phase Spectrum, etc. Moreover, robust tests in terms of effectively removing random noise from any dataset with strong and weak noises have been extensively scrutinized in making sure that the proposed model is able to maintain a good level of adaptation while dealing with large variations of noise characteristics and intensities.
Enhanced Seismic Imaging with Predictive Neural Networks for Geophysics
Aug 11, 2019
We propose a predictive neural network architecture that can be utilized to update reference velocity models as inputs to full waveform inversion. Deep learning models are explored to augment velocity model building workflows during 3D seismic volume reprocessing in salt-prone environments. Specifically, a neural network architecture, with 3D convolutional, de-convolutional layers, and 3D max-pooling, is designed to take standard amplitude 3D seismic volumes as an input. Enhanced data augmentations through generative adversarial networks and a weighted loss function enable the network to train with few sparsely annotated slices. Batch normalization is also applied for faster convergence. Moreover, a 3D probability cube for salt bodies is generated through ensembles of predictions from multiple models in order to reduce variance. Velocity models inferred from the proposed networks provide opportunities for FWI forward models to converge faster with an initial condition closer to the true model. In each iteration step, the probability cubes of salt bodies inferred from the proposed networks can be used as a regularization term in FWI forward modelling, which may result in an improved velocity model estimation while the output of seismic migration can be utilized as an input of the 3D neural network for subsequent iterations.