 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Nuisance to News Sense: Augmenting the News with Cross-Document Evidence and Context
Oct 06, 2023Reading and understanding the stories in the news is increasingly difficult. Reporting on stories evolves rapidly, politicized news venues offer different perspectives (and sometimes different facts), and misinformation is rampant. However, existing solutions merely aggregate an overwhelming amount of information from heterogenous sources, such as different news outlets, social media, and news bias rating agencies. We present NEWSSENSE, a novel sensemaking tool and reading interface designed to collect and integrate information from multiple news articles on a central topic, using a form of reference-free fact verification. NEWSSENSE augments a central, grounding article of the user's choice by linking it to related articles from different sources, providing inline highlights on how specific claims in the chosen article are either supported or contradicted by information from other articles. Using NEWSSENSE, users can seamlessly digest and cross-check multiple information sources without disturbing their natural reading flow. Our pilot study shows that NEWSSENSE has the potential to help users identify key information, verify the credibility of news articles, and explore different perspectives.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023

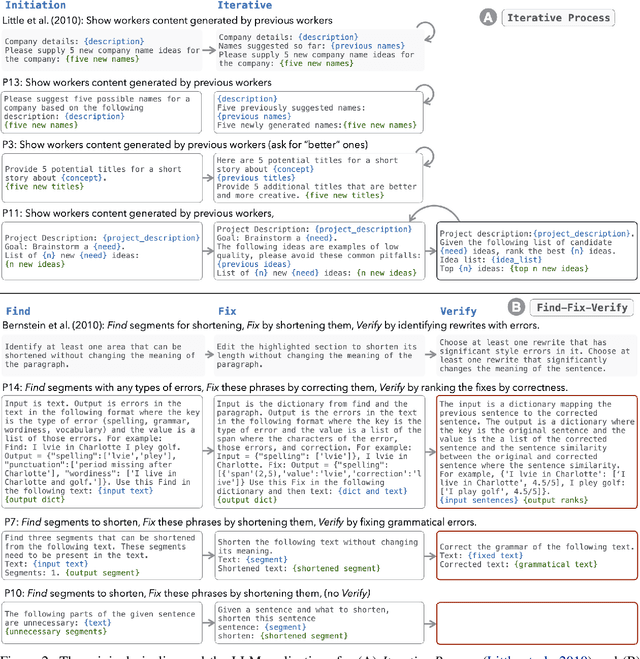
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.