 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEB: In Search of the Best Evaluation Approach for Synthetic Time Series
May 27, 2025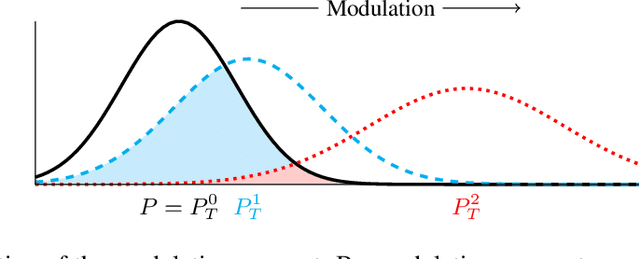
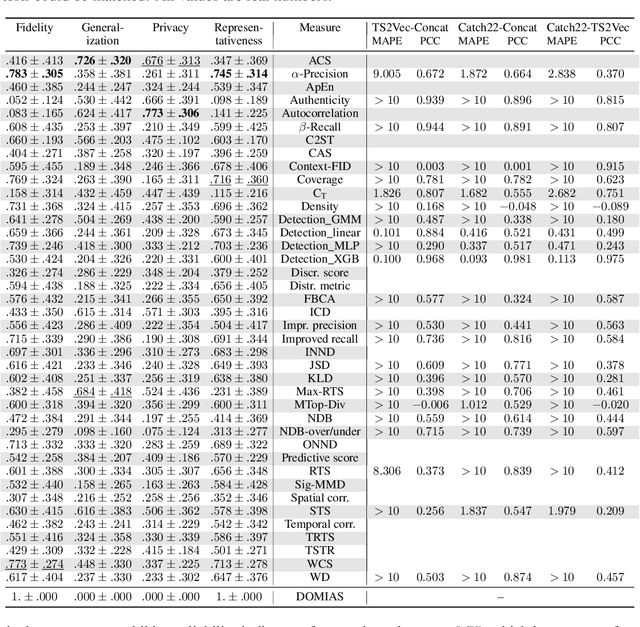
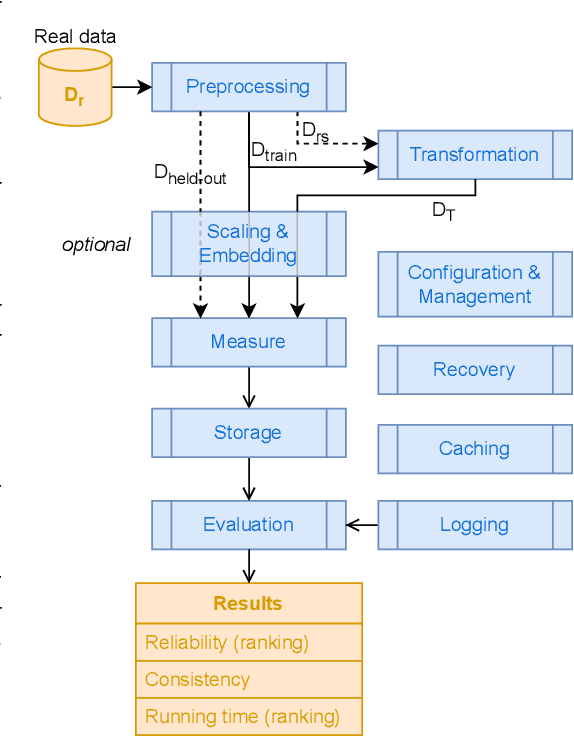
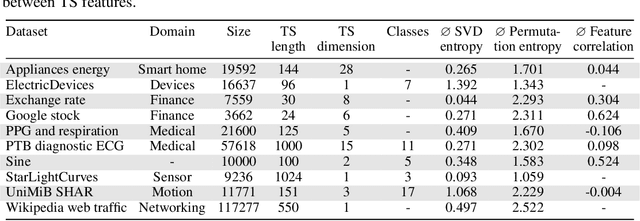
The growing need for synthetic time series, due to data augmentation or privacy regulations, has led to numerous generative models, frameworks, and evaluation measures alike. Objectively comparing these measures on a large scale remains an open challenge. We propose the Synthetic Time series Evaluation Benchmark (STEB) -- the first benchmark framework that enables comprehensive and interpretable automated comparisons of synthetic time series evaluation measures. Using 10 diverse datasets, randomness injection, and 13 configurable data transformations, STEB computes indicators for measure reliability and score consistency. It tracks running time, test errors, and features sequential and parallel modes of operation. In our experiments, we determine a ranking of 41 measures from literature and confirm that the choice of upstream time series embedding heavily impacts the final score.
TSRM: A Lightweight Temporal Feature Encoding Architecture for Time Series Forecasting and Imputation
Apr 26, 2025



We introduce a temporal feature encoding architecture called Time Series Representation Model (TSRM) for multivariate time series forecasting and imputation. The architecture is structured around CNN-based representation layers, each dedicated to an independent representation learning task and designed to capture diverse temporal patterns, followed by an attention-based feature extraction layer and a merge layer, designed to aggregate extracted features. The architecture is fundamentally based on a configuration that is inspired by a Transformer encoder, with self-attention mechanisms at its core. The TSRM architecture outperforms state-of-the-art approaches on most of the seven established benchmark datasets considered in our empirical evaluation for both forecasting and imputation tasks. At the same time, it significantly reduces complexity in the form of learnable parameters. The source code is available at https://github.com/RobertLeppich/TSRM.
Time Series Representation Models
May 28, 2024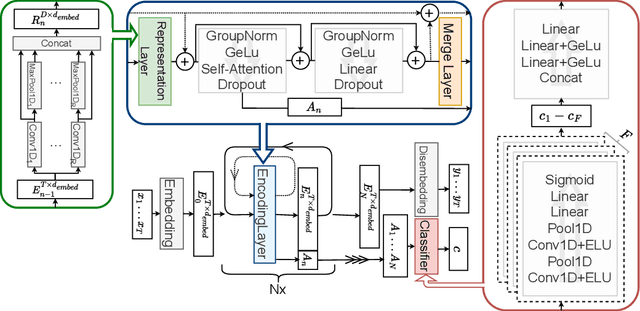



Time series analysis remains a major challenge due to its sparse characteristics, high dimensionality, and inconsistent data quality. Recent advancements in transformer-based techniques have enhanced capabilities in forecasting and imputation; however, these methods are still resource-heavy, lack adaptability, and face difficulties in integrating both local and global attributes of time series. To tackle these challenges, we propose a new architectural concept for time series analysis based on introspection. Central to this concept is the self-supervised pretraining of Time Series Representation Models (TSRMs), which once learned can be easily tailored and fine-tuned for specific tasks, such as forecasting and imputation, in an automated and resource-efficient manner. Our architecture is equipped with a flexible and hierarchical representation learning process, which is robust against missing data and outliers. It can capture and learn both local and global features of the structure, semantics, and crucial patterns of a given time series category, such as heart rate data. Our learned time series representation models can be efficiently adapted to a specific task, such as forecasting or imputation, without manual intervention. Furthermore, our architecture's design supports explainability by highlighting the significance of each input value for the task at hand. Our empirical study using four benchmark datasets shows that, compared to investigated state-of-the-art baseline methods, our architecture improves imputation and forecasting errors by up to 90.34% and 71.54%, respectively, while reducing the required trainable parameters by up to 92.43%. The source code is available at https://github.com/RobertLeppich/TSRM.
Comprehensive Exploration of Synthetic Data Generation: A Survey
Jan 04, 2024Recent years have witnessed a surge in the popularity of Machine Learning (ML), applied across diverse domains. However, progress is impeded by the scarcity of training data due to expensive acquisition and privacy legislation. Synthetic data emerges as a solution, but the abundance of released models and limited overview literature pose challenges for decision-making. This work surveys 417 Synthetic Data Generation (SDG) models over the last decade, providing a comprehensive overview of model types, functionality, and improvements. Common attributes are identified, leading to a classification and trend analysis. The findings reveal increased model performance and complexity, with neural network-based approaches prevailing, except for privacy-preserving data generation. Computer vision dominates, with GANs as primary generative models, while diffusion models, transformers, and RNNs compete. Implications from our performance evaluation highlight the scarcity of common metrics and datasets, making comparisons challenging. Additionally, the neglect of training and computational costs in literature necessitates attention in future research. This work serves as a guide for SDG model selection and identifies crucial areas for future exploration.
Telescope: An Automated Hybrid Forecasting Approach on a Level-Playing Field
Sep 26, 2023


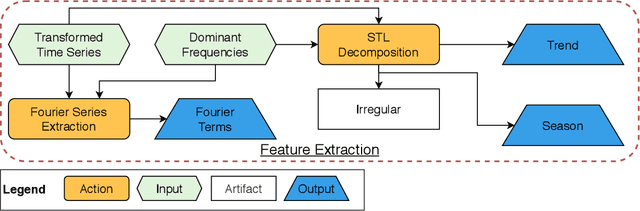
In many areas of decision-making, forecasting is an essential pillar. Consequently, many different forecasting methods have been proposed. From our experience, recently presented forecasting methods are computationally intensive, poorly automated, tailored to a particular data set, or they lack a predictable time-to-result. To this end, we introduce Telescope, a novel machine learning-based forecasting approach that automatically retrieves relevant information from a given time series and splits it into parts, handling each of them separately. In contrast to deep learning methods, our approach doesn't require parameterization or the need to train and fit a multitude of parameters. It operates with just one time series and provides forecasts within seconds without any additional setup. Our experiments show that Telescope outperforms recent methods by providing accurate and reliable forecasts while making no assumptions about the analyzed time series.