 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre General-Purpose Vision Models All We Need for 2D Medical Image Segmentation? A Cross-Dataset Empirical Study
Mar 13, 2026Medical image segmentation (MIS) is a fundamental component of computer-assisted diagnosis and clinical decision support systems. Over the past decade, numerous architectures specifically tailored to medical imaging have emerged to address domain-specific challenges such as low contrast, small anatomical structures, and limited annotated data. In parallel, rapid progress in computer vision has produced highly capable general-purpose vision models (GP-VMs) originally designed for natural images. Despite their strong performance on standard vision benchmarks, their effectiveness for MIS remains insufficiently understood. In this work, we conduct a controlled empirical study to examine whether specialized medical segmentation architectures (SMAs) provide systematic advantages over modern GP-VMs for 2D MIS. We compare eleven SMAs and GP-VMs using a unified training and evaluation protocol. Experiments are performed across three heterogeneous datasets covering different imaging modalities, class structures, and data characteristics. Beyond segmentation accuracy, we analyze qualitative Grad-CAM visualizations to investigate explainability (XAI) behavior. Our results demonstrate that, for the analyzed datasets, GP-VMs out-perform the majority of specialized MIS models. Moreover, XAI analyses indicate that GP-VMs can capture clinically relevant structures without explicit domain-specific architectural design. These findings suggest that GP-VMs can represent a viable alternative to domain-specific methods, highlighting the importance of informed model selection for end-to-end MIS systems. All code and resources are available at GitHub.
WoundAIssist: A Patient-Centered Mobile App for AI-Assisted Wound Care With Physicians in the Loop
Jun 06, 2025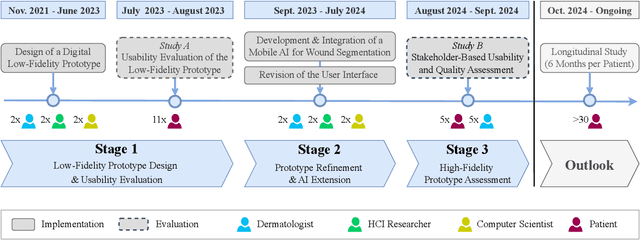
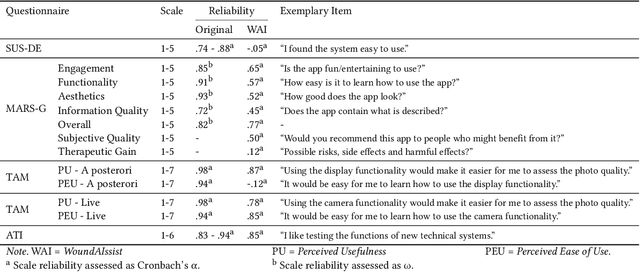
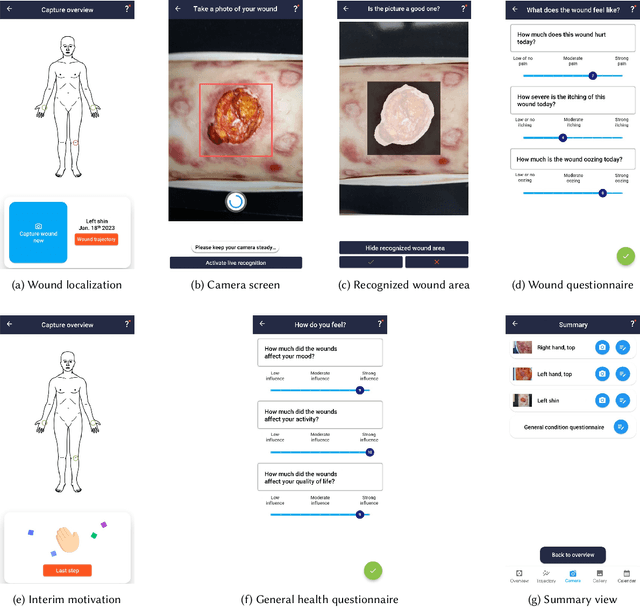
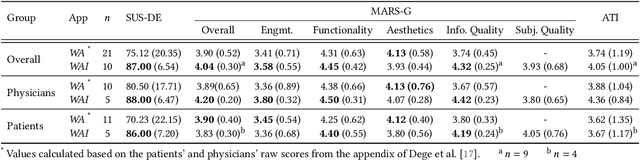
The rising prevalence of chronic wounds, especially in aging populations, presents a significant healthcare challenge due to prolonged hospitalizations, elevated costs, and reduced patient quality of life. Traditional wound care is resource-intensive, requiring frequent in-person visits that strain both patients and healthcare professionals (HCPs). Therefore, we present WoundAIssist, a patient-centered, AI-driven mobile application designed to support telemedical wound care. WoundAIssist enables patients to regularly document wounds at home via photographs and questionnaires, while physicians remain actively engaged in the care process through remote monitoring and video consultations. A distinguishing feature is an integrated lightweight deep learning model for on-device wound segmentation, which, combined with patient-reported data, enables continuous monitoring of wound healing progression. Developed through an iterative, user-centered process involving both patients and domain experts, WoundAIssist prioritizes an user-friendly design, particularly for elderly patients. A conclusive usability study with patients and dermatologists reported excellent usability, good app quality, and favorable perceptions of the AI-driven wound recognition. Our main contribution is two-fold: (I) the implementation and (II) evaluation of WoundAIssist, an easy-to-use yet comprehensive telehealth solution designed to bridge the gap between patients and HCPs. Additionally, we synthesize design insights for remote patient monitoring apps, derived from over three years of interdisciplinary research, that may inform the development of similar digital health tools across clinical domains.
STEB: In Search of the Best Evaluation Approach for Synthetic Time Series
May 27, 2025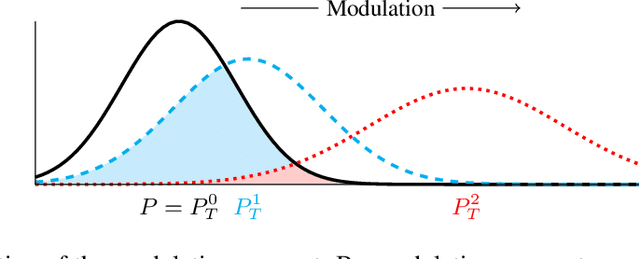
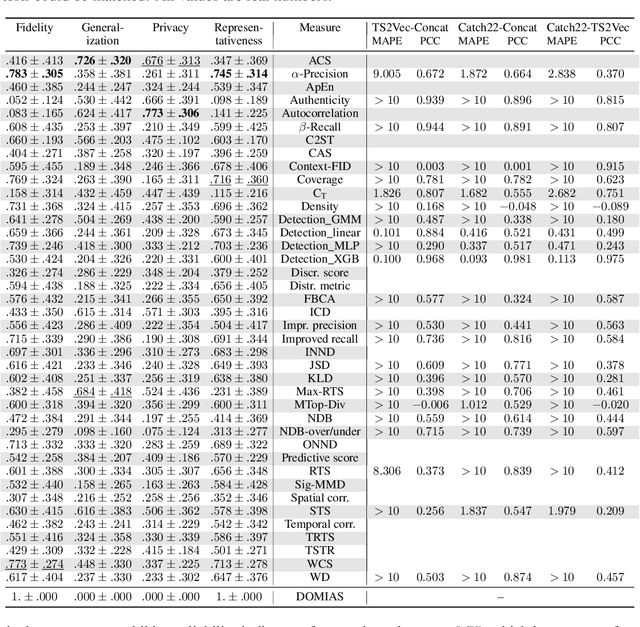
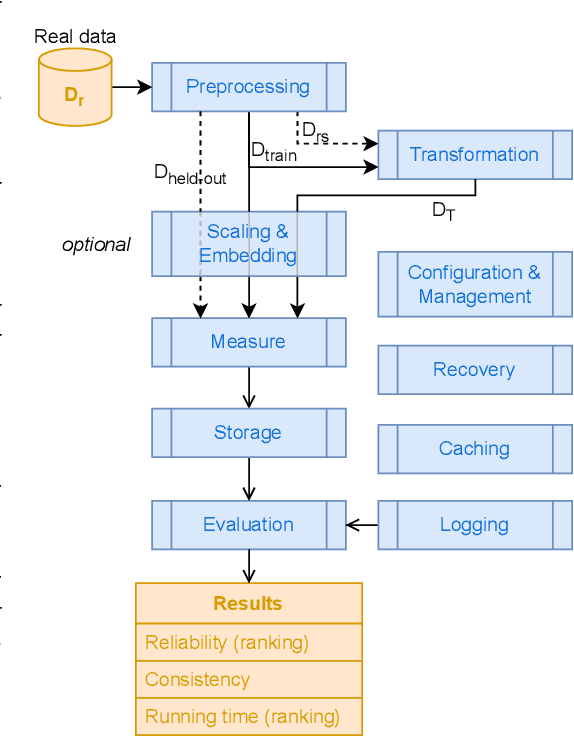
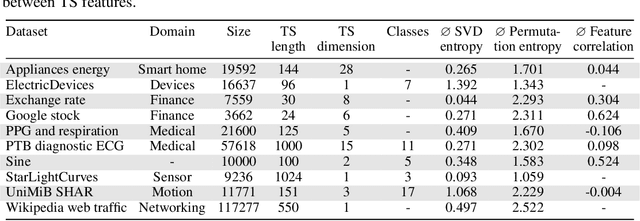
The growing need for synthetic time series, due to data augmentation or privacy regulations, has led to numerous generative models, frameworks, and evaluation measures alike. Objectively comparing these measures on a large scale remains an open challenge. We propose the Synthetic Time series Evaluation Benchmark (STEB) -- the first benchmark framework that enables comprehensive and interpretable automated comparisons of synthetic time series evaluation measures. Using 10 diverse datasets, randomness injection, and 13 configurable data transformations, STEB computes indicators for measure reliability and score consistency. It tracks running time, test errors, and features sequential and parallel modes of operation. In our experiments, we determine a ranking of 41 measures from literature and confirm that the choice of upstream time series embedding heavily impacts the final score.
TSRM: A Lightweight Temporal Feature Encoding Architecture for Time Series Forecasting and Imputation
Apr 26, 2025



We introduce a temporal feature encoding architecture called Time Series Representation Model (TSRM) for multivariate time series forecasting and imputation. The architecture is structured around CNN-based representation layers, each dedicated to an independent representation learning task and designed to capture diverse temporal patterns, followed by an attention-based feature extraction layer and a merge layer, designed to aggregate extracted features. The architecture is fundamentally based on a configuration that is inspired by a Transformer encoder, with self-attention mechanisms at its core. The TSRM architecture outperforms state-of-the-art approaches on most of the seven established benchmark datasets considered in our empirical evaluation for both forecasting and imputation tasks. At the same time, it significantly reduces complexity in the form of learnable parameters. The source code is available at https://github.com/RobertLeppich/TSRM.
WoundAmbit: Bridging State-of-the-Art Semantic Segmentation and Real-World Wound Care
Apr 08, 2025



Chronic wounds affect a large population, particularly the elderly and diabetic patients, who often exhibit limited mobility and co-existing health conditions. Automated wound monitoring via mobile image capture can reduce in-person physician visits by enabling remote tracking of wound size. Semantic segmentation is key to this process, yet wound segmentation remains underrepresented in medical imaging research. To address this, we benchmark state-of-the-art deep learning models from general-purpose vision, medical imaging, and top methods from public wound challenges. For fair comparison, we standardize training, data augmentation, and evaluation, conducting cross-validationto minimize partitioning bias. We also assess real-world deployment aspects, including generalization to an out-of-distribution wound dataset, computational efficiency, and interpretability. Additionally, we propose a reference object-based approach to convert AI-generated masks into clinically relevant wound size estimates, and evaluate this, along with mask quality, for the best models based on physician assessments. Overall, the transformer-based TransNeXt showed the highest levels of generalizability. Despite variations in inference times, all models processed at least one image per second on the CPU, which is deemed adequate for the intended application. Interpretability analysis typically revealed prominent activations in wound regions, emphasizing focus on clinically relevant features. Expert evaluation showed high mask approval for all analyzed models, with VWFormer and ConvNeXtS backbone performing the best. Size retrieval accuracy was similar across models, and predictions closely matched expert annotations. Finally, we demonstrate how our AI-driven wound size estimation framework, WoundAmbit, can be integrated into a custom telehealth system. Our code will be made available on GitHub upon publication.
Early Explorations of Lightweight Models for Wound Segmentation on Mobile Devices
Jul 11, 2024The aging population poses numerous challenges to healthcare, including the increase in chronic wounds in the elderly. The current approach to wound assessment by therapists based on photographic documentation is subjective, highlighting the need for computer-aided wound recognition from smartphone photos. This offers objective and convenient therapy monitoring, while being accessible to patients from their home at any time. However, despite research in mobile image segmentation, there is a lack of focus on mobile wound segmentation. To address this gap, we conduct initial research on three lightweight architectures to investigate their suitability for smartphone-based wound segmentation. Using public datasets and UNet as a baseline, our results are promising, with both ENet and TopFormer, as well as the larger UNeXt variant, showing comparable performance to UNet. Furthermore, we deploy the models into a smartphone app for visual assessment of live segmentation, where results demonstrate the effectiveness of TopFormer in distinguishing wounds from wound-coloured objects. While our study highlights the potential of transformer models for mobile wound segmentation, future work should aim to further improve the mask contours.
Time Series Representation Models
May 28, 2024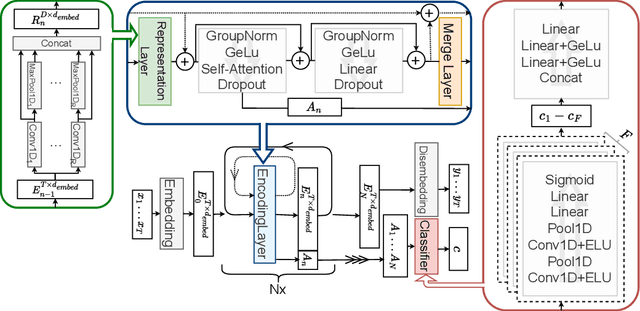



Time series analysis remains a major challenge due to its sparse characteristics, high dimensionality, and inconsistent data quality. Recent advancements in transformer-based techniques have enhanced capabilities in forecasting and imputation; however, these methods are still resource-heavy, lack adaptability, and face difficulties in integrating both local and global attributes of time series. To tackle these challenges, we propose a new architectural concept for time series analysis based on introspection. Central to this concept is the self-supervised pretraining of Time Series Representation Models (TSRMs), which once learned can be easily tailored and fine-tuned for specific tasks, such as forecasting and imputation, in an automated and resource-efficient manner. Our architecture is equipped with a flexible and hierarchical representation learning process, which is robust against missing data and outliers. It can capture and learn both local and global features of the structure, semantics, and crucial patterns of a given time series category, such as heart rate data. Our learned time series representation models can be efficiently adapted to a specific task, such as forecasting or imputation, without manual intervention. Furthermore, our architecture's design supports explainability by highlighting the significance of each input value for the task at hand. Our empirical study using four benchmark datasets shows that, compared to investigated state-of-the-art baseline methods, our architecture improves imputation and forecasting errors by up to 90.34% and 71.54%, respectively, while reducing the required trainable parameters by up to 92.43%. The source code is available at https://github.com/RobertLeppich/TSRM.
Comprehensive Exploration of Synthetic Data Generation: A Survey
Jan 04, 2024Recent years have witnessed a surge in the popularity of Machine Learning (ML), applied across diverse domains. However, progress is impeded by the scarcity of training data due to expensive acquisition and privacy legislation. Synthetic data emerges as a solution, but the abundance of released models and limited overview literature pose challenges for decision-making. This work surveys 417 Synthetic Data Generation (SDG) models over the last decade, providing a comprehensive overview of model types, functionality, and improvements. Common attributes are identified, leading to a classification and trend analysis. The findings reveal increased model performance and complexity, with neural network-based approaches prevailing, except for privacy-preserving data generation. Computer vision dominates, with GANs as primary generative models, while diffusion models, transformers, and RNNs compete. Implications from our performance evaluation highlight the scarcity of common metrics and datasets, making comparisons challenging. Additionally, the neglect of training and computational costs in literature necessitates attention in future research. This work serves as a guide for SDG model selection and identifies crucial areas for future exploration.
Telescope: An Automated Hybrid Forecasting Approach on a Level-Playing Field
Sep 26, 2023


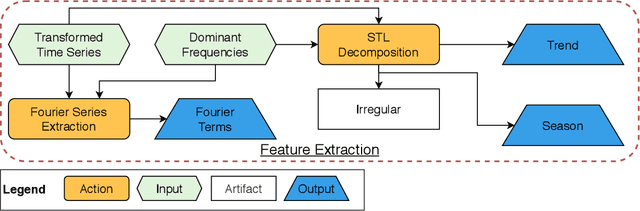
In many areas of decision-making, forecasting is an essential pillar. Consequently, many different forecasting methods have been proposed. From our experience, recently presented forecasting methods are computationally intensive, poorly automated, tailored to a particular data set, or they lack a predictable time-to-result. To this end, we introduce Telescope, a novel machine learning-based forecasting approach that automatically retrieves relevant information from a given time series and splits it into parts, handling each of them separately. In contrast to deep learning methods, our approach doesn't require parameterization or the need to train and fit a multitude of parameters. It operates with just one time series and provides forecasts within seconds without any additional setup. Our experiments show that Telescope outperforms recent methods by providing accurate and reliable forecasts while making no assumptions about the analyzed time series.
A Case Study of Vehicle Route Optimization
Nov 17, 2021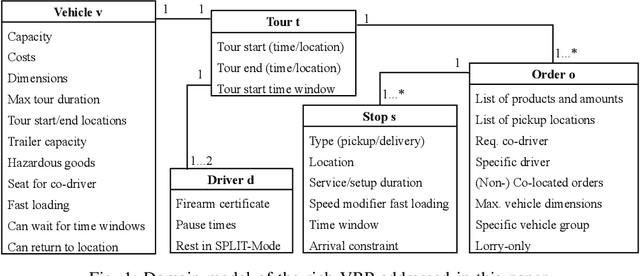
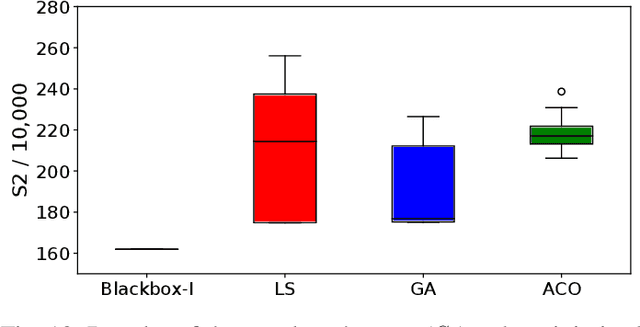


In the last decades, the classical Vehicle Routing Problem (VRP), i.e., assigning a set of orders to vehicles and planning their routes has been intensively researched. As only the assignment of order to vehicles and their routes is already an NP-complete problem, the application of these algorithms in practice often fails to take into account the constraints and restrictions that apply in real-world applications, the so called rich VRP (rVRP) and are limited to single aspects. In this work, we incorporate the main relevant real-world constraints and requirements. We propose a two-stage strategy and a Timeline algorithm for time windows and pause times, and apply a Genetic Algorithm (GA) and Ant Colony Optimization (ACO) individually to the problem to find optimal solutions. Our evaluation of eight different problem instances against four state-of-the-art algorithms shows that our approach handles all given constraints in a reasonable time.