 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Explain't: A Post-Mortem on Semantic Interpretability in Transformer Models
Jan 30, 2026Large Language Models (LLMs) are becoming increasingly popular in pervasive computing due to their versatility and strong performance. However, despite their ubiquitous use, the exact mechanisms underlying their outstanding performance remain unclear. Different methods for LLM explainability exist, and many are, as a method, not fully understood themselves. We started with the question of how linguistic abstraction emerges in LLMs, aiming to detect it across different LLM modules (attention heads and input embeddings). For this, we used methods well-established in the literature: (1) probing for token-level relational structures, and (2) feature-mapping using embeddings as carriers of human-interpretable properties. Both attempts failed for different methodological reasons: Attention-based explanations collapsed once we tested the core assumption that later-layer representations still correspond to tokens. Property-inference methods applied to embeddings also failed because their high predictive scores were driven by methodological artifacts and dataset structure rather than meaningful semantic knowledge. These failures matter because both techniques are widely treated as evidence for what LLMs supposedly understand, yet our results show such conclusions are unwarranted. These limitations are particularly relevant in pervasive and distributed computing settings where LLMs are deployed as system components and interpretability methods are relied upon for debugging, compression, and explaining models.
SoK: Towards Security and Safety of Edge AI
Oct 07, 2024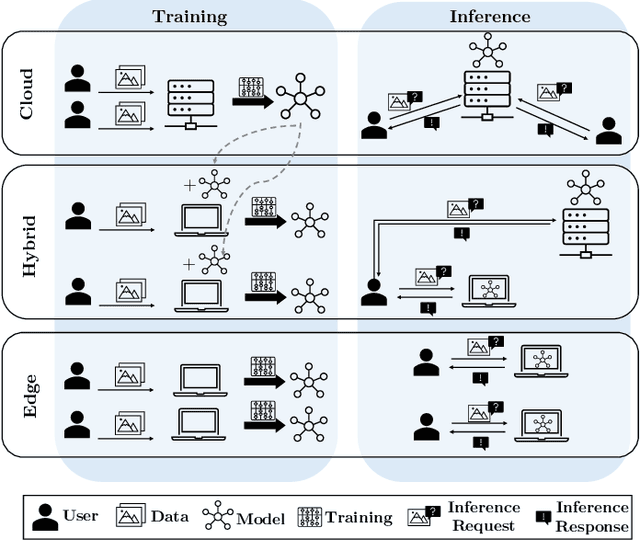
Advanced AI applications have become increasingly available to a broad audience, e.g., as centrally managed large language models (LLMs). Such centralization is both a risk and a performance bottleneck - Edge AI promises to be a solution to these problems. However, its decentralized approach raises additional challenges regarding security and safety. In this paper, we argue that both of these aspects are critical for Edge AI, and even more so, their integration. Concretely, we survey security and safety threats, summarize existing countermeasures, and collect open challenges as a call for more research in this area.
A Survey on Predictive Maintenance for Industry 4.0
Feb 05, 2020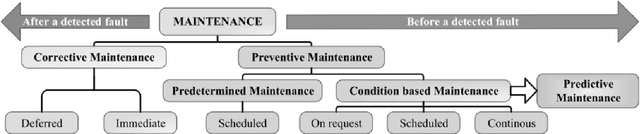
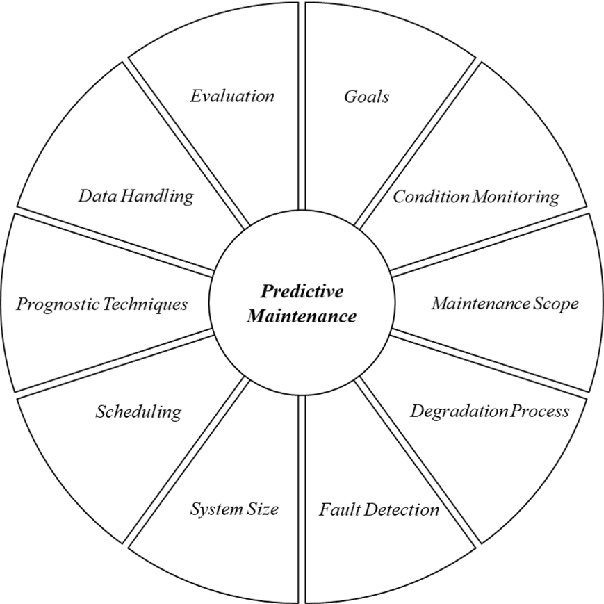
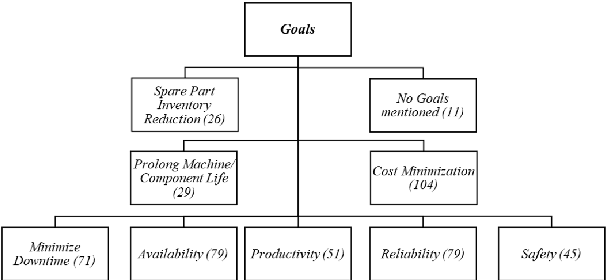
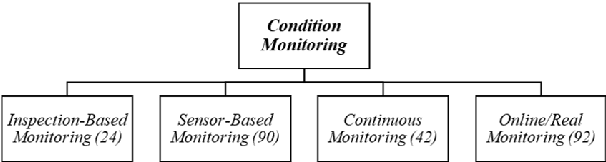
Production issues at Volkswagen in 2016 lead to dramatic losses in sales of up to 400 million Euros per week. This example shows the huge financial impact of a working production facility for companies. Especially in the data-driven domains of Industry 4.0 and Industrial IoT with intelligent, connected machines, a conventional, static maintenance schedule seems to be old-fashioned. In this paper, we present a survey on the current state of the art in predictive maintenance for Industry 4.0. Based on a structured literate survey, we present a classification of predictive maintenance in the context of Industry 4.0 and discuss recent developments in this area.