 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Towards Security and Safety of Edge AI
Oct 07, 2024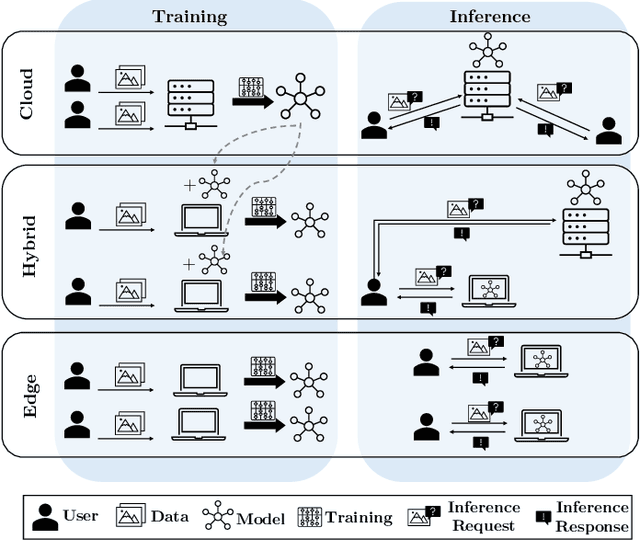
Advanced AI applications have become increasingly available to a broad audience, e.g., as centrally managed large language models (LLMs). Such centralization is both a risk and a performance bottleneck - Edge AI promises to be a solution to these problems. However, its decentralized approach raises additional challenges regarding security and safety. In this paper, we argue that both of these aspects are critical for Edge AI, and even more so, their integration. Concretely, we survey security and safety threats, summarize existing countermeasures, and collect open challenges as a call for more research in this area.
Efficient Approximate Recovery from Pooled Data Using Doubly Regular Pooling Schemes
Feb 28, 2023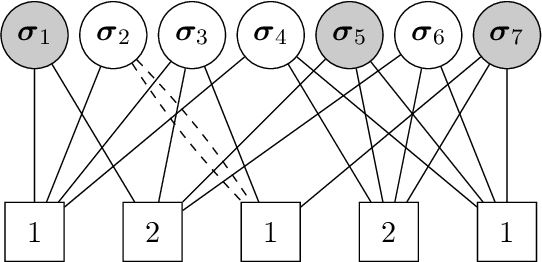
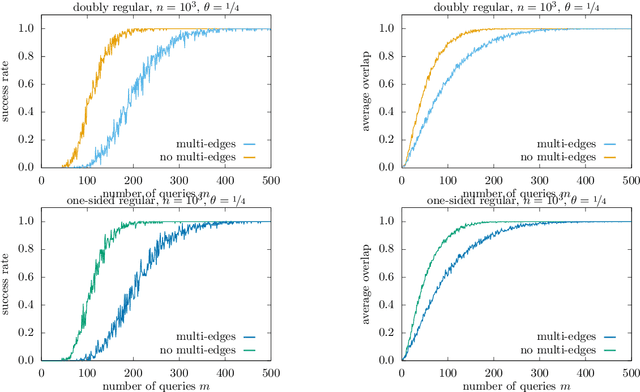
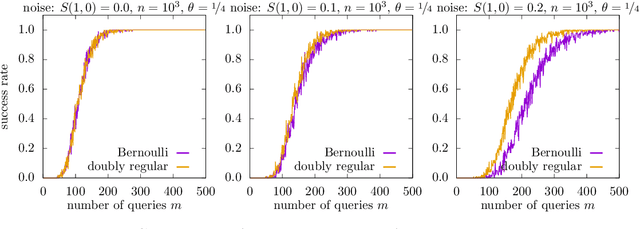
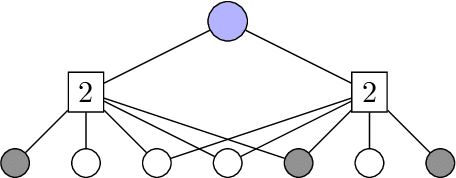
In the pooled data problem we are given $n$ agents with hidden state bits, either $0$ or $1$. The hidden states are unknown and can be seen as the underlying ground truth $\sigma$. To uncover that ground truth, we are given a querying method that queries multiple agents at a time. Each query reports the sum of the states of the queried agents. Our goal is to learn the hidden state bits using as few queries as possible. So far, most literature deals with exact reconstruction of all hidden state bits. We study a more relaxed variant in which we allow a small fraction of agents to be classified incorrectly. This becomes particularly relevant in the noisy variant of the pooled data problem where the queries' results are subject to random noise. In this setting, we provide a doubly regular test design that assigns agents to queries. For this design we analyze an approximate reconstruction algorithm that estimates the hidden bits in a greedy fashion. We give a rigorous analysis of the algorithm's performance, its error probability, and its approximation quality. As a main technical novelty, our analysis is uniform in the degree of noise and the sparsity of $\sigma$. Finally, simulations back up our theoretical findings and provide strong empirical evidence that our algorithm works well for realistic sample sizes.
Inference of a Rumor's Source in the Independent Cascade Model
May 24, 2022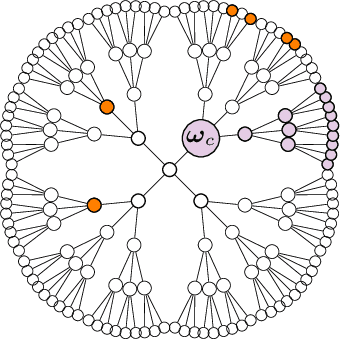
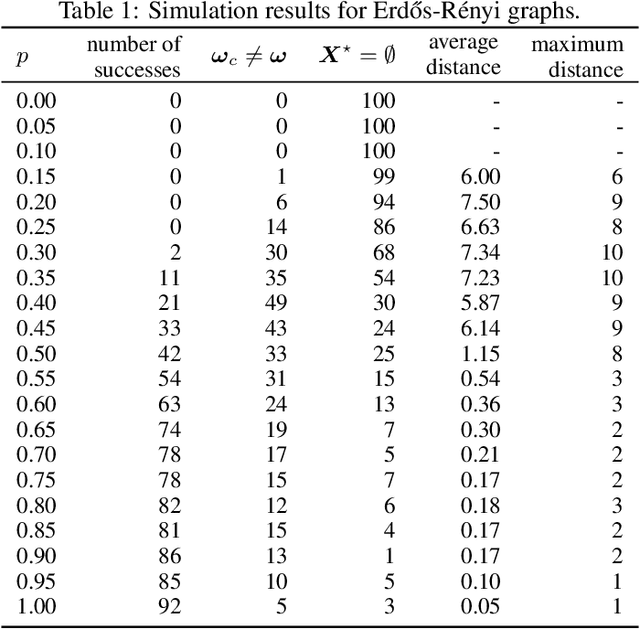
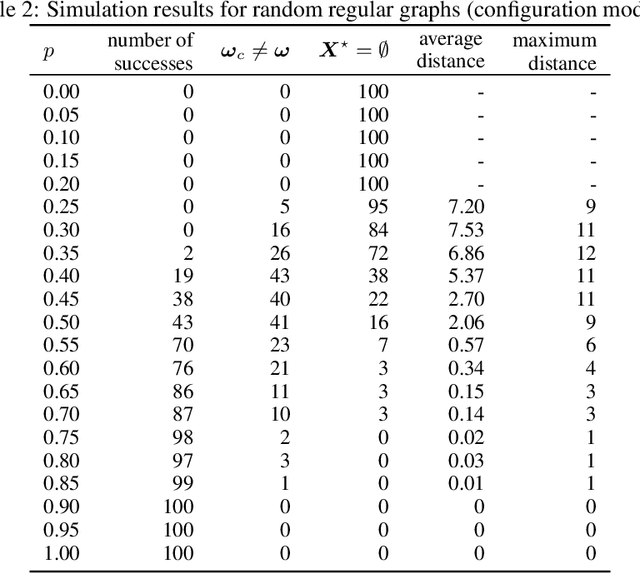
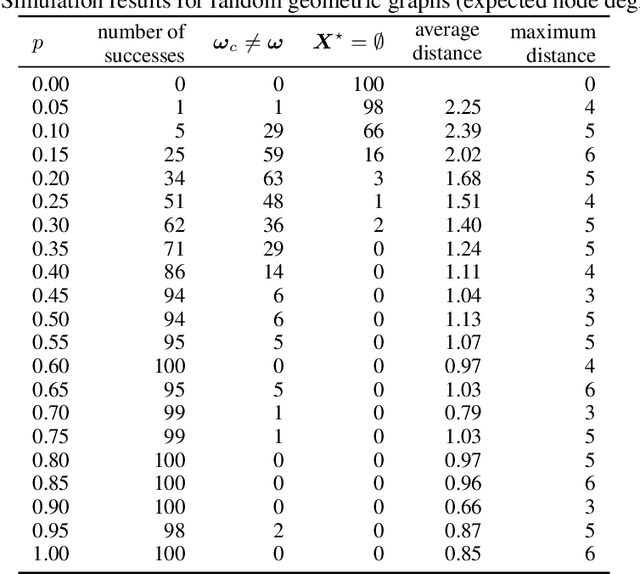
We consider the so-called Independent Cascade Model for rumor spreading or epidemic processes popularized by Kempe et al.\ [2003]. In this model, a small subset of nodes from a network are the source of a rumor. In discrete time steps, each informed node "infects" each of its uninformed neighbors with probability $p$. While many facets of this process are studied in the literature, less is known about the inference problem: given a number of infected nodes in a network, can we learn the source of the rumor? In the context of epidemiology this problem is often referred to as patient zero problem. It belongs to a broader class of problems where the goal is to infer parameters of the underlying spreading model, see, e.g., Lokhov [NeurIPS'16] or Mastakouri et al. [NeurIPS'20]. In this work we present a maximum likelihood estimator for the rumor's source, given a snapshot of the process in terms of a set of active nodes $X$ after $t$ steps. Our results show that, for cycle-free graphs, the likelihood estimator undergoes a non-trivial phase transition as a function $t$. We provide a rigorous analysis for two prominent classes of acyclic network, namely $d$-regular trees and Galton-Watson trees, and verify empirically that our heuristics work well in various general networks.
Distributed Reconstruction of Noisy Pooled Data
Apr 14, 2022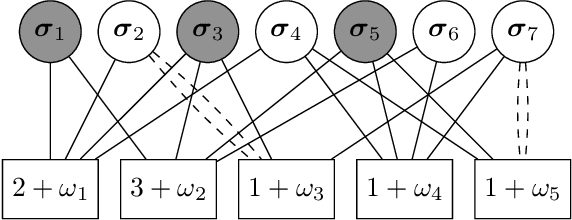
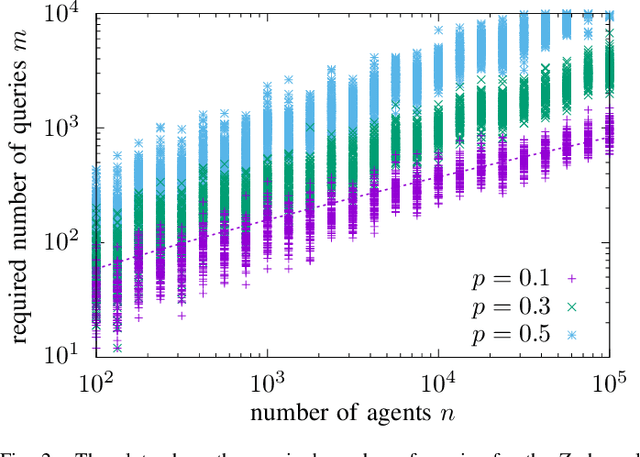
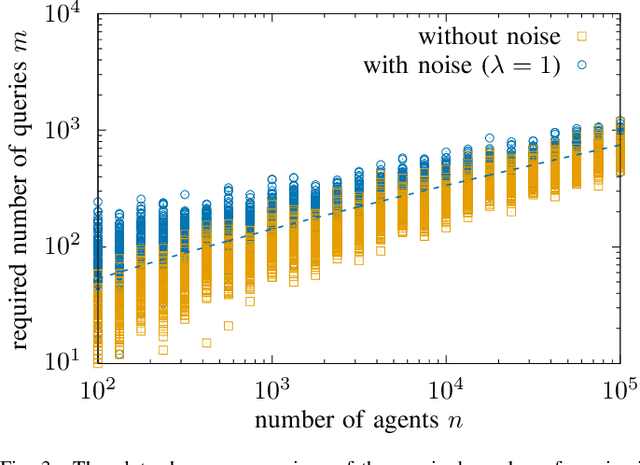
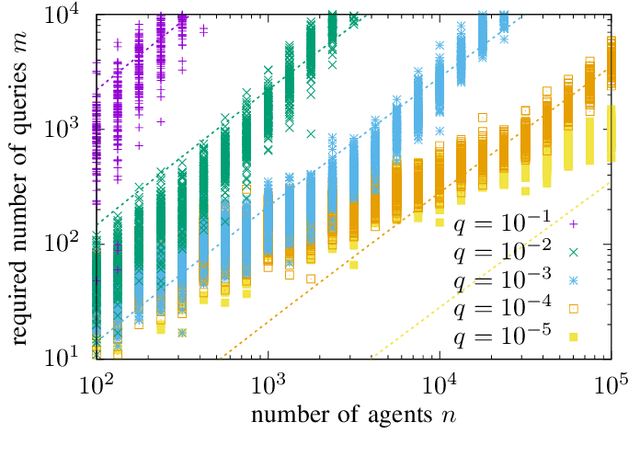
In the pooled data problem we are given a set of $n$ agents, each of which holds a hidden state bit, either $0$ or $1$. A querying procedure returns for a query set the sum of the states of the queried agents. The goal is to reconstruct the states using as few queries as possible. In this paper we consider two noise models for the pooled data problem. In the noisy channel model, the result for each agent flips with a certain probability. In the noisy query model, each query result is subject to random Gaussian noise. Our results are twofold. First, we present and analyze for both error models a simple and efficient distributed algorithm that reconstructs the initial states in a greedy fashion. Our novel analysis pins down the range of error probabilities and distributions for which our algorithm reconstructs the exact initial states with high probability. Secondly, we present simulation results of our algorithm and compare its performance with approximate message passing (AMP) algorithms that are conjectured to be optimal in a number of related problems.