 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Lightweight Weed Detection via Knowledge Distillation
Jul 16, 2025
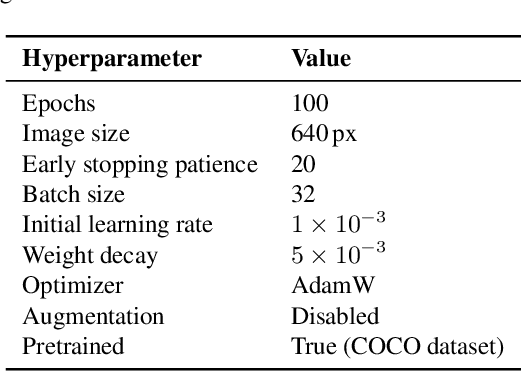
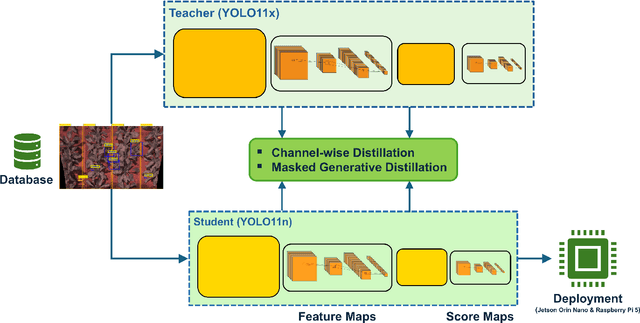
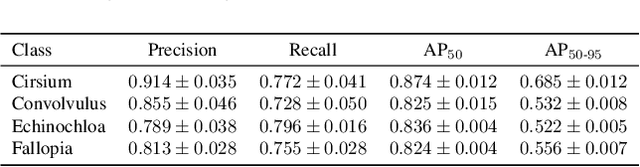
Weed detection is a critical component of precision agriculture, facilitating targeted herbicide application and reducing environmental impact. However, deploying accurate object detection models on resource-limited platforms remains challenging, particularly when differentiating visually similar weed species commonly encountered in plant phenotyping applications. In this work, we investigate Channel-wise Knowledge Distillation (CWD) and Masked Generative Distillation (MGD) to enhance the performance of lightweight models for real-time smart spraying systems. Utilizing YOLO11x as the teacher model and YOLO11n as both reference and student, both CWD and MGD effectively transfer knowledge from the teacher to the student model. Our experiments, conducted on a real-world dataset comprising sugar beet crops and four weed types (Cirsium, Convolvulus, Fallopia, and Echinochloa), consistently show increased AP50 across all classes. The distilled CWD student model achieves a notable improvement of 2.5% and MGD achieves 1.9% in mAP50 over the baseline without increasing model complexity. Additionally, we validate real-time deployment feasibility by evaluating the student YOLO11n model on Jetson Orin Nano and Raspberry Pi 5 embedded devices, performing five independent runs to evaluate performance stability across random seeds. These findings confirm CWD and MGD as an effective, efficient, and practical approach for improving deep learning-based weed detection accuracy in precision agriculture and plant phenotyping scenarios.
Exploring Model Quantization in GenAI-based Image Inpainting and Detection of Arable Plants
Mar 04, 2025


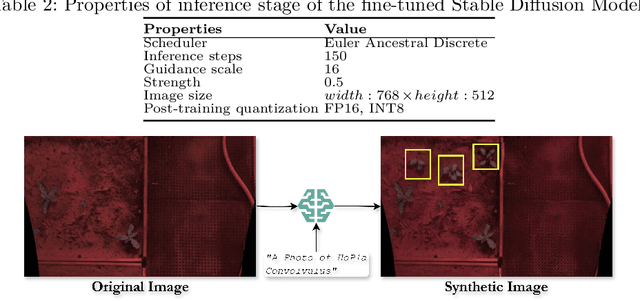
Deep learning-based weed control systems often suffer from limited training data diversity and constrained on-board computation, impacting their real-world performance. To overcome these challenges, we propose a framework that leverages Stable Diffusion-based inpainting to augment training data progressively in 10% increments -- up to an additional 200%, thus enhancing both the volume and diversity of samples. Our approach is evaluated on two state-of-the-art object detection models, YOLO11(l) and RT-DETR(l), using the mAP50 metric to assess detection performance. We explore quantization strategies (FP16 and INT8) for both the generative inpainting and detection models to strike a balance between inference speed and accuracy. Deployment of the downstream models on the Jetson Orin Nano demonstrates the practical viability of our framework in resource-constrained environments, ultimately improving detection accuracy and computational efficiency in intelligent weed management systems.
Assessing the Capability of YOLO- and Transformer-based Object Detectors for Real-time Weed Detection
Jan 30, 2025
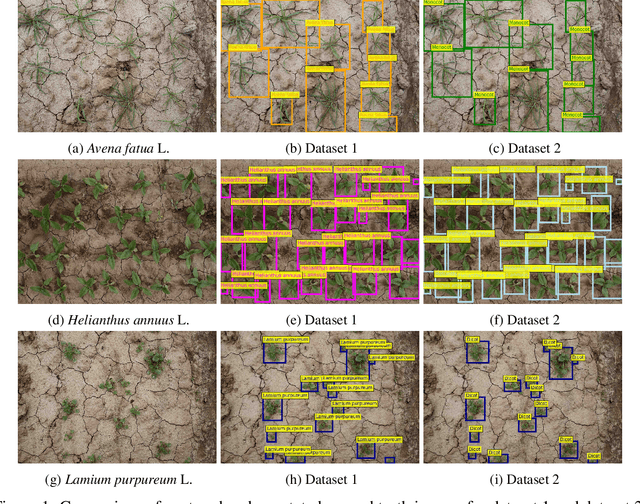
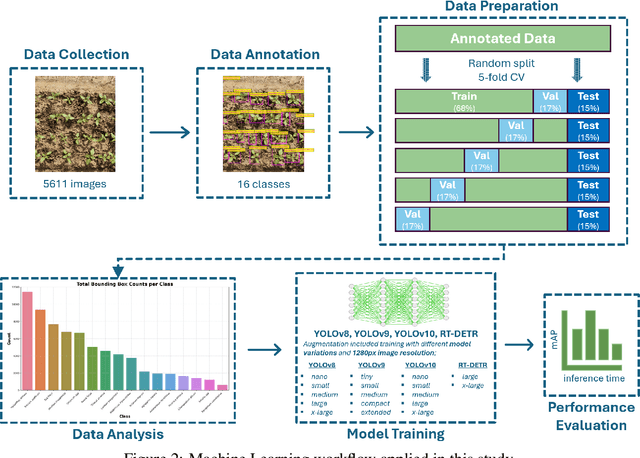
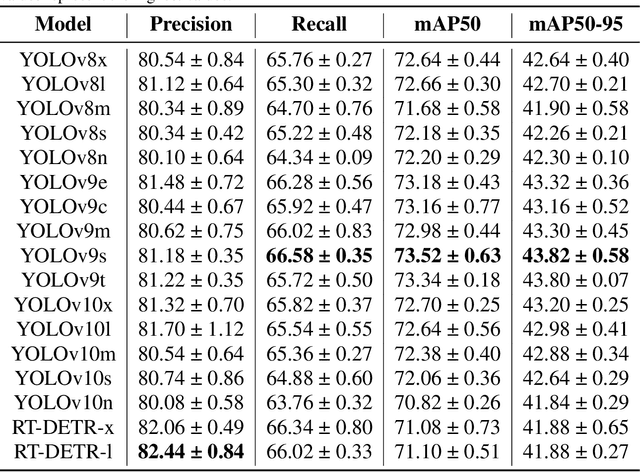
Spot spraying represents an efficient and sustainable method for reducing the amount of pesticides, particularly herbicides, used in agricultural fields. To achieve this, it is of utmost importance to reliably differentiate between crops and weeds, and even between individual weed species in situ and under real-time conditions. To assess suitability for real-time application, different object detection models that are currently state-of-the-art are compared. All available models of YOLOv8, YOLOv9, YOLOv10, and RT-DETR are trained and evaluated with images from a real field situation. The images are separated into two distinct datasets: In the initial data set, each species of plants is trained individually; in the subsequent dataset, a distinction is made between monocotyledonous weeds, dicotyledonous weeds, and three chosen crops. The results demonstrate that while all models perform equally well in the metrics evaluated, the YOLOv9 models, particularly the YOLOv9s and YOLOv9e, stand out in terms of their strong recall scores (66.58 % and 72.36 %), as well as mAP50 (73.52 % and 79.86 %), and mAP50-95 (43.82 % and 47.00 %) in dataset 2. However, the RT-DETR models, especially RT-DETR-l, excel in precision with reaching 82.44 \% on dataset 1 and 81.46 % in dataset 2, making them particularly suitable for scenarios where minimizing false positives is critical. In particular, the smallest variants of the YOLO models (YOLOv8n, YOLOv9t, and YOLOv10n) achieve substantially faster inference times down to 7.58 ms for dataset 2 on the NVIDIA GeForce RTX 4090 GPU for analyzing one frame, while maintaining competitive accuracy, highlighting their potential for deployment in resource-constrained embedded computing devices as typically used in productive setups.
Comparative Analysis of YOLOv9, YOLOv10 and RT-DETR for Real-Time Weed Detection
Dec 18, 2024

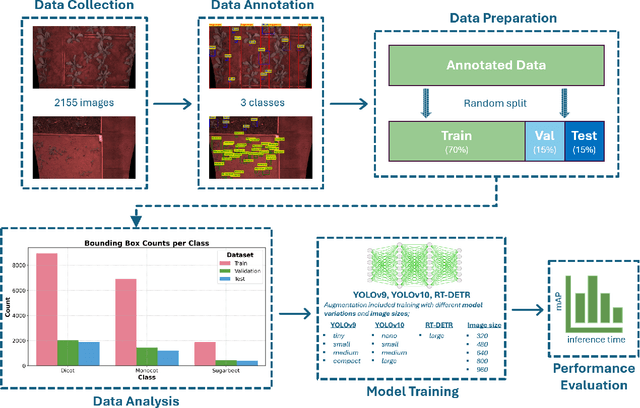
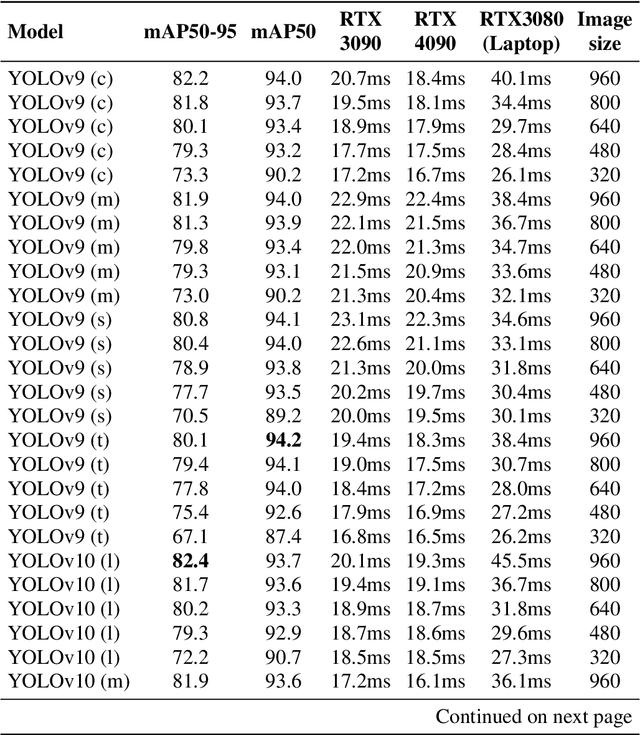
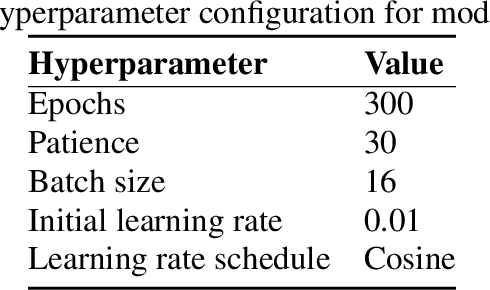
This paper presents a comprehensive evaluation of state-of-the-art object detection models, including YOLOv9, YOLOv10, and RT-DETR, for the task of weed detection in smart-spraying applications focusing on three classes: Sugarbeet, Monocot, and Dicot. The performance of these models is compared based on mean Average Precision (mAP) scores and inference times on different GPU devices. We consider various model variations, such as nano, small, medium, large alongside different image resolutions (320px, 480px, 640px, 800px, 960px). The results highlight the trade-offs between inference time and detection accuracy, providing valuable insights for selecting the most suitable model for real-time weed detection. This study aims to guide the development of efficient and effective smart spraying systems, enhancing agricultural productivity through precise weed management.
Excretion Detection in Pigsties Using Convolutional and Transformerbased Deep Neural Networks
Nov 29, 2024



Animal excretions in form of urine puddles and feces are a significant source of emissions in livestock farming. Automated detection of soiled floor in barns can contribute to improved management processes but also the derived information can be used to model emission dynamics. Previous research approaches to determine the puddle area require manual detection of the puddle in the barn. While humans can detect animal excretions on thermal images of a livestock barn, automated approaches using thresholds fail due to other objects of the same temperature, such as the animals themselves. In addition, various parameters such as the type of housing, animal species, age, sex, weather and unknown factors can influence the type and shape of excretions. Due to this heterogeneity, a method for automated detection of excretions must therefore be not only be accurate but also robust to varying conditions. These requirements can be met by using contemporary deep learning models from the field of artificial intelligence. This work is the first to investigate the suitability of different deep learning models for the detection of excretions in pigsties, thereby comparing established convolutional architectures with recent transformer-based approaches. The detection models Faster R-CNN, YOLOv8, DETR and DAB-DETR are compared and statistically assessed on two created training datasets representing two pig houses. We apply a method derived from nested cross-validation and report on the results in terms of eight common detection metrics. Our work demonstrates that all investigated deep learning models are generally suitable for reliably detecting excretions with an average precision of over 90%. The models also show robustness on out of distribution data that possesses differences from the conditions in the training data, however, with expected slight decreases in the overall detection performance.
Enhancing weed detection performance by means of GenAI-based image augmentation
Nov 28, 2024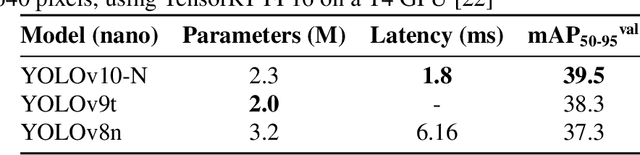


Precise weed management is essential for sustaining crop productivity and ecological balance. Traditional herbicide applications face economic and environmental challenges, emphasizing the need for intelligent weed control systems powered by deep learning. These systems require vast amounts of high-quality training data. The reality of scarcity of well-annotated training data, however, is often addressed through generating more data using data augmentation. Nevertheless, conventional augmentation techniques such as random flipping, color changes, and blurring lack sufficient fidelity and diversity. This paper investigates a generative AI-based augmentation technique that uses the Stable Diffusion model to produce diverse synthetic images that improve the quantity and quality of training datasets for weed detection models. Moreover, this paper explores the impact of these synthetic images on the performance of real-time detection systems, thus focusing on compact CNN-based models such as YOLO nano for edge devices. The experimental results show substantial improvements in mean Average Precision (mAP50 and mAP50-95) scores for YOLO models trained with generative AI-augmented datasets, demonstrating the promising potential of synthetic data to enhance model robustness and accuracy.
Generative AI-based Pipeline Architecture for Increasing Training Efficiency in Intelligent Weed Control Systems
Nov 01, 2024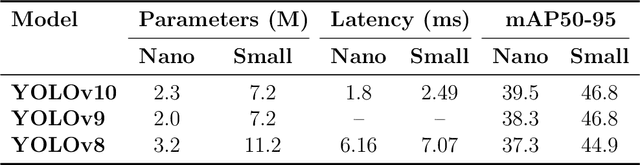
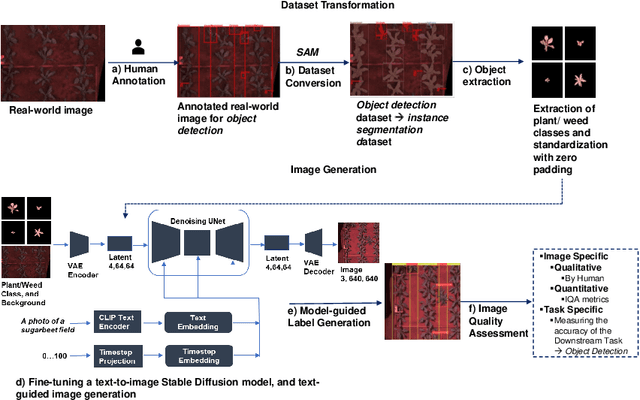

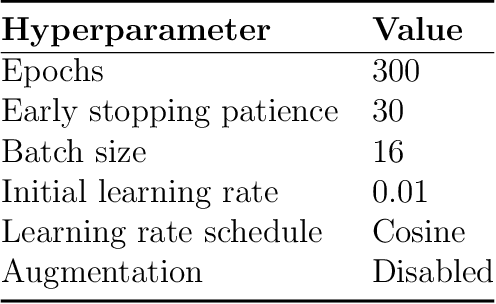
In automated crop protection tasks such as weed control, disease diagnosis, and pest monitoring, deep learning has demonstrated significant potential. However, these advanced models rely heavily on high-quality, diverse datasets, often limited and costly in agricultural settings. Traditional data augmentation can increase dataset volume but usually lacks the real-world variability needed for robust training. This study presents a new approach for generating synthetic images to improve deep learning-based object detection models for intelligent weed control. Our GenAI-based image generation pipeline integrates the Segment Anything Model (SAM) for zero-shot domain adaptation with a text-to-image Stable Diffusion Model, enabling the creation of synthetic images that capture diverse real-world conditions. We evaluate these synthetic datasets using lightweight YOLO models, measuring data efficiency with mAP50 and mAP50-95 scores across varying proportions of real and synthetic data. Notably, YOLO models trained on datasets with 10% synthetic and 90% real images generally demonstrate superior mAP50 and mAP50-95 scores compared to those trained solely on real images. This approach not only reduces dependence on extensive real-world datasets but also enhances predictive performance. The integration of this approach opens opportunities for achieving continual self-improvement of perception modules in intelligent technical systems.
A Case Study of Vehicle Route Optimization
Nov 17, 2021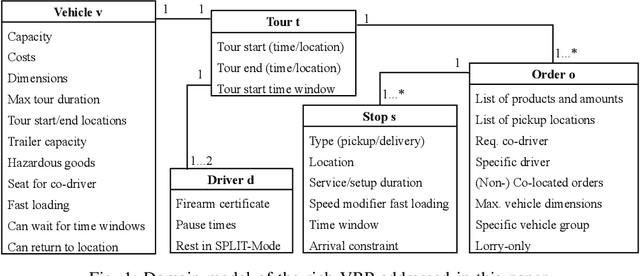
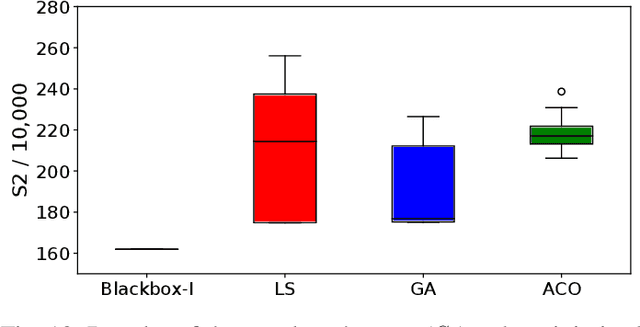


In the last decades, the classical Vehicle Routing Problem (VRP), i.e., assigning a set of orders to vehicles and planning their routes has been intensively researched. As only the assignment of order to vehicles and their routes is already an NP-complete problem, the application of these algorithms in practice often fails to take into account the constraints and restrictions that apply in real-world applications, the so called rich VRP (rVRP) and are limited to single aspects. In this work, we incorporate the main relevant real-world constraints and requirements. We propose a two-stage strategy and a Timeline algorithm for time windows and pause times, and apply a Genetic Algorithm (GA) and Ant Colony Optimization (ACO) individually to the problem to find optimal solutions. Our evaluation of eight different problem instances against four state-of-the-art algorithms shows that our approach handles all given constraints in a reasonable time.
XCS Classifier System with Experience Replay
Feb 13, 2020



XCS constitutes the most deeply investigated classifier system today. It bears strong potentials and comes with inherent capabilities for mastering a variety of different learning tasks. Besides outstanding successes in various classification and regression tasks, XCS also proved very effective in certain multi-step environments from the domain of reinforcement learning. Especially in the latter domain, recent advances have been mainly driven by algorithms which model their policies based on deep neural networks -- among which the Deep-Q-Network (DQN) is a prominent representative. Experience Replay (ER) constitutes one of the crucial factors for the DQN's successes, since it facilitates stabilized training of the neural network-based Q-function approximators. Surprisingly, XCS barely takes advantage of similar mechanisms that leverage stored raw experiences encountered so far. To bridge this gap, this paper investigates the benefits of extending XCS with ER. On the one hand, we demonstrate that for single-step tasks ER bears massive potential for improvements in terms of sample efficiency. On the shady side, however, we reveal that the use of ER might further aggravate well-studied issues not yet solved for XCS when applied to sequential decision problems demanding for long-action-chains.
Bootstrapping a DQN Replay Memory with Synthetic Experiences
Feb 04, 2020



An important component of many Deep Reinforcement Learning algorithms is the Experience Replay which serves as a storage mechanism or memory of made experiences. These experiences are used for training and help the agent to stably find the perfect trajectory through the problem space. The classic Experience Replay however makes only use of the experiences it actually made, but the stored samples bear great potential in form of knowledge about the problem that can be extracted. We present an algorithm that creates synthetic experiences in a nondeterministic discrete environment to assist the learner. The Interpolated Experience Replay is evaluated on the FrozenLake environment and we show that it can support the agent to learn faster and even better than the classic version.