 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Optimal Anytime Algorithms via Bayesian Racing
Mar 09, 2026Selecting an optimization algorithm requires comparing candidates across problem instances, but the computational budget for deployment is often unknown at benchmarking time. Current methods either collapse anytime performance into a scalar, require manual interpretation of plots, or produce conclusions that change when algorithms are added or removed. Moreover, methods based on raw objective values require normalization, which needs bounds or optima that are often unavailable and breaks coherent aggregation across instances. We propose a framework that formulates anytime algorithm comparison as Pareto optimization over time: an algorithm is non-dominated if no competitor beats it at every timepoint. By using rankings rather than objective values, our approach requires no bounds, no normalization, and aggregates coherently across arbitrary instance distributions without requiring known optima. We introduce PolarBear (Pareto-optimal anytime algorithms via Bayesian racing), a procedure that identifies the anytime Pareto set through adaptive sampling with calibrated uncertainty. Bayesian inference over a temporal Plackett-Luce ranking model provides posterior beliefs about pairwise dominance, enabling early elimination of confidently dominated algorithms. The output Pareto set together with the posterior supports downstream algorithm selection under arbitrary time preferences and risk profiles without additional experiments.
HOIverse: A Synthetic Scene Graph Dataset With Human Object Interactions
Jun 24, 2025When humans and robotic agents coexist in an environment, scene understanding becomes crucial for the agents to carry out various downstream tasks like navigation and planning. Hence, an agent must be capable of localizing and identifying actions performed by the human. Current research lacks reliable datasets for performing scene understanding within indoor environments where humans are also a part of the scene. Scene Graphs enable us to generate a structured representation of a scene or an image to perform visual scene understanding. To tackle this, we present HOIverse a synthetic dataset at the intersection of scene graph and human-object interaction, consisting of accurate and dense relationship ground truths between humans and surrounding objects along with corresponding RGB images, segmentation masks, depth images and human keypoints. We compute parametric relations between various pairs of objects and human-object pairs, resulting in an accurate and unambiguous relation definitions. In addition, we benchmark our dataset on state-of-the-art scene graph generation models to predict parametric relations and human-object interactions. Through this dataset, we aim to accelerate research in the field of scene understanding involving people.
Analysing the Influence of Reorder Strategies for Cartesian Genetic Programming
Oct 01, 2024
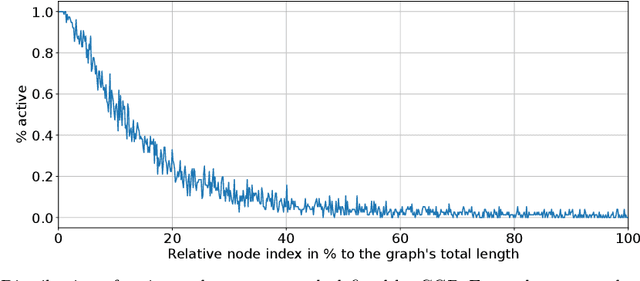

Cartesian Genetic Programming (CGP) suffers from a specific limitation: Positional bias, a phenomenon in which mostly genes at the start of the genome contribute to a program output, while genes at the end rarely do. This can lead to an overall worse performance of CGP. One solution to overcome positional bias is to introduce reordering methods, which shuffle the current genotype without changing its corresponding phenotype. There are currently two different reorder operators that extend the classic CGP formula and improve its fitness value. In this work, we discuss possible shortcomings of these two existing operators. Afterwards, we introduce three novel operators which reorder the genotype of a graph defined by CGP. We show empirically on four Boolean and four symbolic regression benchmarks that the number of iterations until a solution is found and/or the fitness value improves by using CGP with a reorder method. However, there is no consistently best performing reorder operator. Furthermore, their behaviour is analysed by investigating their convergence plots and we show that all behave the same in terms of convergence type.
PDPK: A Framework to Synthesise Process Data and Corresponding Procedural Knowledge for Manufacturing
Aug 16, 2023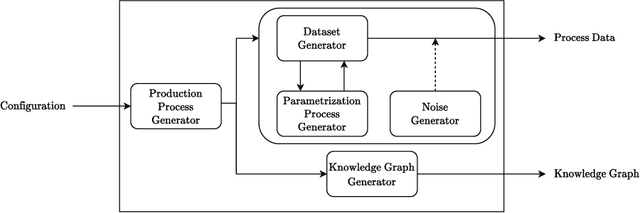
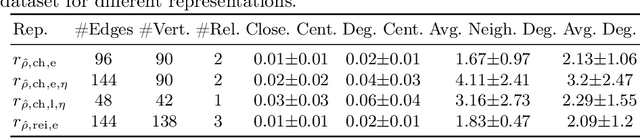
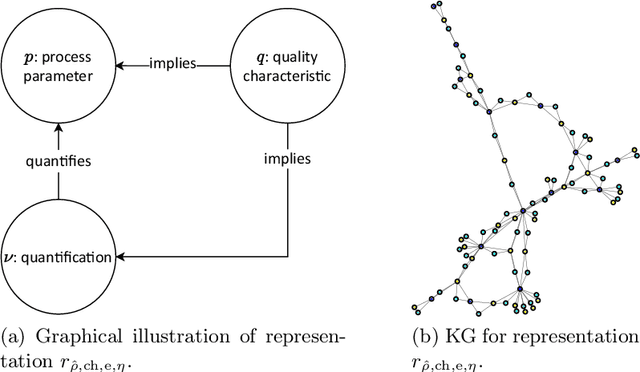
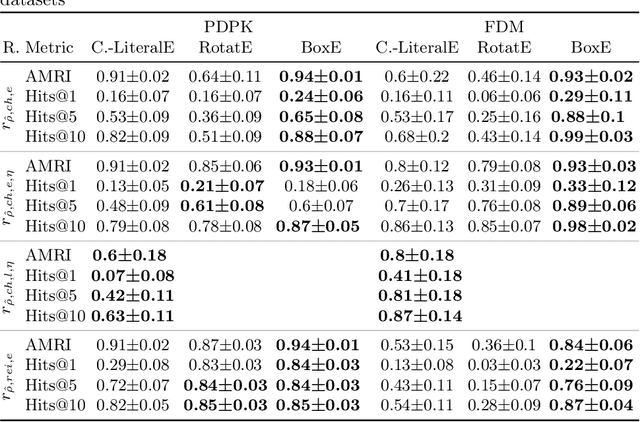
Procedural knowledge describes how to accomplish tasks and mitigate problems. Such knowledge is commonly held by domain experts, e.g. operators in manufacturing who adjust parameters to achieve quality targets. To the best of our knowledge, no real-world datasets containing process data and corresponding procedural knowledge are publicly available, possibly due to corporate apprehensions regarding the loss of knowledge advances. Therefore, we provide a framework to generate synthetic datasets that can be adapted to different domains. The design choices are inspired by two real-world datasets of procedural knowledge we have access to. Apart from containing representations of procedural knowledge in Resource Description Framework (RDF)-compliant knowledge graphs, the framework simulates parametrisation processes and provides consistent process data. We compare established embedding methods on the resulting knowledge graphs, detailing which out-of-the-box methods have the potential to represent procedural knowledge. This provides a baseline which can be used to increase the comparability of future work. Furthermore, we validate the overall characteristics of a synthesised dataset by comparing the results to those achievable on a real-world dataset. The framework and evaluation code, as well as the dataset used in the evaluation, are available open source.
Investigating the Impact of Independent Rule Fitnesses in a Learning Classifier System
Jul 12, 2022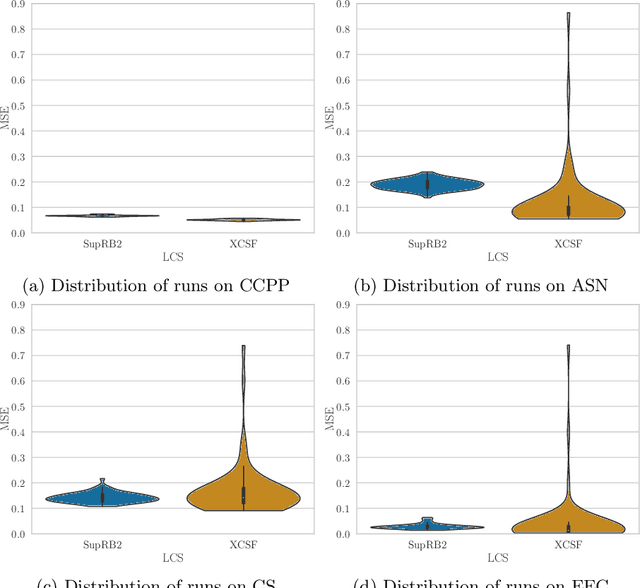
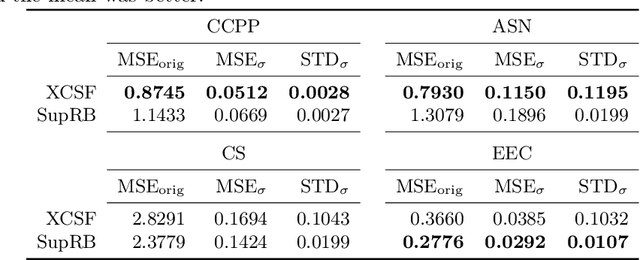
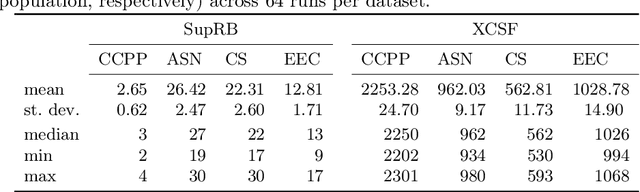
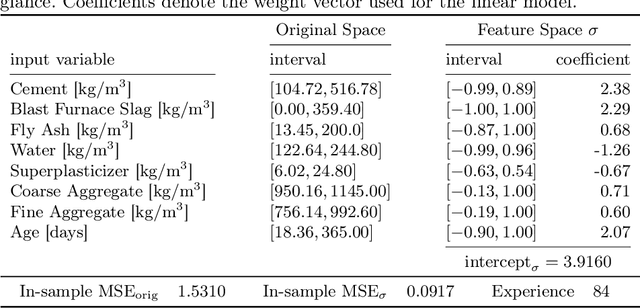
Achieving at least some level of explainability requires complex analyses for many machine learning systems, such as common black-box models. We recently proposed a new rule-based learning system, SupRB, to construct compact, interpretable and transparent models by utilizing separate optimizers for the model selection tasks concerning rule discovery and rule set composition.This allows users to specifically tailor their model structure to fulfil use-case specific explainability requirements. From an optimization perspective, this allows us to define clearer goals and we find that -- in contrast to many state of the art systems -- this allows us to keep rule fitnesses independent. In this paper we investigate this system's performance thoroughly on a set of regression problems and compare it against XCSF, a prominent rule-based learning system. We find the overall results of SupRB's evaluation comparable to XCSF's while allowing easier control of model structure and showing a substantially smaller sensitivity to random seeds and data splits. This increased control can aid in subsequently providing explanations for both training and final structure of the model.
Learning Classifier Systems for Self-Explaining Socio-Technical-Systems
Jul 01, 2022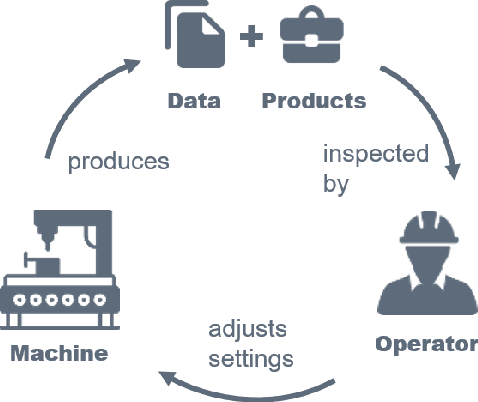
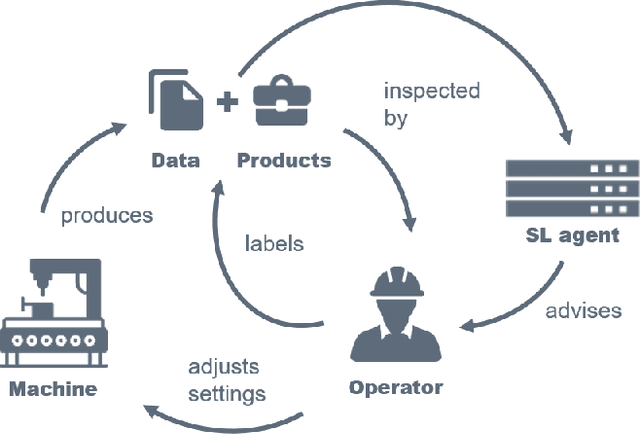
In socio-technical settings, operators are increasingly assisted by decision support systems. By employing these, important properties of socio-technical systems such as self-adaptation and self-optimization are expected to improve further. To be accepted by and engage efficiently with operators, decision support systems need to be able to provide explanations regarding the reasoning behind specific decisions. In this paper, we propose the usage of Learning Classifier Systems, a family of rule-based machine learning methods, to facilitate transparent decision making and highlight some techniques to improve that. We then present a template of seven questions to assess application-specific explainability needs and demonstrate their usage in an interview-based case study for a manufacturing scenario. We find that the answers received did yield useful insights for a well-designed LCS model and requirements to have stakeholders actively engage with an intelligent agent.
Separating Rule Discovery and Global Solution Composition in a Learning Classifier System
Feb 03, 2022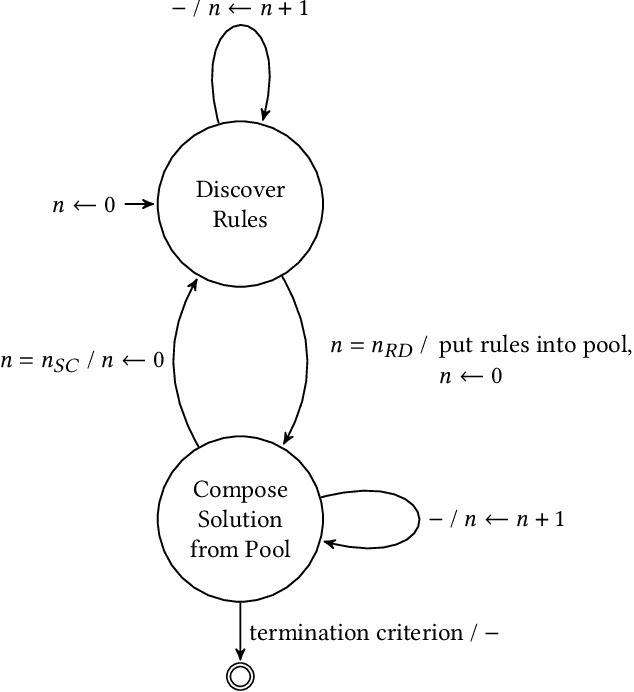


The utilization of digital agents to support crucial decision making is increasing in many industrial scenarios. However, trust in suggestions made by these agents is hard to achieve, though essential for profiting from their application, resulting in a need for explanations for both the decision making process as well as the model itself. For many systems, such as common deep learning black-box models, achieving at least some explainability requires complex post-processing, while other systems profit from being, to a reasonable extent, inherently interpretable. In this paper we propose an easily interpretable rule-based learning system specifically designed and thus especially suited for these scenarios and compare it on a set of regression problems against XCSF, a prominent rule-based learning system with a long research history. One key advantage of our system is that the rules' conditions and which rules compose a solution to the problem are evolved separately. We utilise independent rule fitnesses which allows users to specifically tailor their model structure to fit the given requirements for explainability. We find that the results of SupRB2's evaluation are comparable to XCSF's while allowing easier control of model structure and showing a substantially smaller sensitivity to random seeds and data splits. This increased control aids in subsequently providing explanations for both the training and the final structure of the model.
SupRB: A Supervised Rule-based Learning System for Continuous Problems
Feb 24, 2020

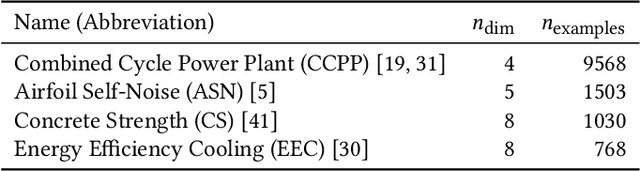
We propose the SupRB learning system, a new Pittsburgh-style learning classifier system (LCS) for supervised learning on multi-dimensional continuous decision problems. SupRB learns an approximation of a quality function from examples (consisting of situations, choices and associated qualities) and is then able to make an optimal choice as well as predict the quality of a choice in a given situation. One area of application for SupRB is parametrization of industrial machinery. In this field, acceptance of the recommendations of machine learning systems is highly reliant on operators' trust. While an essential and much-researched ingredient for that trust is prediction quality, it seems that this alone is not enough. At least as important is a human-understandable explanation of the reasoning behind a recommendation. While many state-of-the-art methods such as artificial neural networks fall short of this, LCSs such as SupRB provide human-readable rules that can be understood very easily. The prevalent LCSs are not directly applicable to this problem as they lack support for continuous choices. This paper lays the foundations for SupRB and shows its general applicability on a simplified model of an additive manufacturing problem.
XCS Classifier System with Experience Replay
Feb 13, 2020



XCS constitutes the most deeply investigated classifier system today. It bears strong potentials and comes with inherent capabilities for mastering a variety of different learning tasks. Besides outstanding successes in various classification and regression tasks, XCS also proved very effective in certain multi-step environments from the domain of reinforcement learning. Especially in the latter domain, recent advances have been mainly driven by algorithms which model their policies based on deep neural networks -- among which the Deep-Q-Network (DQN) is a prominent representative. Experience Replay (ER) constitutes one of the crucial factors for the DQN's successes, since it facilitates stabilized training of the neural network-based Q-function approximators. Surprisingly, XCS barely takes advantage of similar mechanisms that leverage stored raw experiences encountered so far. To bridge this gap, this paper investigates the benefits of extending XCS with ER. On the one hand, we demonstrate that for single-step tasks ER bears massive potential for improvements in terms of sample efficiency. On the shady side, however, we reveal that the use of ER might further aggravate well-studied issues not yet solved for XCS when applied to sequential decision problems demanding for long-action-chains.
Bootstrapping a DQN Replay Memory with Synthetic Experiences
Feb 04, 2020



An important component of many Deep Reinforcement Learning algorithms is the Experience Replay which serves as a storage mechanism or memory of made experiences. These experiences are used for training and help the agent to stably find the perfect trajectory through the problem space. The classic Experience Replay however makes only use of the experiences it actually made, but the stored samples bear great potential in form of knowledge about the problem that can be extracted. We present an algorithm that creates synthetic experiences in a nondeterministic discrete environment to assist the learner. The Interpolated Experience Replay is evaluated on the FrozenLake environment and we show that it can support the agent to learn faster and even better than the classic version.