 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing the Influence of Reorder Strategies for Cartesian Genetic Programming
Oct 01, 2024
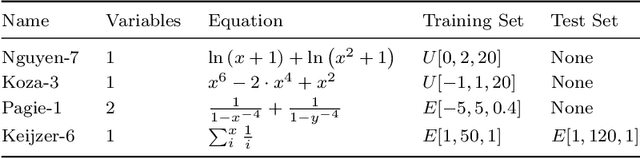
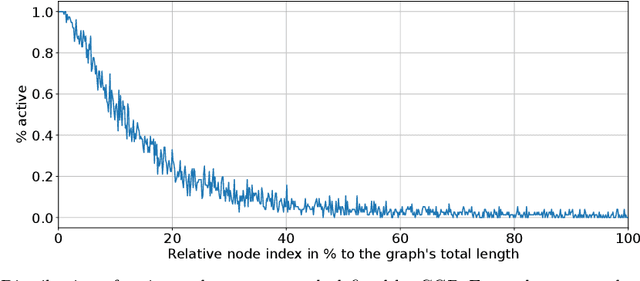

Cartesian Genetic Programming (CGP) suffers from a specific limitation: Positional bias, a phenomenon in which mostly genes at the start of the genome contribute to a program output, while genes at the end rarely do. This can lead to an overall worse performance of CGP. One solution to overcome positional bias is to introduce reordering methods, which shuffle the current genotype without changing its corresponding phenotype. There are currently two different reorder operators that extend the classic CGP formula and improve its fitness value. In this work, we discuss possible shortcomings of these two existing operators. Afterwards, we introduce three novel operators which reorder the genotype of a graph defined by CGP. We show empirically on four Boolean and four symbolic regression benchmarks that the number of iterations until a solution is found and/or the fitness value improves by using CGP with a reorder method. However, there is no consistently best performing reorder operator. Furthermore, their behaviour is analysed by investigating their convergence plots and we show that all behave the same in terms of convergence type.
Alternative Data Augmentation for Industrial Monitoring using Adversarial Learning
May 09, 2022


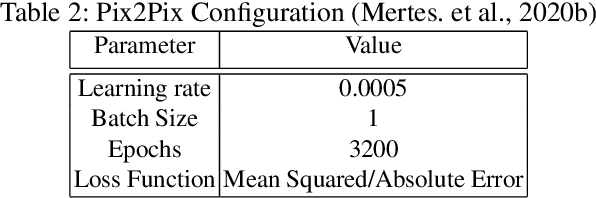
Visual inspection software has become a key factor in the manufacturing industry for quality control and process monitoring. Semantic segmentation models have gained importance since they allow for more precise examination. These models, however, require large image datasets in order to achieve a fair accuracy level. In some cases, training data is sparse or lacks of sufficient annotation, a fact that especially applies to highly specialized production environments. Data augmentation represents a common strategy to extend the dataset. Still, it only varies the image within a narrow range. In this article, a novel strategy is proposed to augment small image datasets. The approach is applied to surface monitoring of carbon fibers, a specific industry use case. We apply two different methods to create binary labels: a problem-tailored trigonometric function and a WGAN model. Afterwards, the labels are translated into color images using pix2pix and used to train a U-Net. The results suggest that the trigonometric function is superior to the WGAN model. However, a precise examination of the resulting images indicate that WGAN and image-to-image translation achieve good segmentation results and only deviate to a small degree from traditional data augmentation. In summary, this study examines an industry application of data synthesization using generative adversarial networks and explores its potential for monitoring systems of production environments. \keywords{Image-to-Image Translation, Carbon Fiber, Data Augmentation, Computer Vision, Industrial Monitoring, Adversarial Learning.