 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Language and Graph Models for Semi-structured Information Extraction on the Web
Paper and Code
Feb 21, 2024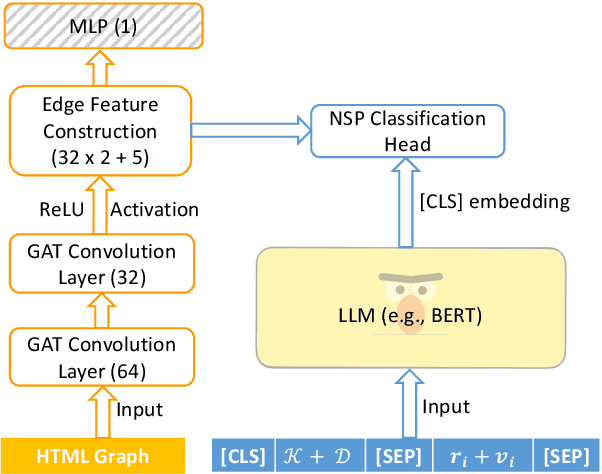

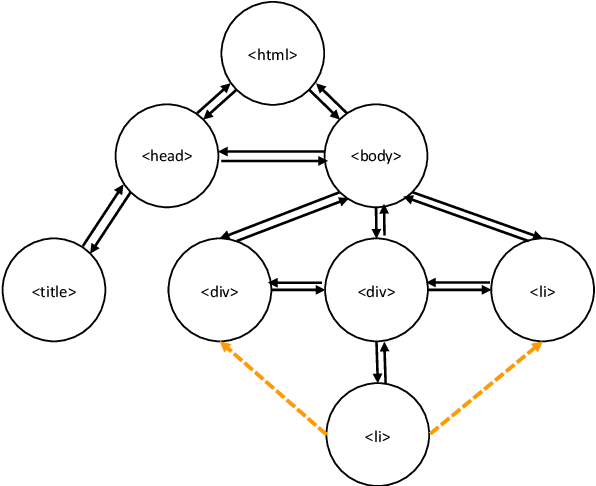

Relation extraction is an efficient way of mining the extraordinary wealth of human knowledge on the Web. Existing methods rely on domain-specific training data or produce noisy outputs. We focus here on extracting targeted relations from semi-structured web pages given only a short description of the relation. We present GraphScholarBERT, an open-domain information extraction method based on a joint graph and language model structure. GraphScholarBERT can generalize to previously unseen domains without additional data or training and produces only clean extraction results matched to the search keyword. Experiments show that GraphScholarBERT can improve extraction F1 scores by as much as 34.8\% compared to previous work in a zero-shot domain and zero-shot website setting.