 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Streams of Relation Extraction: Enriching and Recalling in Transformers
Jun 25, 2025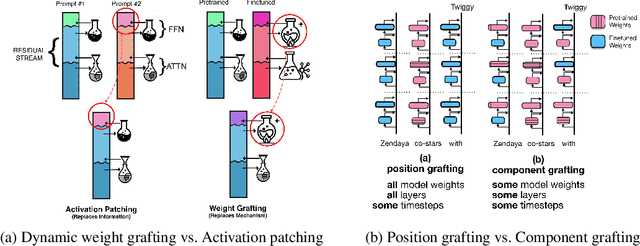

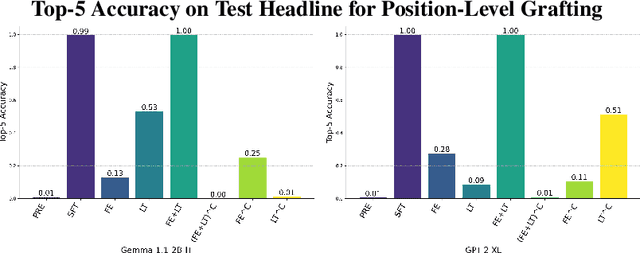

When an LLM learns a relation during finetuning (e.g., new movie releases, corporate mergers, etc.), where does this information go? Is it extracted when the model processes an entity, recalled just-in-time before a prediction, or are there multiple separate heuristics? Existing localization approaches (e.g. activation patching) are ill-suited for this analysis because they tend to replace parts of the residual stream, potentially deleting information. To fill this gap, we propose dynamic weight-grafting between fine-tuned and pre-trained language models to show that fine-tuned language models both (1) extract relation information learned during finetuning while processing entities and (2) ``recall" this information in later layers while generating predictions. In some cases, models need both of these pathways to correctly generate finetuned information while, in other cases, a single ``enrichment" or ``recall" pathway alone is sufficient. We examine the necessity and sufficiency of these information pathways, examining what layers they occur at, how much redundancy they exhibit, and which model components are involved -- finding that the ``recall" pathway occurs via both task-specific attention mechanisms and a relation extraction step in the output of the attention and the feedforward networks at the final layers before next token prediction.
RATE: Score Reward Models with Imperfect Rewrites of Rewrites
Oct 15, 2024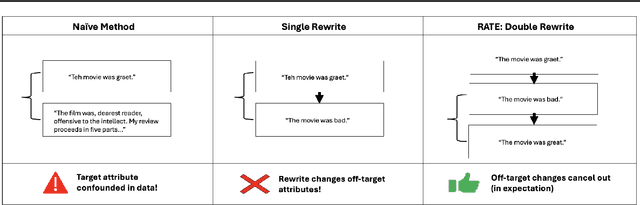

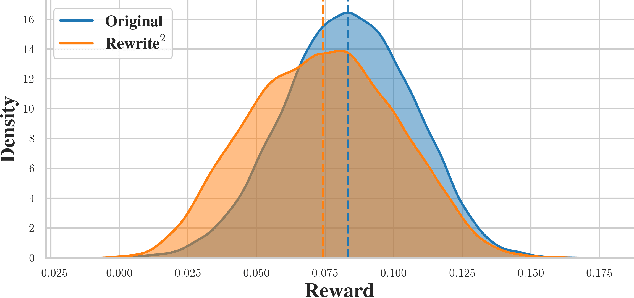
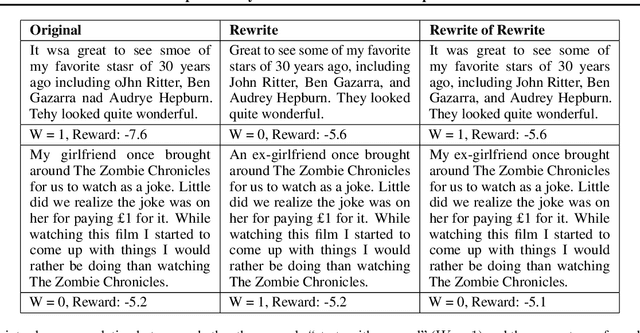
This paper concerns the evaluation of reward models used in language modeling. A reward model is a function that takes a prompt and a response and assigns a score indicating how good that response is for the prompt. A key challenge is that reward models are usually imperfect proxies for actual preferences. For example, we may worry that a model trained to reward helpfulness learns to instead prefer longer responses. In this paper, we develop an evaluation method, RATE (Rewrite-based Attribute Treatment Estimators), that allows us to measure the causal effect of a given attribute of a response (e.g., length) on the reward assigned to that response. The core idea is to use large language models to rewrite responses to produce imperfect counterfactuals, and to adjust for rewriting error by rewriting twice. We show that the RATE estimator is consistent under reasonable assumptions. We demonstrate the effectiveness of RATE on synthetic and real-world data, showing that it can accurately estimate the effect of a given attribute on the reward model.