 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionAtlas: A VideoQA Benchmark for Domain-specialized Action Recognition
Paper and Code



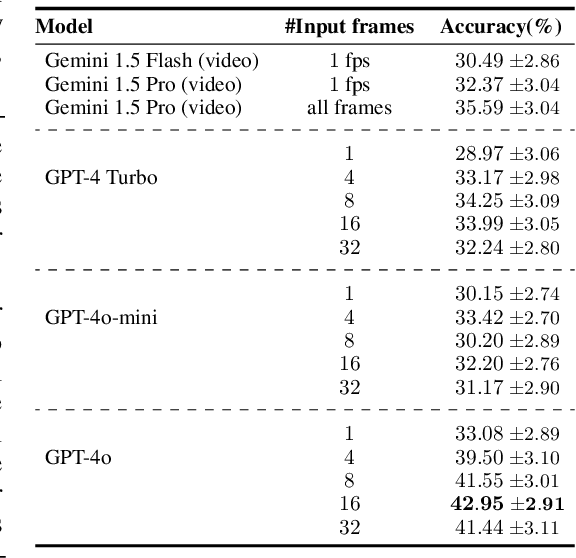
Our world is full of varied actions and moves across specialized domains that we, as humans, strive to identify and understand. Within any single domain, actions can often appear quite similar, making it challenging for deep models to distinguish them accurately. To evaluate the effectiveness of multimodal foundation models in helping us recognize such actions, we present ActionAtlas v1.0, a multiple-choice video question answering benchmark featuring short videos across various sports. Each video in the dataset is paired with a question and four or five choices. The question pinpoints specific individuals, asking which choice "best" describes their action within a certain temporal context. Overall, the dataset includes 934 videos showcasing 580 unique actions across 56 sports, with a total of 1896 actions within choices. Unlike most existing video question answering benchmarks that only cover simplistic actions, often identifiable from a single frame, ActionAtlas focuses on intricate movements and rigorously tests the model's capability to discern subtle differences between moves that look similar within each domain. We evaluate open and proprietary foundation models on this benchmark, finding that the best model, GPT-4o, achieves a maximum accuracy of 45.52%. Meanwhile, Non-expert crowd workers, provided with action description for each choice, achieve 61.64% accuracy, where random chance is approximately 21%. Our findings with state-of-the-art models indicate that having a high frame sampling rate is important for accurately recognizing actions in ActionAtlas, a feature that some leading proprietary video models, such as Gemini, do not include in their default configuration.