 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation for Video Highlight Detection Using Meta-Auxiliary Learning and Cross-Modality Hallucinations
Aug 06, 2025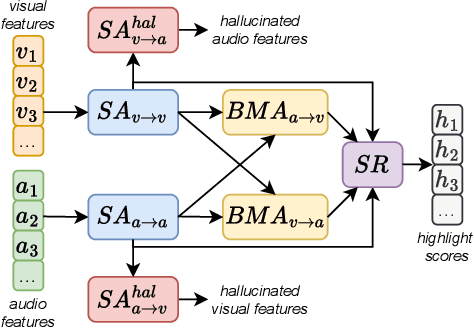
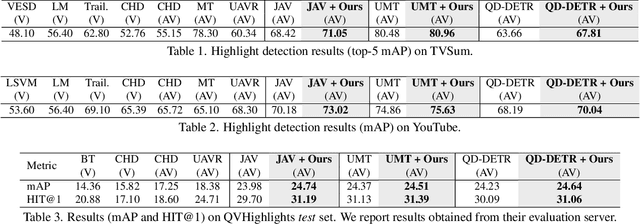
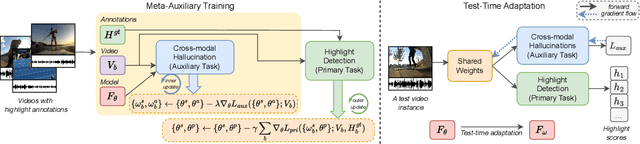
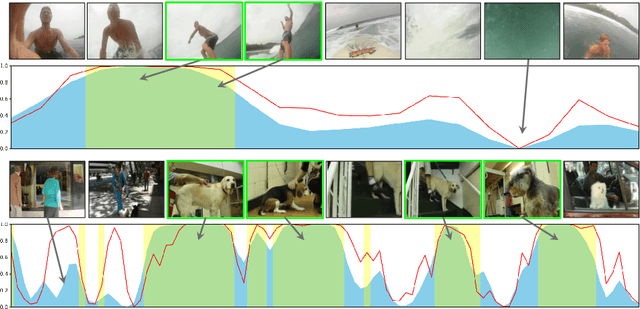
Existing video highlight detection methods, although advanced, struggle to generalize well to all test videos. These methods typically employ a generic highlight detection model for each test video, which is suboptimal as it fails to account for the unique characteristics and variations of individual test videos. Such fixed models do not adapt to the diverse content, styles, or audio and visual qualities present in new, unseen test videos, leading to reduced highlight detection performance. In this paper, we propose Highlight-TTA, a test-time adaptation framework for video highlight detection that addresses this limitation by dynamically adapting the model during testing to better align with the specific characteristics of each test video, thereby improving generalization and highlight detection performance. Highlight-TTA is jointly optimized with an auxiliary task, cross-modality hallucinations, alongside the primary highlight detection task. We utilize a meta-auxiliary training scheme to enable effective adaptation through the auxiliary task while enhancing the primary task. During testing, we adapt the trained model using the auxiliary task on the test video to further enhance its highlight detection performance. Extensive experiments with three state-of-the-art highlight detection models and three benchmark datasets show that the introduction of Highlight-TTA to these models improves their performance, yielding superior results.
Unsupervised Video Highlight Detection by Learning from Audio and Visual Recurrence
Jul 18, 2024

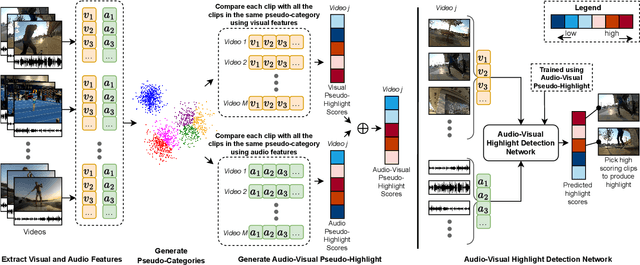
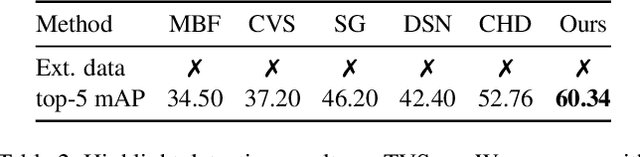
With the exponential growth of video content, the need for automated video highlight detection to extract key moments or highlights from lengthy videos has become increasingly pressing. This technology has the potential to significantly enhance user experiences by allowing quick access to relevant content across diverse domains. Existing methods typically rely either on expensive manually labeled frame-level annotations, or on a large external dataset of videos for weak supervision through category information. To overcome this, we focus on unsupervised video highlight detection, eliminating the need for manual annotations. We propose an innovative unsupervised approach which capitalizes on the premise that significant moments tend to recur across multiple videos of the similar category in both audio and visual modalities. Surprisingly, audio remains under-explored, especially in unsupervised algorithms, despite its potential to detect key moments. Through a clustering technique, we identify pseudo-categories of videos and compute audio pseudo-highlight scores for each video by measuring the similarities of audio features among audio clips of all the videos within each pseudo-category. Similarly, we also compute visual pseudo-highlight scores for each video using visual features. Subsequently, we combine audio and visual pseudo-highlights to create the audio-visual pseudo ground-truth highlight of each video for training an audio-visual highlight detection network. Extensive experiments and ablation studies on three highlight detection benchmarks showcase the superior performance of our method over prior work.
Uncertainty Driven Bottleneck Attention U-net for OAR Segmentation
Mar 19, 2023
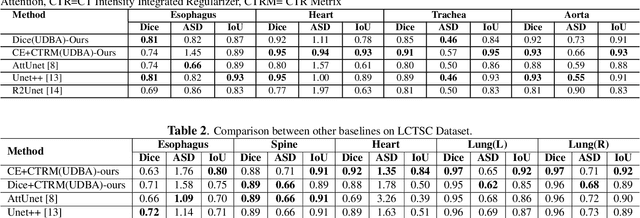
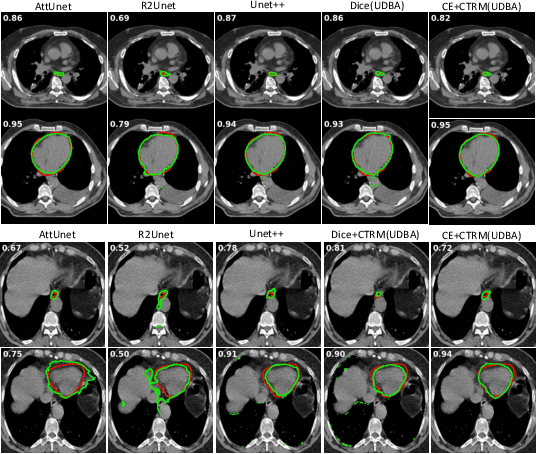
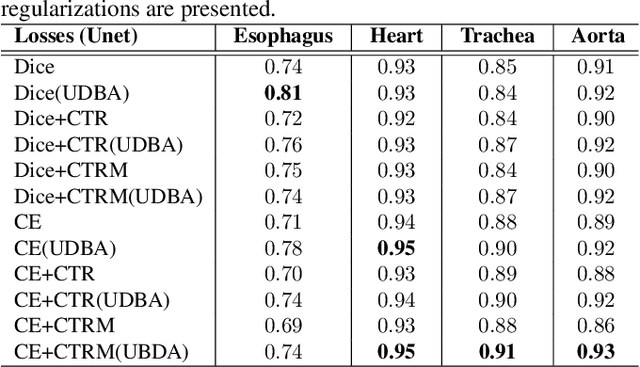
Organ at risk (OAR) segmentation in computed tomography (CT) imagery is a difficult task for automated segmentation methods and can be crucial for downstream radiation treatment planning. U-net has become a de-facto standard for medical image segmentation and is frequently used as a common baseline in medical image segmentation tasks. In this paper, we develop a multiple decoder U-net architecture where a noisy auxiliary decoder is used to generate noisy segmentation. The segmentation from the main branch and the noisy segmentation from the auxiliary branch are used together to estimate the attention. Our contribution is the development of a new attention module which derives the attention from the softmax probabilities of two decoder branches. The union and intersection of two segmentation masks from two branches carry the information where both decoders agree and disagree. The softmax probabilities from regions of agreement and disagreement are the indicators of low and high uncertainty. Thus, the probabilities of those selected regions are used as attention in the bottleneck layer of the encoder and passes only through the main decoder for segmentation. For accurate contour segmentation, we also developed a CT intensity integrated regularization loss. We tested our model on two publicly available OAR challenge datasets, Segthor and LCTSC respectively. We trained 12 models on each dataset with and without the proposed attention model and regularization loss to check the effectiveness of the attention module and the regularization loss. The experiments demonstrate a clear accuracy improvement (2\% to 5\% Dice) on both datasets. Code for the experiments will be made available upon the acceptance for publication.
Efficient Two-Stream Network for Violence Detection Using Separable Convolutional LSTM
Feb 21, 2021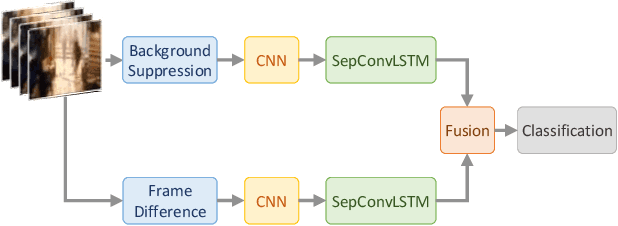

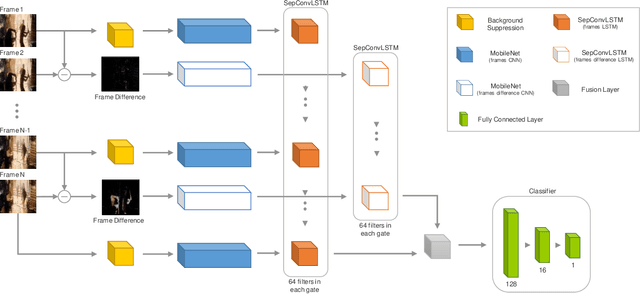
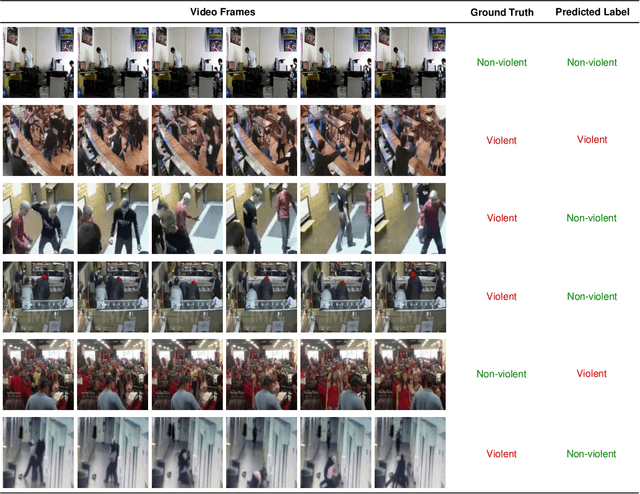
Automatically detecting violence from surveillance footage is a subset of activity recognition that deserves special attention because of its wide applicability in unmanned security monitoring systems, internet video filtration, etc. In this work, we propose an efficient two-stream deep learning architecture leveraging Separable Convolutional LSTM (SepConvLSTM) and pre-trained MobileNet where one stream takes in background suppressed frames as inputs and other stream processes difference of adjacent frames. We employed simple and fast input pre-processing techniques that highlight the moving objects in the frames by suppressing non-moving backgrounds and capture the motion in-between frames. As violent actions are mostly characterized by body movements these inputs help produce discriminative features. SepConvLSTM is constructed by replacing convolution operation at each gate of ConvLSTM with a depthwise separable convolution that enables producing robust long-range Spatio-temporal features while using substantially fewer parameters. We experimented with three fusion methods to combine the output feature maps of the two streams. Evaluation of the proposed methods was done on three standard public datasets. Our model outperforms the accuracy on the larger and more challenging RWF-2000 dataset by more than a 2% margin while matching state-of-the-art results on the smaller datasets. Our experiments lead us to conclude, the proposed models are superior in terms of both computational efficiency and detection accuracy.