 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Two-Stream Network for Violence Detection Using Separable Convolutional LSTM
Paper and Code
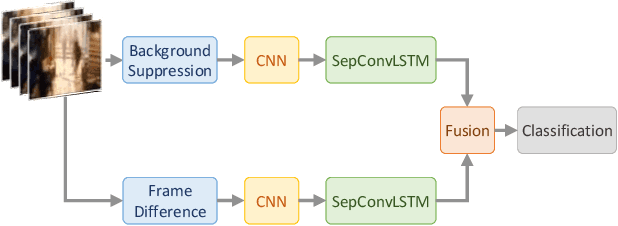

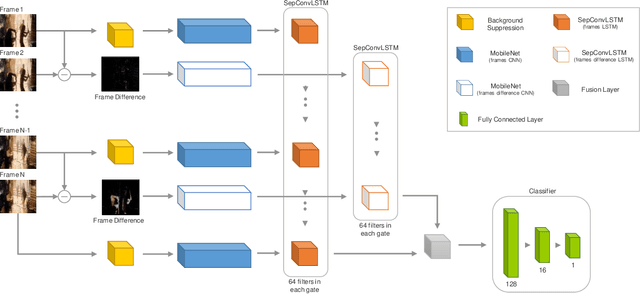
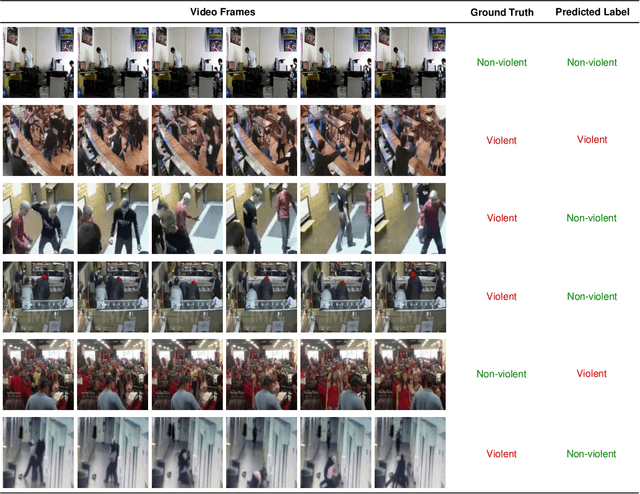
Automatically detecting violence from surveillance footage is a subset of activity recognition that deserves special attention because of its wide applicability in unmanned security monitoring systems, internet video filtration, etc. In this work, we propose an efficient two-stream deep learning architecture leveraging Separable Convolutional LSTM (SepConvLSTM) and pre-trained MobileNet where one stream takes in background suppressed frames as inputs and other stream processes difference of adjacent frames. We employed simple and fast input pre-processing techniques that highlight the moving objects in the frames by suppressing non-moving backgrounds and capture the motion in-between frames. As violent actions are mostly characterized by body movements these inputs help produce discriminative features. SepConvLSTM is constructed by replacing convolution operation at each gate of ConvLSTM with a depthwise separable convolution that enables producing robust long-range Spatio-temporal features while using substantially fewer parameters. We experimented with three fusion methods to combine the output feature maps of the two streams. Evaluation of the proposed methods was done on three standard public datasets. Our model outperforms the accuracy on the larger and more challenging RWF-2000 dataset by more than a 2% margin while matching state-of-the-art results on the smaller datasets. Our experiments lead us to conclude, the proposed models are superior in terms of both computational efficiency and detection accuracy.