 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Guided Temporal Modulation for Dynamic Video Thumbnail Generation
Paper and Code
Aug 31, 2020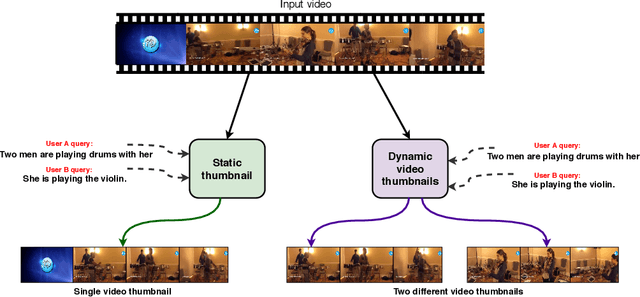
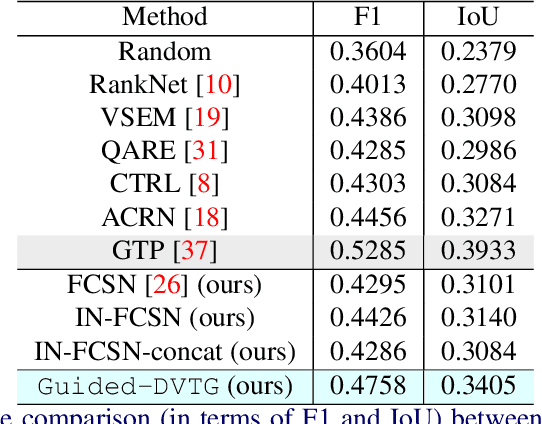
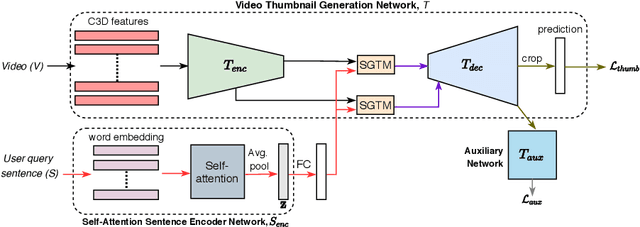

We consider the problem of sentence specified dynamic video thumbnail generation. Given an input video and a user query sentence, the goal is to generate a video thumbnail that not only provides the preview of the video content, but also semantically corresponds to the sentence. In this paper, we propose a sentence guided temporal modulation (SGTM) mechanism that utilizes the sentence embedding to modulate the normalized temporal activations of the video thumbnail generation network. Unlike the existing state-of-the-art method that uses recurrent architectures, we propose a non-recurrent framework that is simple and allows much more parallelization. Extensive experiments and analysis on a large-scale dataset demonstrate the effectiveness of our framework.