 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Frame Prediction Using Convolutional VRNN for Anomaly Detection
Oct 18, 2019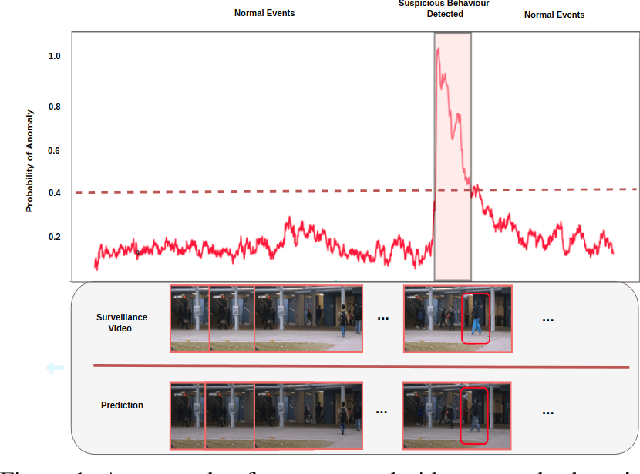
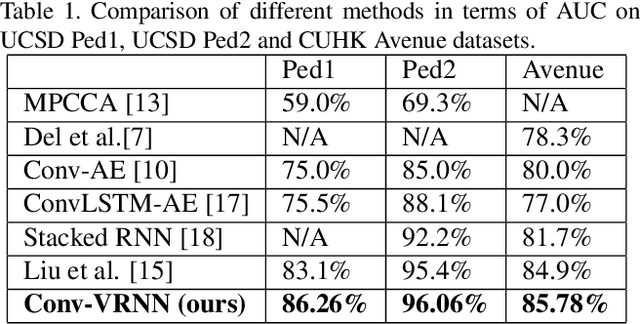
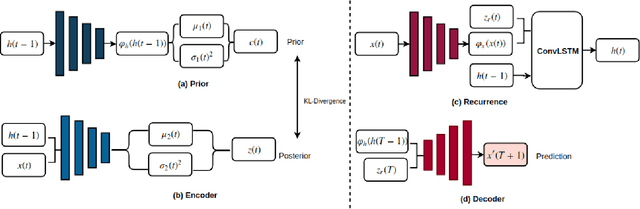
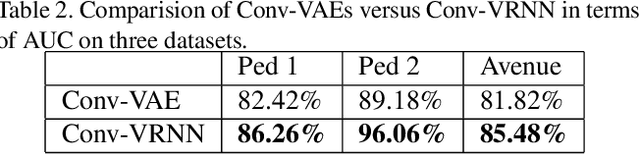
Anomaly detection in videos aims at reporting anything that does not conform the normal behaviour or distribution. However, due to the sparsity of abnormal video clips in real life, collecting annotated data for supervised learning is exceptionally cumbersome. Inspired by the practicability of generative models for semi-supervised learning, we propose a novel sequential generative model based on variational autoencoder (VAE) for future frame prediction with convolutional LSTM (ConvLSTM). To the best of our knowledge, this is the first work that considers temporal information in future frame prediction based anomaly detection framework from the model perspective. Our experiments demonstrate that our approach is superior to the state-of-the-art methods on three benchmark datasets.
Future Semantic Segmentation with Convolutional LSTM
Jul 20, 2018

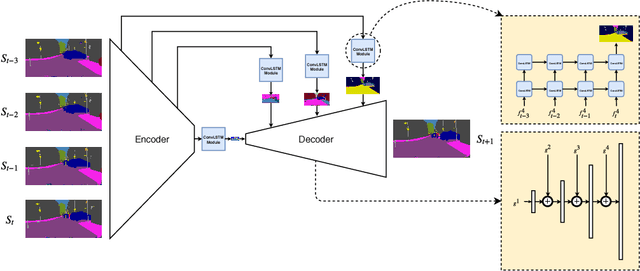

We consider the problem of predicting semantic segmentation of future frames in a video. Given several observed frames in a video, our goal is to predict the semantic segmentation map of future frames that are not yet observed. A reliable solution to this problem is useful in many applications that require real-time decision making, such as autonomous driving. We propose a novel model that uses convolutional LSTM (ConvLSTM) to encode the spatiotemporal information of observed frames for future prediction. We also extend our model to use bidirectional ConvLSTM to capture temporal information in both directions. Our proposed approach outperforms other state-of-the-art methods on the benchmark dataset.