 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Video Models Adhere to User Intent with Minor Adjustments
Mar 20, 2026With the recent drastic advancements in text-to-video diffusion models, controlling their generations has drawn interest. A popular way for control is through bounding boxes or layouts. However, enforcing adherence to these control inputs is still an open problem. In this work, we show that by slightly adjusting user-provided bounding boxes we can improve both the quality of generations and the adherence to the control inputs. This is achieved by simply optimizing the bounding boxes to better align with the internal attention maps of the video diffusion model while carefully balancing the focus on foreground and background. In a sense, we are modifying the bounding boxes to be at places where the model is familiar with. Surprisingly, we find that even with small modifications, the quality of generations can vary significantly. To do so, we propose a smooth mask to make the bounding box position differentiable and an attention-maximization objective that we use to alter the bounding boxes. We conduct thorough experiments, including a user study to validate the effectiveness of our method. Our code is made available on the project webpage to foster future research from the community.
CasCalib: Cascaded Calibration for Motion Capture from Sparse Unsynchronized Cameras
May 10, 2024



It is now possible to estimate 3D human pose from monocular images with off-the-shelf 3D pose estimators. However, many practical applications require fine-grained absolute pose information for which multi-view cues and camera calibration are necessary. Such multi-view recordings are laborious because they require manual calibration, and are expensive when using dedicated hardware. Our goal is full automation, which includes temporal synchronization, as well as intrinsic and extrinsic camera calibration. This is done by using persons in the scene as the calibration objects. Existing methods either address only synchronization or calibration, assume one of the former as input, or have significant limitations. A common limitation is that they only consider single persons, which eases correspondence finding. We attain this generality by partitioning the high-dimensional time and calibration space into a cascade of subspaces and introduce tailored algorithms to optimize each efficiently and robustly. The outcome is an easy-to-use, flexible, and robust motion capture toolbox that we release to enable scientific applications, which we demonstrate on diverse multi-view benchmarks. Project website: https://github.com/jamestang1998/CasCalib.
A Survey on African Computer Vision Datasets, Topics and Researchers
Feb 04, 2024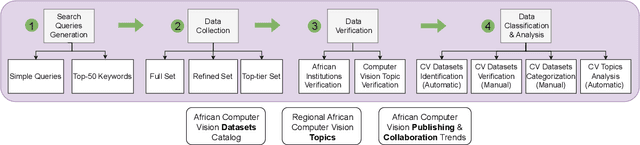


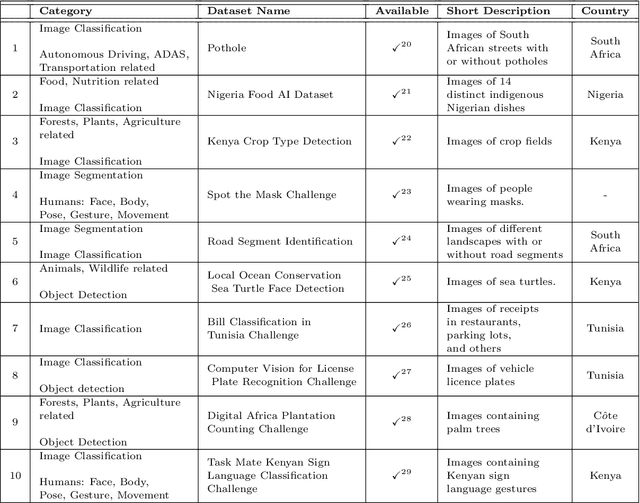
Computer vision encompasses a range of tasks such as object detection, semantic segmentation, and 3D reconstruction. Despite its relevance to African communities, research in this field within Africa represents only 0.06% of top-tier publications over the past decade. This study undertakes a thorough analysis of 63,000 Scopus-indexed computer vision publications from Africa, spanning from 2012 to 2022. The aim is to provide a survey of African computer vision topics, datasets and researchers. A key aspect of our study is the identification and categorization of African Computer Vision datasets using large language models that automatically parse abstracts of these publications. We also provide a compilation of unofficial African Computer Vision datasets distributed through challenges or data hosting platforms, and provide a full taxonomy of dataset categories. Our survey also pinpoints computer vision topics trends specific to different African regions, indicating their unique focus areas. Additionally, we carried out an extensive survey to capture the views of African researchers on the current state of computer vision research in the continent and the structural barriers they believe need urgent attention. In conclusion, this study catalogs and categorizes Computer Vision datasets and topics contributed or initiated by African institutions and identifies barriers to publishing in top-tier Computer Vision venues. This survey underscores the importance of encouraging African researchers and institutions in advancing computer vision research in the continent. It also stresses on the need for research topics to be more aligned with the needs of African communities.
Mirror-Aware Neural Humans
Sep 09, 2023Human motion capture either requires multi-camera systems or is unreliable using single-view input due to depth ambiguities. Meanwhile, mirrors are readily available in urban environments and form an affordable alternative by recording two views with only a single camera. However, the mirror setting poses the additional challenge of handling occlusions of real and mirror image. Going beyond existing mirror approaches for 3D human pose estimation, we utilize mirrors for learning a complete body model, including shape and dense appearance. Our main contributions are extending articulated neural radiance fields to include a notion of a mirror, making it sample-efficient over potential occlusion regions. Together, our contributions realize a consumer-level 3D motion capture system that starts from off-the-shelf 2D poses by automatically calibrating the camera, estimating mirror orientation, and subsequently lifting 2D keypoint detections to 3D skeleton pose that is used to condition the mirror-aware NeRF. We empirically demonstrate the benefit of learning a body model and accounting for occlusion in challenging mirror scenes.
Towards End-to-End Training of Automatic Speech Recognition for Nigerian Pidgin
Oct 21, 2020
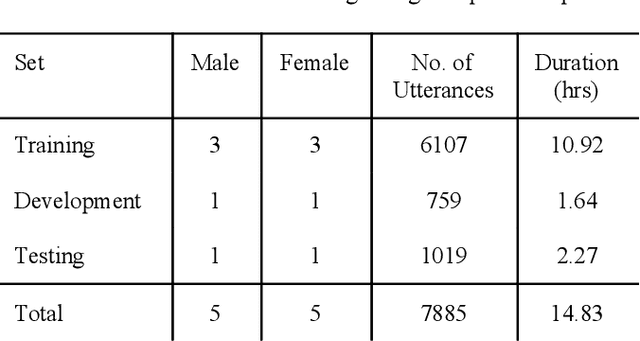
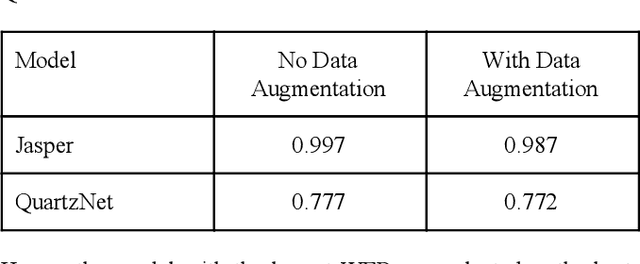
Nigerian Pidgin remains one of the most popular languages in West Africa. With at least 75 million speakers along the West African coast, the language has spread to diasporic communities through Nigerian immigrants in England, Canada, and America, amongst others. In contrast, the language remains an under-resourced one in the field of natural language processing, particularly on speech recognition and translation tasks. In this work, we present the first parallel (speech-to-text) data on Nigerian pidgin. We also trained the first end-to-end speech recognition system (QuartzNet and Jasper model) on this language which were both optimized using Connectionist Temporal Classification (CTC) loss. With baseline results, we were able to achieve a low word error rate (WER) of 0.77% using a greedy decoder on our dataset. Finally, we open-source the data and code along with this publication in order to encourage future research in this direction.