 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Temporal Difference Reinforcement Learning
Jul 10, 2023Reinforcement learning has been successful across several applications in which agents have to learn to act in environments with sparse feedback. However, despite this empirical success there is still a lack of theoretical understanding of how the parameters of reinforcement learning models and the features used to represent states interact to control the dynamics of learning. In this work, we use concepts from statistical physics, to study the typical case learning curves for temporal difference learning of a value function with linear function approximators. Our theory is derived under a Gaussian equivalence hypothesis where averages over the random trajectories are replaced with temporally correlated Gaussian feature averages and we validate our assumptions on small scale Markov Decision Processes. We find that the stochastic semi-gradient noise due to subsampling the space of possible episodes leads to significant plateaus in the value error, unlike in traditional gradient descent dynamics. We study how learning dynamics and plateaus depend on feature structure, learning rate, discount factor, and reward function. We then analyze how strategies like learning rate annealing and reward shaping can favorably alter learning dynamics and plateaus. To conclude, our work introduces new tools to open a new direction towards developing a theory of learning dynamics in reinforcement learning.
Construction of Macro Actions for Deep Reinforcement Learning
Aug 05, 2019
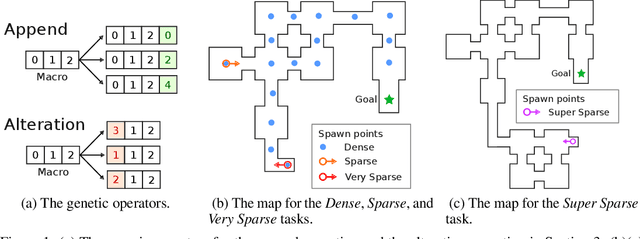
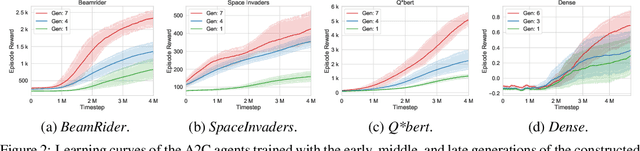
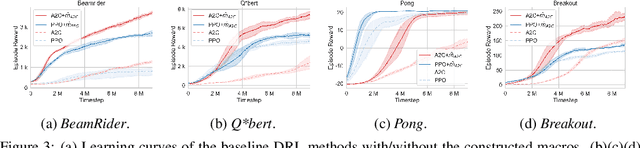
Conventional deep reinforcement learning typically determines an appropriate primitive action at each timestep, which requires enormous amount of time and effort for learning an effective policy, especially in large and complex environments. To deal with the issue fundamentally, we incorporate macro actions, defined as sequences of primitive actions, into the primitive action space to form an augmented action space. The problem lies in how to find an appropriate macro action to augment the primitive action space. The agent using a proper augmented action space is able to jump to a farther state and thus speed up the exploration process as well as facilitate the learning procedure. In previous researches, macro actions are developed by mining the most frequently used action sequences or repeating previous actions. However, the most frequently used action sequences are extracted from a past policy, which may only reinforce the original behavior of that policy. On the other hand, repeating actions may limit the diversity of behaviors of the agent. Instead, we propose to construct macro actions by a genetic algorithm, which eliminates the dependency of the macro action derivation procedure from the past policies of the agent. Our approach appends a macro action to the primitive action space once at a time and evaluates whether the augmented action space leads to promising performance or not. We perform extensive experiments and show that the constructed macro actions are able to speed up the learning process for a variety of deep reinforcement learning methods. Our experimental results also demonstrate that the macro actions suggested by our approach are transferable among deep reinforcement learning methods and similar environments. We further provide a comprehensive set of ablation analysis to validate the proposed methodology.