 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Step Returns in Bootstrapped DQN
Jul 16, 2020



The concept of utilizing multi-step returns for updating value functions has been adopted in deep reinforcement learning (DRL) for a number of years. Updating value functions with different backup lengths provides advantages in different aspects, including bias and variance of value estimates, convergence speed, and exploration behavior of the agent. Conventional methods such as TD-lambda leverage these advantages by using a target value equivalent to an exponential average of different step returns. Nevertheless, integrating step returns into a single target sacrifices the diversity of the advantages offered by different step return targets. To address this issue, we propose Mixture Bootstrapped DQN (MB-DQN) built on top of bootstrapped DQN, and uses different backup lengths for different bootstrapped heads. MB-DQN enables heterogeneity of the target values that is unavailable in approaches relying only on a single target value. As a result, it is able to maintain the advantages offered by different backup lengths. In this paper, we first discuss the motivational insights through a simple maze environment. In order to validate the effectiveness of MB-DQN, we perform experiments on the Atari 2600 benchmark environments, and demonstrate the performance improvement of MB-DQN over a number of baseline methods. We further provide a set of ablation studies to examine the impacts of different design configurations of MB-DQN.
Exploration via Flow-Based Intrinsic Rewards
May 24, 2019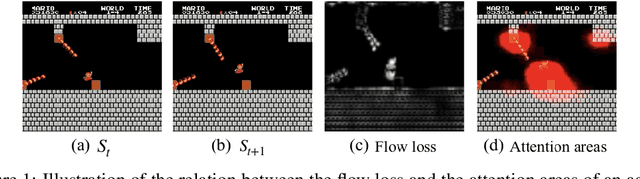
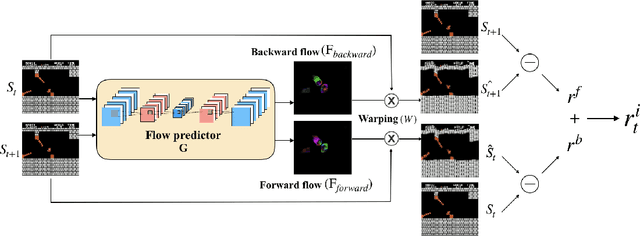
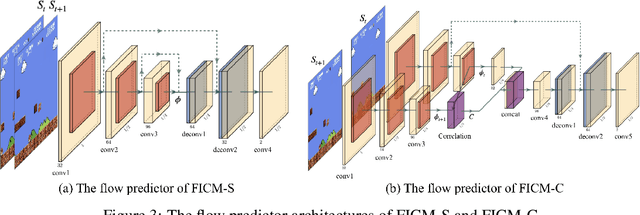
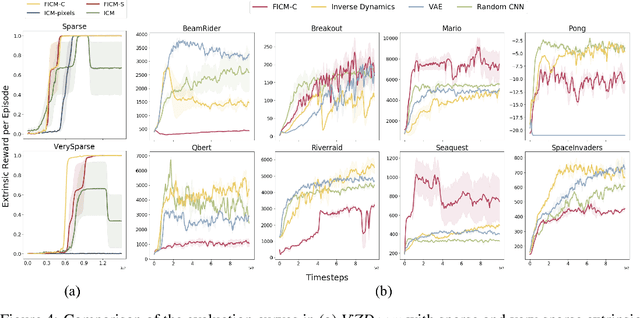
Exploration bonuses derived from the novelty of observations in an environment have become a popular approach to motivate exploration for reinforcement learning (RL) agents in the past few years. Recent methods such as curiosity-driven exploration usually estimate the novelty of new observations by the prediction errors of their system dynamics models. In this paper, we introduce the concept of optical flow estimation from the field of computer vision to the RL domain and utilize the errors from optical flow estimation to evaluate the novelty of new observations. We introduce a flow-based intrinsic curiosity module (FICM) capable of learning the motion features and understanding the observations in a more comprehensive and efficient fashion. We evaluate our method and compare it with a number of baselines on several benchmark environments, including Atari games, Super Mario Bros., and ViZDoom. Our results show that the proposed method is superior to the baselines in certain environments, especially for those featuring sophisticated moving patterns or with high-dimensional observation spaces. We further analyze the hyper-parameters used in the training phase and discuss our insights into them.
Never Forget: Balancing Exploration and Exploitation via Learning Optical Flow
Jan 24, 2019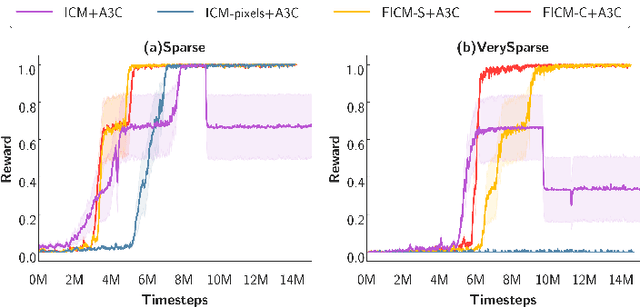

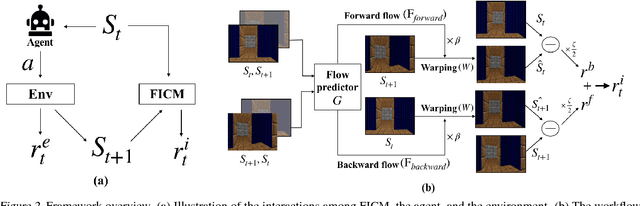
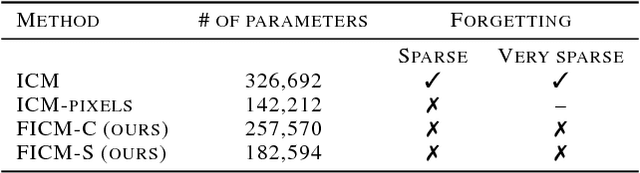
Exploration bonus derived from the novelty of the states in an environment has become a popular approach to motivate exploration for deep reinforcement learning agents in the past few years. Recent methods such as curiosity-driven exploration usually estimate the novelty of new observations by the prediction errors of their system dynamics models. Due to the capacity limitation of the models and difficulty of performing next-frame prediction, however, these methods typically fail to balance between exploration and exploitation in high-dimensional observation tasks, resulting in the agents forgetting the visited paths and exploring those states repeatedly. Such inefficient exploration behavior causes significant performance drops, especially in large environments with sparse reward signals. In this paper, we propose to introduce the concept of optical flow estimation from the field of computer vision to deal with the above issue. We propose to employ optical flow estimation errors to examine the novelty of new observations, such that agents are able to memorize and understand the visited states in a more comprehensive fashion. We compare our method against the previous approaches in a number of experimental experiments. Our results indicate that the proposed method appears to deliver superior and long-lasting performance than the previous methods. We further provide a set of comprehensive ablative analysis of the proposed method, and investigate the impact of optical flow estimation on the learning curves of the DRL agents.