 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Lipschitz Continuity: A Cost-Effective Approach to Improve Adversarial Robustness
Jun 28, 2024



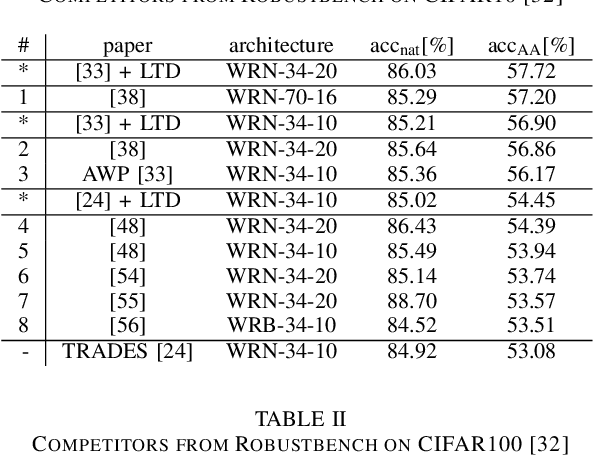
The security and robustness of deep neural networks (DNNs) have become increasingly concerning. This paper aims to provide both a theoretical foundation and a practical solution to ensure the reliability of DNNs. We explore the concept of Lipschitz continuity to certify the robustness of DNNs against adversarial attacks, which aim to mislead the network with adding imperceptible perturbations into inputs. We propose a novel algorithm that remaps the input domain into a constrained range, reducing the Lipschitz constant and potentially enhancing robustness. Unlike existing adversarially trained models, where robustness is enhanced by introducing additional examples from other datasets or generative models, our method is almost cost-free as it can be integrated with existing models without requiring re-training. Experimental results demonstrate the generalizability of our method, as it can be combined with various models and achieve enhancements in robustness. Furthermore, our method achieves the best robust accuracy for CIFAR10, CIFAR100, and ImageNet datasets on the RobustBench leaderboard.
Steal Now and Attack Later: Evaluating Robustness of Object Detection against Black-box Adversarial Attacks
Apr 24, 2024Latency attacks against object detection represent a variant of adversarial attacks that aim to inflate the inference time by generating additional ghost objects in a target image. However, generating ghost objects in the black-box scenario remains a challenge since information about these unqualified objects remains opaque. In this study, we demonstrate the feasibility of generating ghost objects in adversarial examples by extending the concept of "steal now, decrypt later" attacks. These adversarial examples, once produced, can be employed to exploit potential vulnerabilities in the AI service, giving rise to significant security concerns. The experimental results demonstrate that the proposed attack achieves successful attacks across various commonly used models and Google Vision API without any prior knowledge about the target model. Additionally, the average cost of each attack is less than \$ 1 dollars, posing a significant threat to AI security.
Low-rank Tensor Decomposition for Compression of Convolutional Neural Networks Using Funnel Regularization
Dec 07, 2021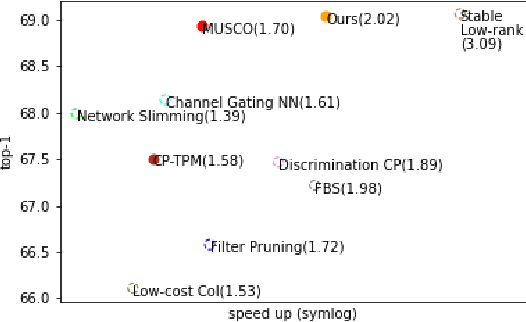
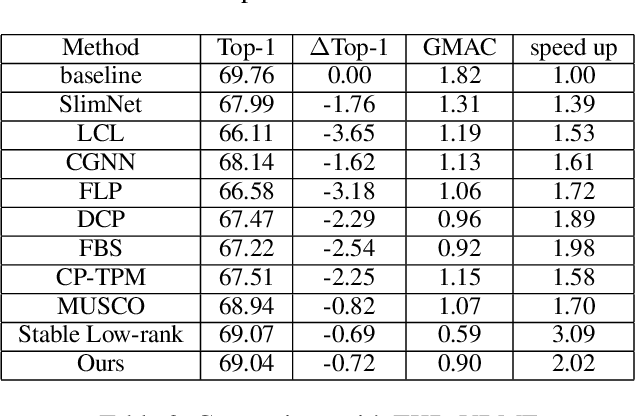


Tensor decomposition is one of the fundamental technique for model compression of deep convolution neural networks owing to its ability to reveal the latent relations among complex structures. However, most existing methods compress the networks layer by layer, which cannot provide a satisfactory solution to achieve global optimization. In this paper, we proposed a model reduction method to compress the pre-trained networks using low-rank tensor decomposition of the convolution layers. Our method is based on the optimization techniques to select the proper ranks of decomposed network layers. A new regularization method, called funnel function, is proposed to suppress the unimportant factors during the compression, so the proper ranks can be revealed much easier. The experimental results show that our algorithm can reduce more model parameters than other tensor compression methods. For ResNet18 with ImageNet2012, our reduced model can reach more than twi times speed up in terms of GMAC with merely 0.7% Top-1 accuracy drop, which outperforms most existing methods in both metrics.
LTD: Low Temperature Distillation for Robust Adversarial Training
Nov 03, 2021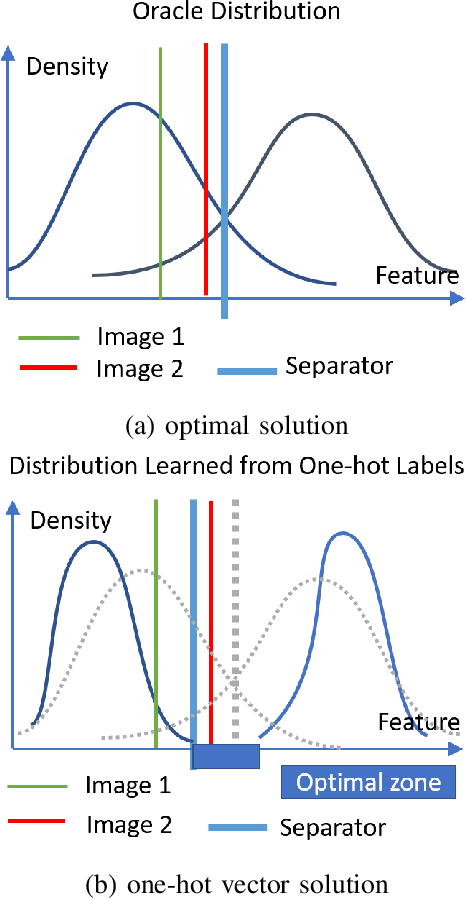
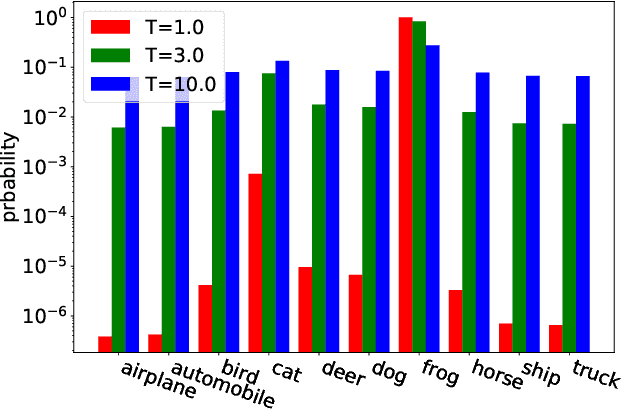
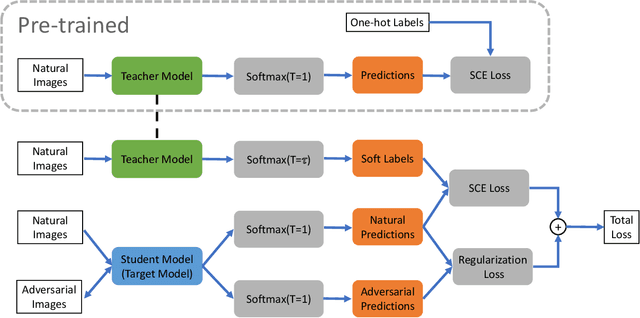
Adversarial training has been widely used to enhance the robustness of the neural network models against adversarial attacks. However, there still a notable gap between the nature accuracy and the robust accuracy. We found one of the reasons is the commonly used labels, one-hot vectors, hinder the learning process for image recognition. In this paper, we proposed a method, called Low Temperature Distillation (LTD), which is based on the knowledge distillation framework to generate the desired soft labels. Unlike the previous work, LTD uses relatively low temperature in the teacher model, and employs different, but fixed, temperatures for the teacher model and the student model. Moreover, we have investigated the methods to synergize the use of nature data and adversarial ones in LTD. Experimental results show that without extra unlabeled data, the proposed method combined with the previous work can achieve 57.72\% and 30.36\% robust accuracy on CIFAR-10 and CIFAR-100 dataset respectively, which is about 1.21\% improvement of the state-of-the-art methods in average.
Knowledge Distillation with Feature Maps for Image Classification
Dec 03, 2018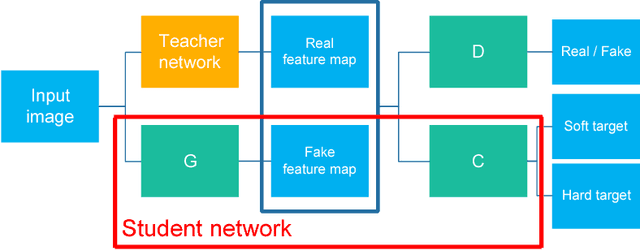


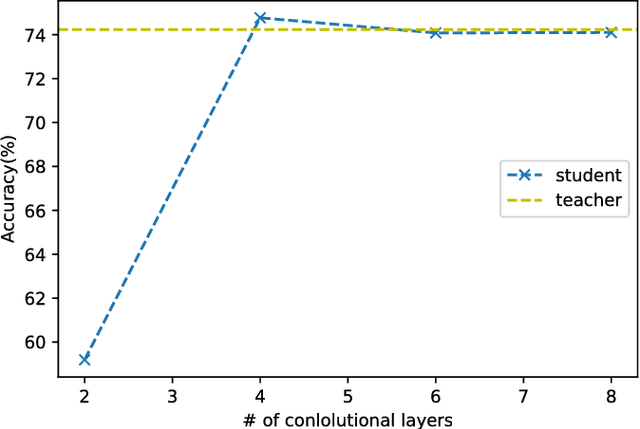
The model reduction problem that eases the computation costs and latency of complex deep learning architectures has received an increasing number of investigations owing to its importance in model deployment. One promising method is knowledge distillation (KD), which creates a fast-to-execute student model to mimic a large teacher network. In this paper, we propose a method, called KDFM (Knowledge Distillation with Feature Maps), which improves the effectiveness of KD by learning the feature maps from the teacher network. Two major techniques used in KDFM are shared classifier and generative adversarial network. Experimental results show that KDFM can use a four layers CNN to mimic DenseNet-40 and use MobileNet to mimic DenseNet-100. Both student networks have less than 1\% accuracy loss comparing to their teacher models for CIFAR-100 datasets. The student networks are 2-6 times faster than their teacher models for inference, and the model size of MobileNet is less than half of DenseNet-100's.
Escaping from Collapsing Modes in a Constrained Space
Aug 22, 2018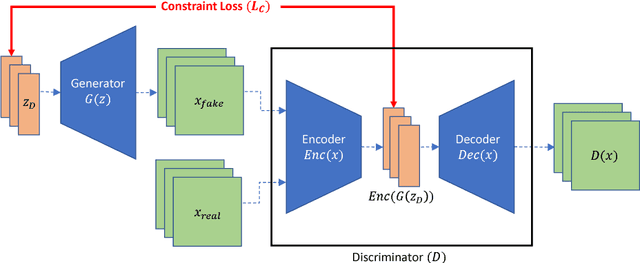

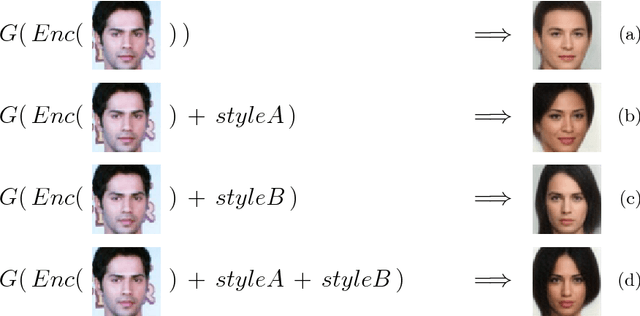
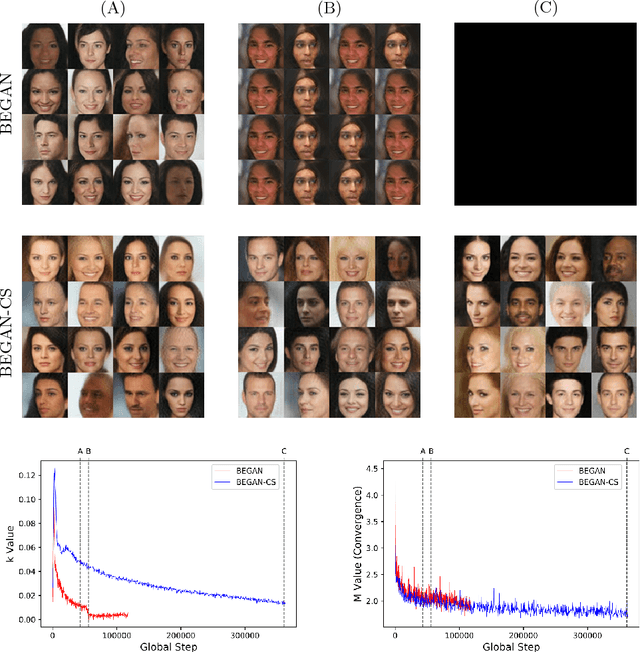
Generative adversarial networks (GANs) often suffer from unpredictable mode-collapsing during training. We study the issue of mode collapse of Boundary Equilibrium Generative Adversarial Network (BEGAN), which is one of the state-of-the-art generative models. Despite its potential of generating high-quality images, we find that BEGAN tends to collapse at some modes after a period of training. We propose a new model, called \emph{BEGAN with a Constrained Space} (BEGAN-CS), which includes a latent-space constraint in the loss function. We show that BEGAN-CS can significantly improve training stability and suppress mode collapse without either increasing the model complexity or degrading the image quality. Further, we visualize the distribution of latent vectors to elucidate the effect of latent-space constraint. The experimental results show that our method has additional advantages of being able to train on small datasets and to generate images similar to a given real image yet with variations of designated attributes on-the-fly.