 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation with Feature Maps for Image Classification
Dec 03, 2018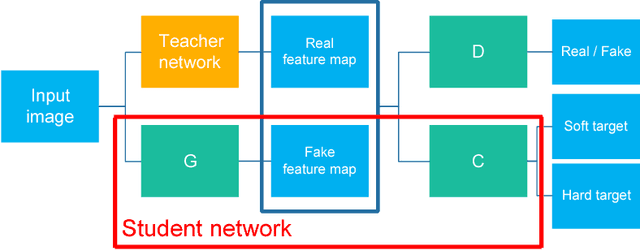


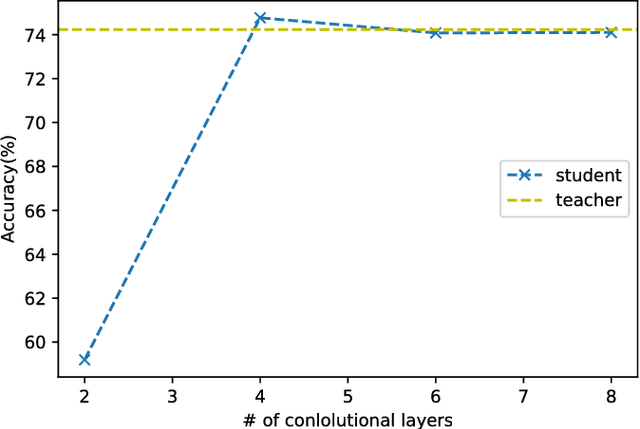
The model reduction problem that eases the computation costs and latency of complex deep learning architectures has received an increasing number of investigations owing to its importance in model deployment. One promising method is knowledge distillation (KD), which creates a fast-to-execute student model to mimic a large teacher network. In this paper, we propose a method, called KDFM (Knowledge Distillation with Feature Maps), which improves the effectiveness of KD by learning the feature maps from the teacher network. Two major techniques used in KDFM are shared classifier and generative adversarial network. Experimental results show that KDFM can use a four layers CNN to mimic DenseNet-40 and use MobileNet to mimic DenseNet-100. Both student networks have less than 1\% accuracy loss comparing to their teacher models for CIFAR-100 datasets. The student networks are 2-6 times faster than their teacher models for inference, and the model size of MobileNet is less than half of DenseNet-100's.