 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRingFormer: Rethinking Recurrent Transformer with Adaptive Level Signals
Feb 18, 2025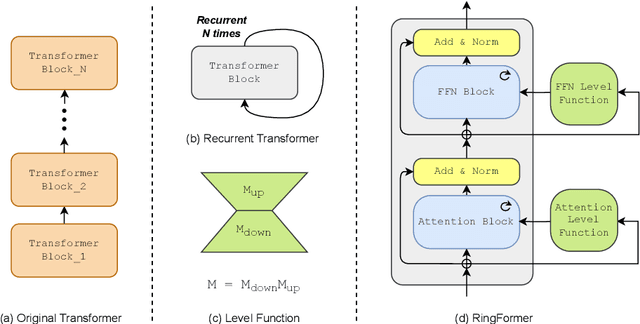

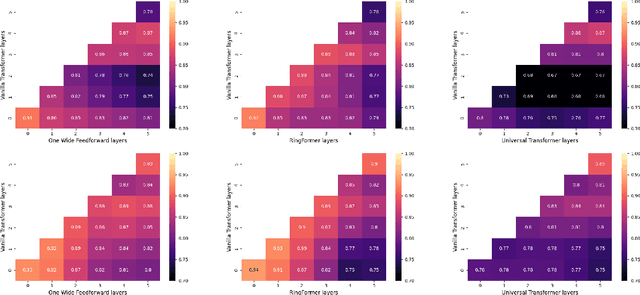
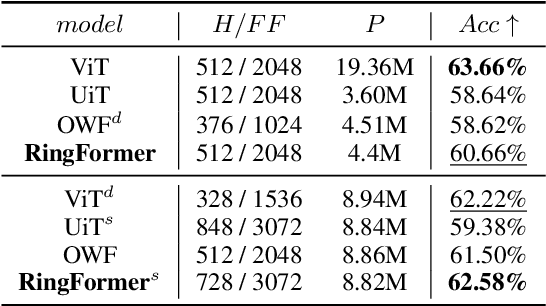
Transformers have achieved great success in effectively processing sequential data such as text. Their architecture consisting of several attention and feedforward blocks can model relations between elements of a sequence in parallel manner, which makes them very efficient to train and effective in sequence modeling. Even though they have shown strong performance in processing sequential data, the size of their parameters is considerably larger when compared to other architectures such as RNN and CNN based models. Therefore, several approaches have explored parameter sharing and recurrence in Transformer models to address their computational demands. However, such methods struggle to maintain high performance compared to the original transformer model. To address this challenge, we propose our novel approach, RingFormer, which employs one Transformer layer that processes input repeatedly in a circular, ring-like manner, while utilizing low-rank matrices to generate input-dependent level signals. This allows us to reduce the model parameters substantially while maintaining high performance in a variety of tasks such as translation and image classification, as validated in the experiments.