 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROOM: A Physics-Based Continuum Robot Simulator for Photorealistic Medical Datasets Generation
Sep 16, 2025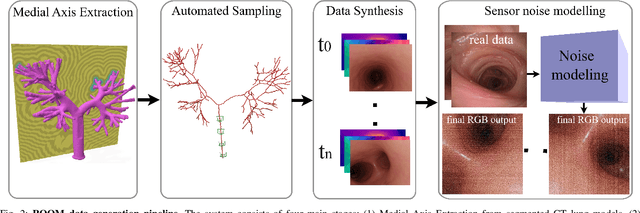



Continuum robots are advancing bronchoscopy procedures by accessing complex lung airways and enabling targeted interventions. However, their development is limited by the lack of realistic training and test environments: Real data is difficult to collect due to ethical constraints and patient safety concerns, and developing autonomy algorithms requires realistic imaging and physical feedback. We present ROOM (Realistic Optical Observation in Medicine), a comprehensive simulation framework designed for generating photorealistic bronchoscopy training data. By leveraging patient CT scans, our pipeline renders multi-modal sensor data including RGB images with realistic noise and light specularities, metric depth maps, surface normals, optical flow and point clouds at medically relevant scales. We validate the data generated by ROOM in two canonical tasks for medical robotics -- multi-view pose estimation and monocular depth estimation, demonstrating diverse challenges that state-of-the-art methods must overcome to transfer to these medical settings. Furthermore, we show that the data produced by ROOM can be used to fine-tune existing depth estimation models to overcome these challenges, also enabling other downstream applications such as navigation. We expect that ROOM will enable large-scale data generation across diverse patient anatomies and procedural scenarios that are challenging to capture in clinical settings. Code and data: https://github.com/iamsalvatore/room.
CrossSDF: 3D Reconstruction of Thin Structures From Cross-Sections
Dec 05, 2024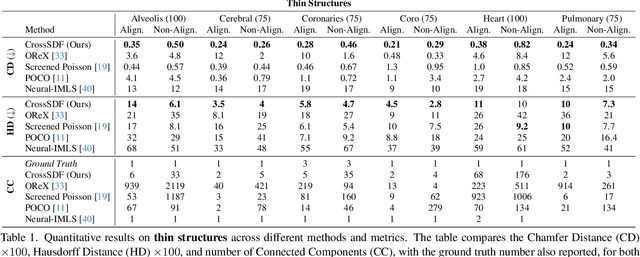
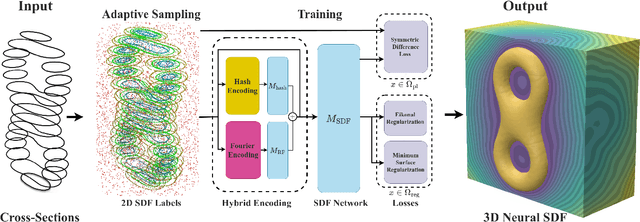
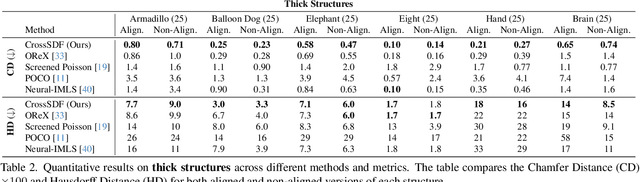

Reconstructing complex structures from planar cross-sections is a challenging problem, with wide-reaching applications in medical imaging, manufacturing, and topography. Out-of-the-box point cloud reconstruction methods can often fail due to the data sparsity between slicing planes, while current bespoke methods struggle to reconstruct thin geometric structures and preserve topological continuity. This is important for medical applications where thin vessel structures are present in CT and MRI scans. This paper introduces \method, a novel approach for extracting a 3D signed distance field from 2D signed distances generated from planar contours. Our approach makes the training of neural SDFs contour-aware by using losses designed for the case where geometry is known within 2D slices. Our results demonstrate a significant improvement over existing methods, effectively reconstructing thin structures and producing accurate 3D models without the interpolation artifacts or over-smoothing of prior approaches.
GeoGen: Geometry-Aware Generative Modeling via Signed Distance Functions
Jun 07, 2024
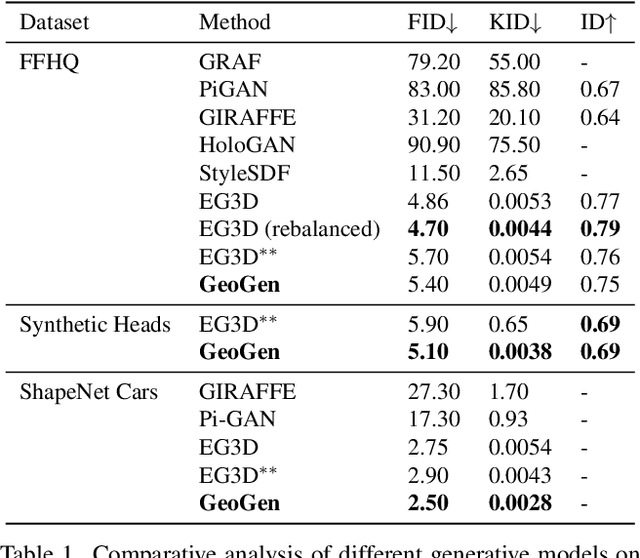

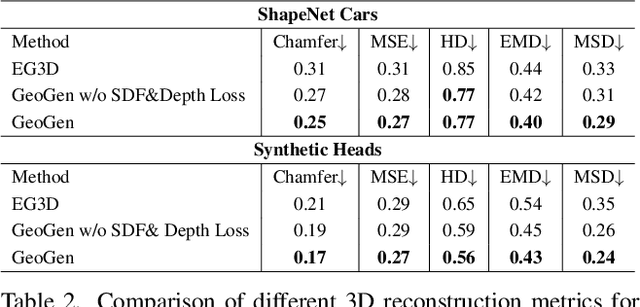
We introduce a new generative approach for synthesizing 3D geometry and images from single-view collections. Most existing approaches predict volumetric density to render multi-view consistent images. By employing volumetric rendering using neural radiance fields, they inherit a key limitation: the generated geometry is noisy and unconstrained, limiting the quality and utility of the output meshes. To address this issue, we propose GeoGen, a new SDF-based 3D generative model trained in an end-to-end manner. Initially, we reinterpret the volumetric density as a Signed Distance Function (SDF). This allows us to introduce useful priors to generate valid meshes. However, those priors prevent the generative model from learning details, limiting the applicability of the method to real-world scenarios. To alleviate that problem, we make the transformation learnable and constrain the rendered depth map to be consistent with the zero-level set of the SDF. Through the lens of adversarial training, we encourage the network to produce higher fidelity details on the output meshes. For evaluation, we introduce a synthetic dataset of human avatars captured from 360-degree camera angles, to overcome the challenges presented by real-world datasets, which often lack 3D consistency and do not cover all camera angles. Our experiments on multiple datasets show that GeoGen produces visually and quantitatively better geometry than the previous generative models based on neural radiance fields.