 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamais Vu: Exposing the Generalization Gap in Supervised Semantic Correspondence
Jun 09, 2025Semantic correspondence (SC) aims to establish semantically meaningful matches across different instances of an object category. We illustrate how recent supervised SC methods remain limited in their ability to generalize beyond sparsely annotated training keypoints, effectively acting as keypoint detectors. To address this, we propose a novel approach for learning dense correspondences by lifting 2D keypoints into a canonical 3D space using monocular depth estimation. Our method constructs a continuous canonical manifold that captures object geometry without requiring explicit 3D supervision or camera annotations. Additionally, we introduce SPair-U, an extension of SPair-71k with novel keypoint annotations, to better assess generalization. Experiments not only demonstrate that our model significantly outperforms supervised baselines on unseen keypoints, highlighting its effectiveness in learning robust correspondences, but that unsupervised baselines outperform supervised counterparts when generalized across different datasets.
Spatially-Adaptive Hash Encodings For Neural Surface Reconstruction
Dec 06, 2024Positional encodings are a common component of neural scene reconstruction methods, and provide a way to bias the learning of neural fields towards coarser or finer representations. Current neural surface reconstruction methods use a "one-size-fits-all" approach to encoding, choosing a fixed set of encoding functions, and therefore bias, across all scenes. Current state-of-the-art surface reconstruction approaches leverage grid-based multi-resolution hash encoding in order to recover high-detail geometry. We propose a learned approach which allows the network to choose its encoding basis as a function of space, by masking the contribution of features stored at separate grid resolutions. The resulting spatially adaptive approach allows the network to fit a wider range of frequencies without introducing noise. We test our approach on standard benchmark surface reconstruction datasets and achieve state-of-the-art performance on two benchmark datasets.
GeoGen: Geometry-Aware Generative Modeling via Signed Distance Functions
Jun 07, 2024
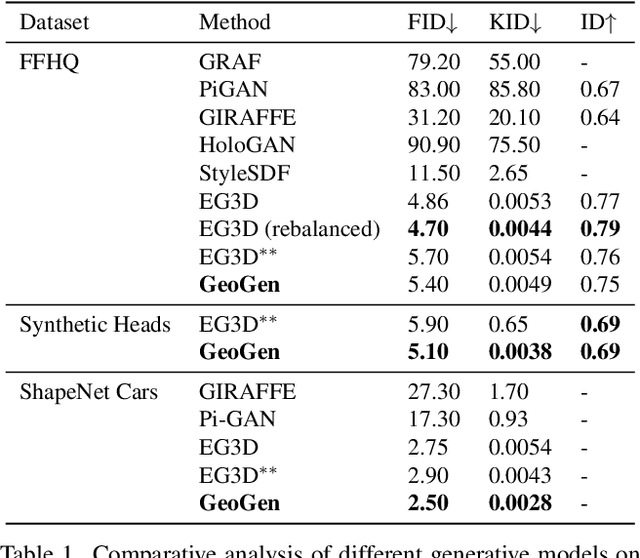

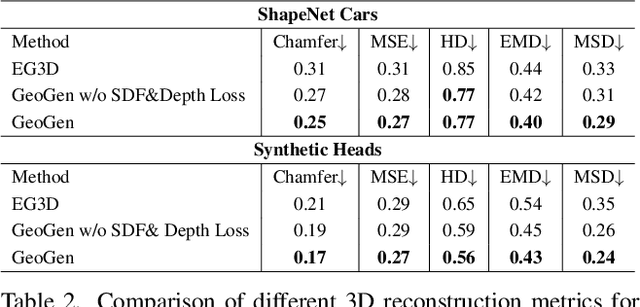
We introduce a new generative approach for synthesizing 3D geometry and images from single-view collections. Most existing approaches predict volumetric density to render multi-view consistent images. By employing volumetric rendering using neural radiance fields, they inherit a key limitation: the generated geometry is noisy and unconstrained, limiting the quality and utility of the output meshes. To address this issue, we propose GeoGen, a new SDF-based 3D generative model trained in an end-to-end manner. Initially, we reinterpret the volumetric density as a Signed Distance Function (SDF). This allows us to introduce useful priors to generate valid meshes. However, those priors prevent the generative model from learning details, limiting the applicability of the method to real-world scenarios. To alleviate that problem, we make the transformation learnable and constrain the rendered depth map to be consistent with the zero-level set of the SDF. Through the lens of adversarial training, we encourage the network to produce higher fidelity details on the output meshes. For evaluation, we introduce a synthetic dataset of human avatars captured from 360-degree camera angles, to overcome the challenges presented by real-world datasets, which often lack 3D consistency and do not cover all camera angles. Our experiments on multiple datasets show that GeoGen produces visually and quantitatively better geometry than the previous generative models based on neural radiance fields.
Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps
Dec 20, 2023



Recent progress in self-supervised representation learning has resulted in models that are capable of extracting image features that are not only effective at encoding image level, but also pixel-level, semantics. These features have been shown to be effective for dense visual semantic correspondence estimation, even outperforming fully-supervised methods. Nevertheless, current self-supervised approaches still fail in the presence of challenging image characteristics such as symmetries and repeated parts. To address these limitations, we propose a new approach for semantic correspondence estimation that supplements discriminative self-supervised features with 3D understanding via a weak geometric spherical prior. Compared to more involved 3D pipelines, our model only requires weak viewpoint information, and the simplicity of our spherical representation enables us to inject informative geometric priors into the model during training. We propose a new evaluation metric that better accounts for repeated part and symmetry-induced mistakes. We present results on the challenging SPair-71k dataset, where we show that our approach demonstrates is capable of distinguishing between symmetric views and repeated parts across many object categories, and also demonstrate that we can generalize to unseen classes on the AwA dataset.
Explicit Neural Surfaces: Learning Continuous Geometry With Deformation Fields
Jun 05, 2023We introduce Explicit Neural Surfaces (ENS), an efficient surface reconstruction method that learns an explicitly defined continuous surface from multiple views. We use a series of neural deformation fields to progressively transform a continuous input surface to a target shape. By sampling meshes as discrete surface proxies, we train the deformation fields through efficient differentiable rasterization, and attain a mesh-independent and smooth surface representation. By using Laplace-Beltrami eigenfunctions as an intrinsic positional encoding alongside standard extrinsic Fourier features, our approach can capture fine surface details. ENS trains 1 to 2 orders of magnitude faster and can extract meshes of higher quality compared to implicit representations, whilst maintaining competitive surface reconstruction performance and real-time capabilities. Finally, we apply our approach to learn a collection of objects in a single model, and achieve disentangled interpolations between different shapes, their surface details, and textures.
ViewNet: Unsupervised Viewpoint Estimation from Conditional Generation
Dec 01, 2022



Understanding the 3D world without supervision is currently a major challenge in computer vision as the annotations required to supervise deep networks for tasks in this domain are expensive to obtain on a large scale. In this paper, we address the problem of unsupervised viewpoint estimation. We formulate this as a self-supervised learning task, where image reconstruction provides the supervision needed to predict the camera viewpoint. Specifically, we make use of pairs of images of the same object at training time, from unknown viewpoints, to self-supervise training by combining the viewpoint information from one image with the appearance information from the other. We demonstrate that using a perspective spatial transformer allows efficient viewpoint learning, outperforming existing unsupervised approaches on synthetic data, and obtains competitive results on the challenging PASCAL3D+ dataset.
ViewNeRF: Unsupervised Viewpoint Estimation Using Category-Level Neural Radiance Fields
Dec 01, 2022We introduce ViewNeRF, a Neural Radiance Field-based viewpoint estimation method that learns to predict category-level viewpoints directly from images during training. While NeRF is usually trained with ground-truth camera poses, multiple extensions have been proposed to reduce the need for this expensive supervision. Nonetheless, most of these methods still struggle in complex settings with large camera movements, and are restricted to single scenes, i.e. they cannot be trained on a collection of scenes depicting the same object category. To address these issues, our method uses an analysis by synthesis approach, combining a conditional NeRF with a viewpoint predictor and a scene encoder in order to produce self-supervised reconstructions for whole object categories. Rather than focusing on high fidelity reconstruction, we target efficient and accurate viewpoint prediction in complex scenarios, e.g. 360{\deg} rotation on real data. Our model shows competitive results on synthetic and real datasets, both for single scenes and multi-instance collections.
Semi-supervised Viewpoint Estimation with Geometry-aware Conditional Generation
Apr 02, 2021

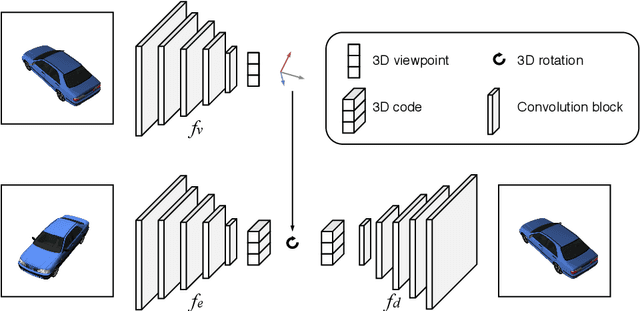

There is a growing interest in developing computer vision methods that can learn from limited supervision. In this paper, we consider the problem of learning to predict camera viewpoints, where obtaining ground-truth annotations are expensive and require special equipment, from a limited number of labeled images. We propose a semi-supervised viewpoint estimation method that can learn to infer viewpoint information from unlabeled image pairs, where two images differ by a viewpoint change. In particular our method learns to synthesize the second image by combining the appearance from the first one and viewpoint from the second one. We demonstrate that our method significantly improves the supervised techniques, especially in the low-label regime and outperforms the state-of-the-art semi-supervised methods.