 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Neural Representation for Scene Understanding
Apr 21, 2023A long-standing goal in scene understanding is to obtain interpretable and editable representations that can be directly constructed from a raw monocular RGB-D video, without requiring specialized hardware setup or priors. The problem is significantly more challenging in the presence of multiple moving and/or deforming objects. Traditional methods have approached the setup with a mix of simplifications, scene priors, pretrained templates, or known deformation models. The advent of neural representations, especially neural implicit representations and radiance fields, opens the possibility of end-to-end optimization to collectively capture geometry, appearance, and object motion. However, current approaches produce global scene encoding, assume multiview capture with limited or no motion in the scenes, and do not facilitate easy manipulation beyond novel view synthesis. In this work, we introduce a factored neural scene representation that can directly be learned from a monocular RGB-D video to produce object-level neural presentations with an explicit encoding of object movement (e.g., rigid trajectory) and/or deformations (e.g., nonrigid movement). We evaluate ours against a set of neural approaches on both synthetic and real data to demonstrate that the representation is efficient, interpretable, and editable (e.g., change object trajectory). The project webpage is available at: $\href{https://yushiangw.github.io/factorednerf/}{\text{link}}$.
Seeing Behind Objects for 3D Multi-Object Tracking in RGB-D Sequences
Dec 16, 2020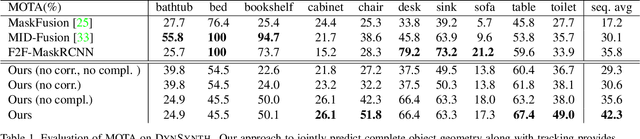
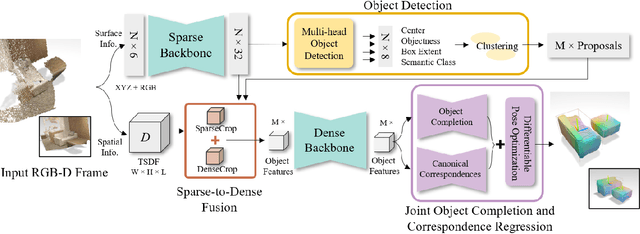

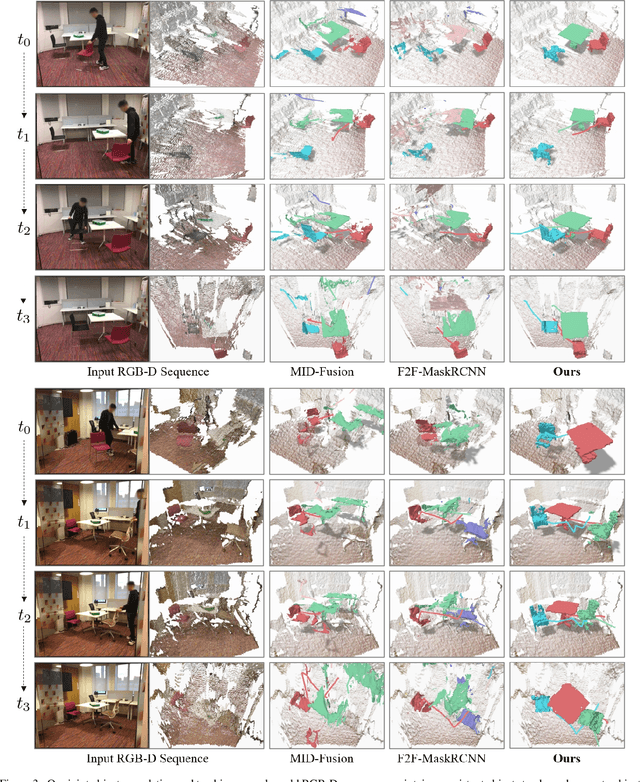
Multi-object tracking from RGB-D video sequences is a challenging problem due to the combination of changing viewpoints, motion, and occlusions over time. We observe that having the complete geometry of objects aids in their tracking, and thus propose to jointly infer the complete geometry of objects as well as track them, for rigidly moving objects over time. Our key insight is that inferring the complete geometry of the objects significantly helps in tracking. By hallucinating unseen regions of objects, we can obtain additional correspondences between the same instance, thus providing robust tracking even under strong change of appearance. From a sequence of RGB-D frames, we detect objects in each frame and learn to predict their complete object geometry as well as a dense correspondence mapping into a canonical space. This allows us to derive 6DoF poses for the objects in each frame, along with their correspondence between frames, providing robust object tracking across the RGB-D sequence. Experiments on both synthetic and real-world RGB-D data demonstrate that we achieve state-of-the-art performance on dynamic object tracking. Furthermore, we show that our object completion significantly helps tracking, providing an improvement of $6.5\%$ in mean MOTA.
A Meaning-based Statistical English Math Word Problem Solver
Jul 06, 2018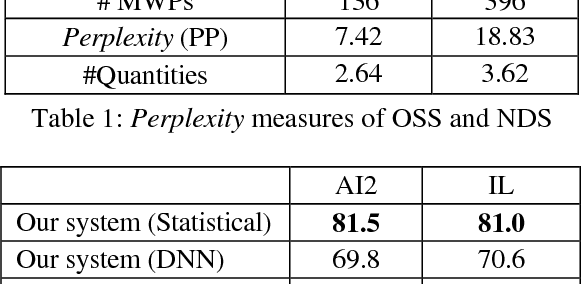
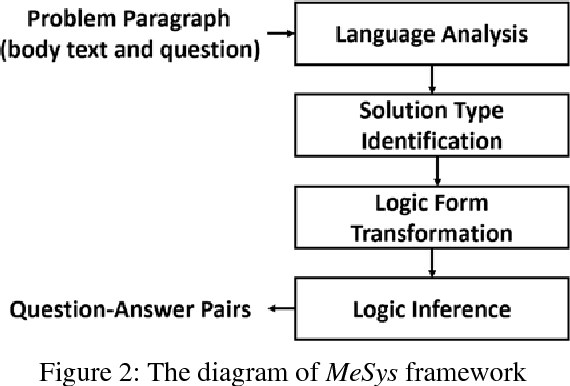
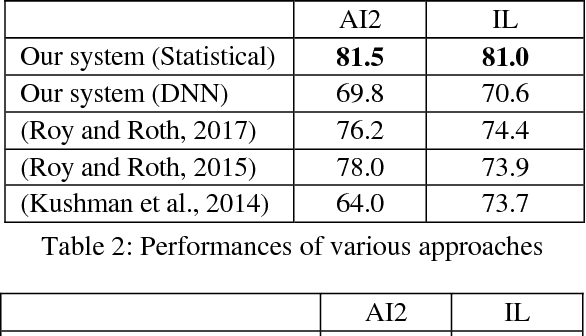
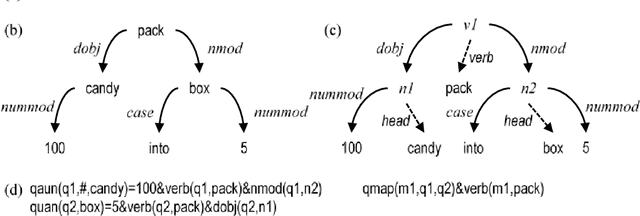
We introduce MeSys, a meaning-based approach, for solving English math word problems (MWPs) via understanding and reasoning in this paper. It first analyzes the text, transforms both body and question parts into their corresponding logic forms, and then performs inference on them. The associated context of each quantity is represented with proposed role-tags (e.g., nsubj, verb, etc.), which provides the flexibility for annotating an extracted math quantity with its associated context information (i.e., the physical meaning of this quantity). Statistical models are proposed to select the operator and operands. A noisy dataset is designed to assess if a solver solves MWPs mainly via understanding or mechanical pattern matching. Experimental results show that our approach outperforms existing systems on both benchmark datasets and the noisy dataset, which demonstrates that the proposed approach understands the meaning of each quantity in the text more.
SmartAnnotator: An Interactive Tool for Annotating RGBD Indoor Images
Mar 23, 2014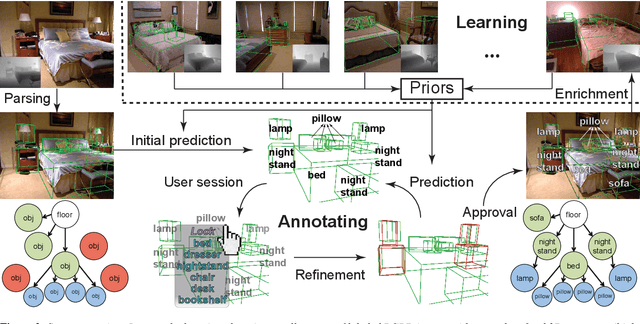

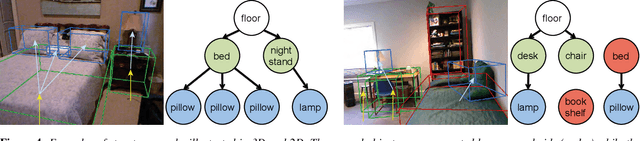

RGBD images with high quality annotations in the form of geometric (i.e., segmentation) and structural (i.e., how do the segments are mutually related in 3D) information provide valuable priors to a large number of scene and image manipulation applications. While it is now simple to acquire RGBD images, annotating them, automatically or manually, remains challenging especially in cluttered noisy environments. We present SmartAnnotator, an interactive system to facilitate annotating RGBD images. The system performs the tedious tasks of grouping pixels, creating potential abstracted cuboids, inferring object interactions in 3D, and comes up with various hypotheses. The user simply has to flip through a list of suggestions for segment labels, finalize a selection, and the system updates the remaining hypotheses. As objects are finalized, the process speeds up with fewer ambiguities to resolve. Further, as more scenes are annotated, the system makes better suggestions based on structural and geometric priors learns from the previous annotation sessions. We test our system on a large number of database scenes and report significant improvements over naive low-level annotation tools.