 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELM-BERT: A Transformer for Medium-sized Peptide Property Prediction
Dec 29, 2025Therapeutic peptides have emerged as a pivotal modality in modern drug discovery, occupying a chemically and topologically rich space. While accurate prediction of their physicochemical properties is essential for accelerating peptide development, existing molecular language models rely on representations that fail to capture this complexity. Atom-level SMILES notation generates long token sequences and obscures cyclic topology, whereas amino-acid-level representations cannot encode the diverse chemical modifications central to modern peptide design. To bridge this representational gap, the Hierarchical Editing Language for Macromolecules (HELM) offers a unified framework enabling precise description of both monomer composition and connectivity, making it a promising foundation for peptide language modeling. Here, we propose HELM-BERT, the first encoder-based peptide language model trained on HELM notation. Based on DeBERTa, HELM-BERT is specifically designed to capture hierarchical dependencies within HELM sequences. The model is pre-trained on a curated corpus of 39,079 chemically diverse peptides spanning linear and cyclic structures. HELM-BERT significantly outperforms state-of-the-art SMILES-based language models in downstream tasks, including cyclic peptide membrane permeability prediction and peptide-protein interaction prediction. These results demonstrate that HELM's explicit monomer- and topology-aware representations offer substantial data-efficiency advantages for modeling therapeutic peptides, bridging a long-standing gap between small-molecule and protein language models.
LoRA on the Go: Instance-level Dynamic LoRA Selection and Merging
Nov 10, 2025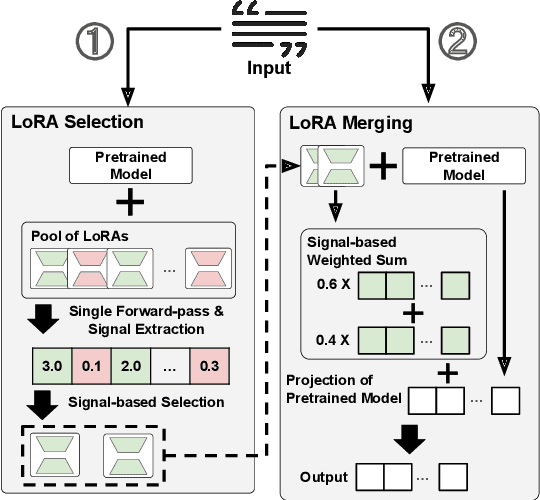
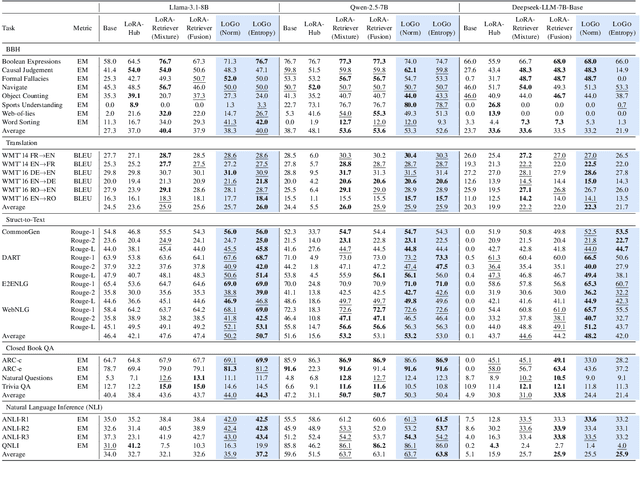
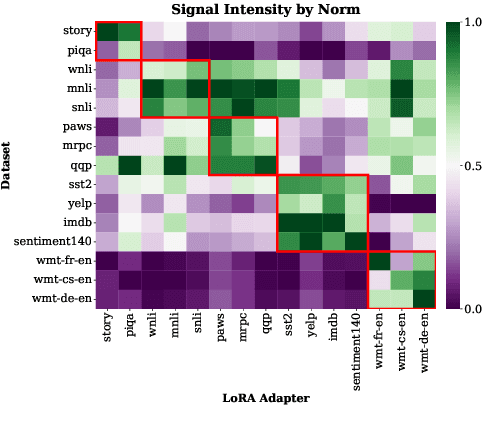
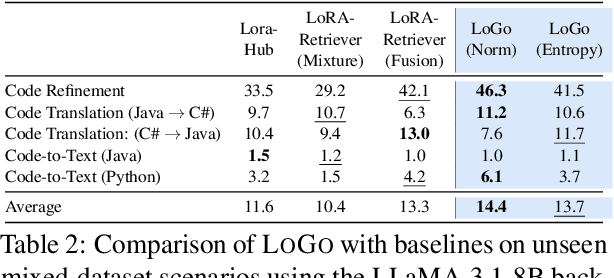
Low-Rank Adaptation (LoRA) has emerged as a parameter-efficient approach for fine-tuning large language models.However, conventional LoRA adapters are typically trained for a single task, limiting their applicability in real-world settings where inputs may span diverse and unpredictable domains. At inference time, existing approaches combine multiple LoRAs for improving performance on diverse tasks, while usually requiring labeled data or additional task-specific training, which is expensive at scale. In this work, we introduce LoRA on the Go (LoGo), a training-free framework that dynamically selects and merges adapters at the instance level without any additional requirements. LoGo leverages signals extracted from a single forward pass through LoRA adapters, to identify the most relevant adapters and determine their contributions on-the-fly. Across 5 NLP benchmarks, 27 datasets, and 3 model families, LoGo outperforms training-based baselines on some tasks upto a margin of 3.6% while remaining competitive on other tasks and maintaining inference throughput, highlighting its effectiveness and practicality.
GeoReg: Weight-Constrained Few-Shot Regression for Socio-Economic Estimation using LLM
Jul 17, 2025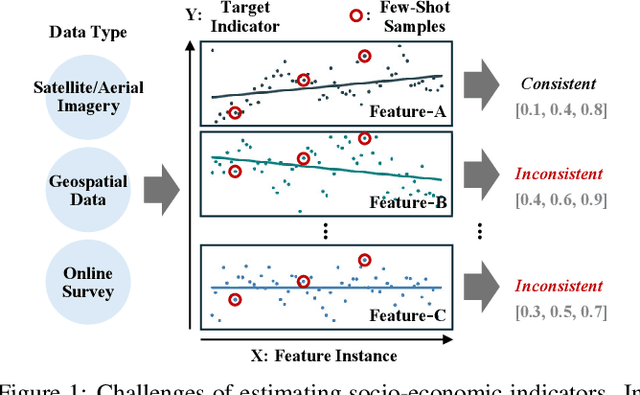


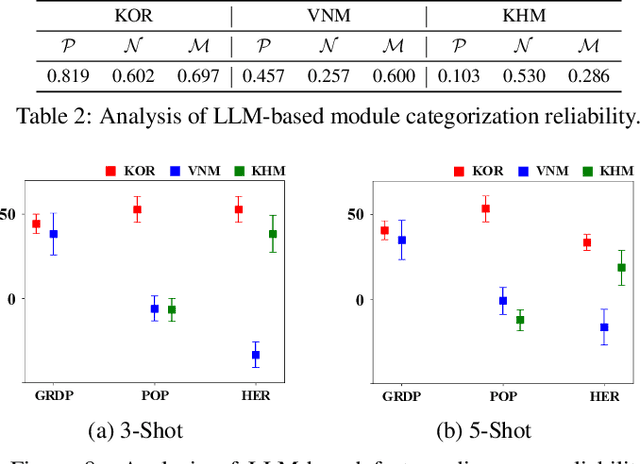
Socio-economic indicators like regional GDP, population, and education levels, are crucial to shaping policy decisions and fostering sustainable development. This research introduces GeoReg a regression model that integrates diverse data sources, including satellite imagery and web-based geospatial information, to estimate these indicators even for data-scarce regions such as developing countries. Our approach leverages the prior knowledge of large language model (LLM) to address the scarcity of labeled data, with the LLM functioning as a data engineer by extracting informative features to enable effective estimation in few-shot settings. Specifically, our model obtains contextual relationships between data features and the target indicator, categorizing their correlations as positive, negative, mixed, or irrelevant. These features are then fed into the linear estimator with tailored weight constraints for each category. To capture nonlinear patterns, the model also identifies meaningful feature interactions and integrates them, along with nonlinear transformations. Experiments across three countries at different stages of development demonstrate that our model outperforms baselines in estimating socio-economic indicators, even for low-income countries with limited data availability.
DualFair: Fair Representation Learning at Both Group and Individual Levels via Contrastive Self-supervision
Mar 15, 2023Algorithmic fairness has become an important machine learning problem, especially for mission-critical Web applications. This work presents a self-supervised model, called DualFair, that can debias sensitive attributes like gender and race from learned representations. Unlike existing models that target a single type of fairness, our model jointly optimizes for two fairness criteria - group fairness and counterfactual fairness - and hence makes fairer predictions at both the group and individual levels. Our model uses contrastive loss to generate embeddings that are indistinguishable for each protected group, while forcing the embeddings of counterfactual pairs to be similar. It then uses a self-knowledge distillation method to maintain the quality of representation for the downstream tasks. Extensive analysis over multiple datasets confirms the model's validity and further shows the synergy of jointly addressing two fairness criteria, suggesting the model's potential value in fair intelligent Web applications.
Self-explaining deep models with logic rule reasoning
Oct 18, 2022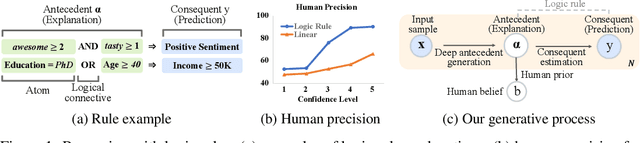

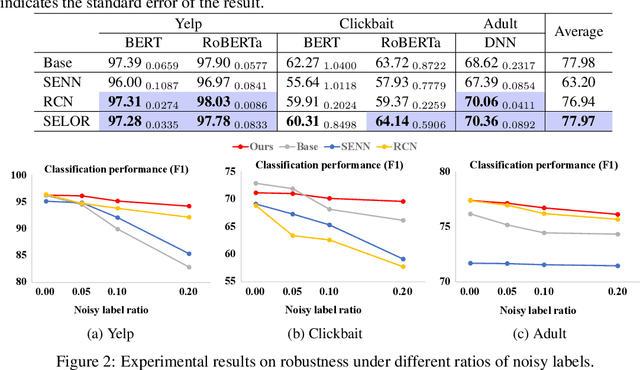
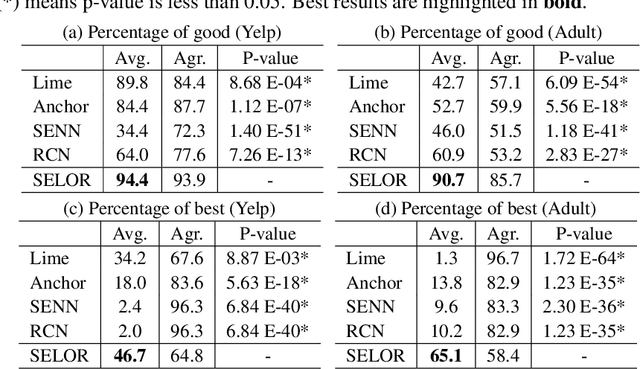
We present SELOR, a framework for integrating self-explaining capabilities into a given deep model to achieve both high prediction performance and human precision. By "human precision", we refer to the degree to which humans agree with the reasons models provide for their predictions. Human precision affects user trust and allows users to collaborate closely with the model. We demonstrate that logic rule explanations naturally satisfy human precision with the expressive power required for good predictive performance. We then illustrate how to enable a deep model to predict and explain with logic rules. Our method does not require predefined logic rule sets or human annotations and can be learned efficiently and easily with widely-used deep learning modules in a differentiable way. Extensive experiments show that our method gives explanations closer to human decision logic than other methods while maintaining the performance of deep learning models.
Elsa: Energy-based learning for semi-supervised anomaly detection
Mar 29, 2021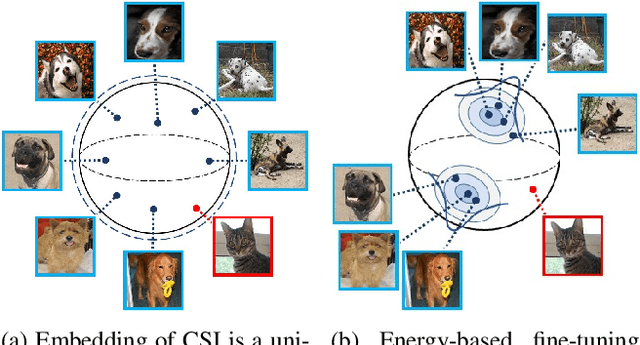

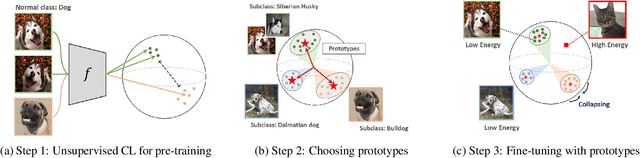

Anomaly detection aims at identifying deviant instances from the normal data distribution. Many advances have been made in the field, including the innovative use of unsupervised contrastive learning. However, existing methods generally assume clean training data and are limited when the data contain unknown anomalies. This paper presents Elsa, a novel semi-supervised anomaly detection approach that unifies the concept of energy-based models with unsupervised contrastive learning. Elsa instills robustness against any data contamination by a carefully designed fine-tuning step based on the new energy function that forces the normal data to be divided into classes of prototypes. Experiments on multiple contamination scenarios show the proposed model achieves SOTA performance. Extensive analyses also verify the contribution of each component in the proposed model. Beyond the experiments, we also offer a theoretical interpretation of why contrastive learning alone cannot detect anomalies under data contamination.