 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-Adaptor: Text Embedding Customization for Information Retrieval
Paper and Code
Oct 12, 2023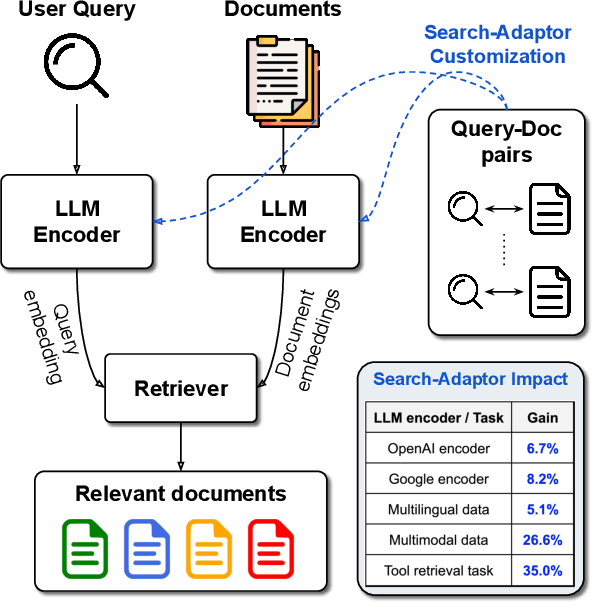
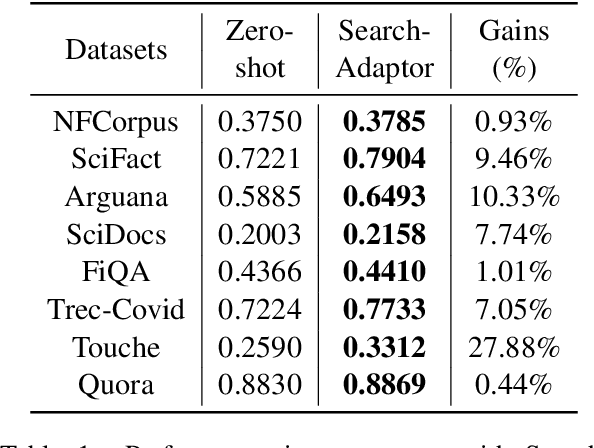


Text embeddings extracted by pre-trained Large Language Models (LLMs) have significant potential to improve information retrieval and search. Beyond the zero-shot setup in which they are being conventionally used, being able to take advantage of the information from the relevant query-corpus paired data has the power to further boost the LLM capabilities. In this paper, we propose a novel method, Search-Adaptor, for customizing LLMs for information retrieval in an efficient and robust way. Search-Adaptor modifies the original text embedding generated by pre-trained LLMs, and can be integrated with any LLM, including those only available via APIs. On multiple real-world English and multilingual retrieval datasets, we show consistent and significant performance benefits for Search-Adaptor -- e.g., more than 5.2% improvements over the Google Embedding APIs in nDCG@10 averaged over 13 BEIR datasets.