 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on VAEs: From Bayes' Rule to Lossless Compression
Jun 30, 2020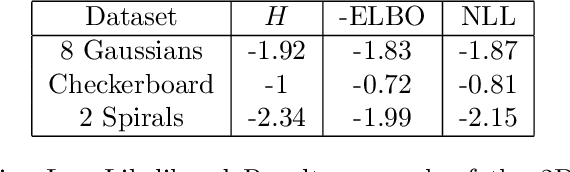

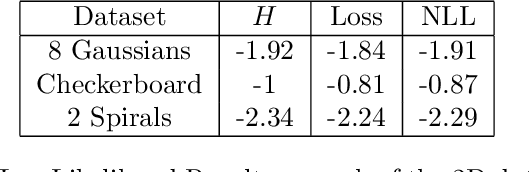
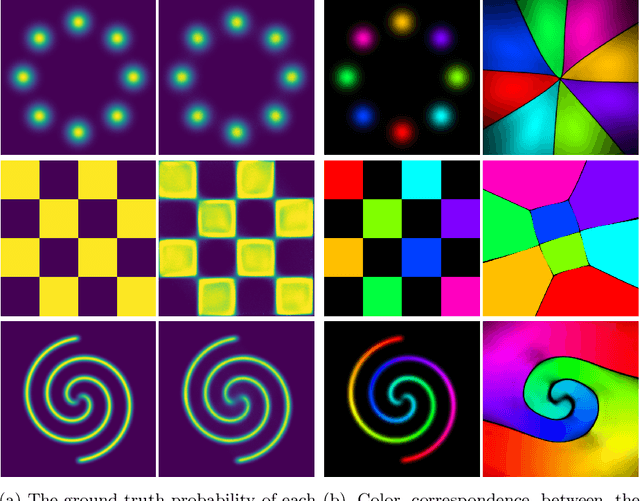
The Variational Auto-Encoder (VAE) is a simple, efficient, and popular deep maximum likelihood model. Though usage of VAEs is widespread, the derivation of the VAE is not as widely understood. In this tutorial, we will provide an overview of the VAE and a tour through various derivations and interpretations of the VAE objective. From a probabilistic standpoint, we will examine the VAE through the lens of Bayes' Rule, importance sampling, and the change-of-variables formula. From an information theoretic standpoint, we will examine the VAE through the lens of lossless compression and transmission through a noisy channel. We will then identify two common misconceptions over the VAE formulation and their practical consequences. Finally, we will visualize the capabilities and limitations of VAEs using a code example (with an accompanying Jupyter notebook) on toy 2D data.
Adversarial point perturbations on 3D objects
Aug 16, 2019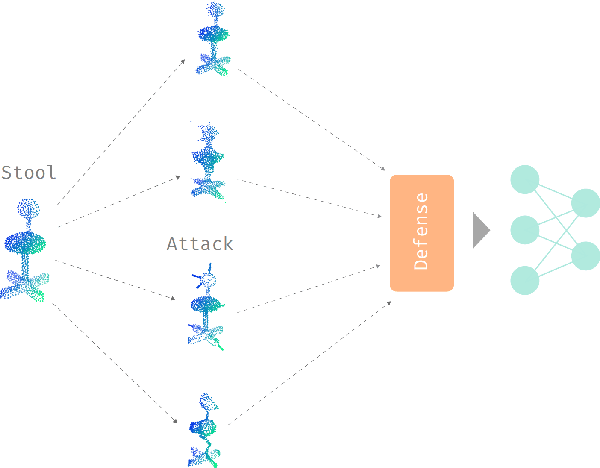
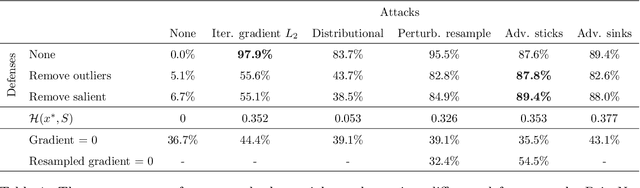
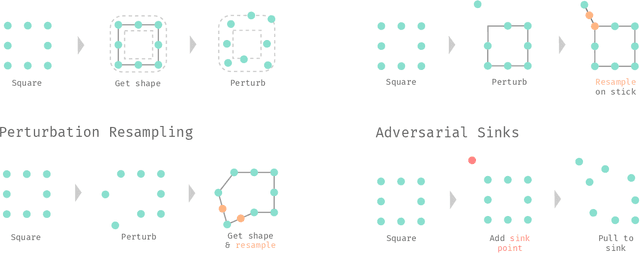
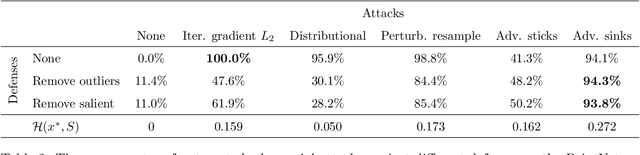
The importance of training robust neural network grows as 3D data is increasingly utilized in deep learning for vision tasks, like autonomous driving. We examine this problem from the perspective of the attacker, which is necessary in understanding how neural networks can be exploited, and thus defended. More specifically, we propose adversarial attacks based on solving different optimization problems, like minimizing the perceptibility of our generated adversarial examples, or maintaining a uniform density distribution of points across the adversarial object surfaces. Our four proposed algorithms for attacking 3D point cloud classification are all highly successful on existing neural networks, and we find that some of them are even effective against previously proposed point removal defenses.
Extending Adversarial Attacks and Defenses to Deep 3D Point Cloud Classifiers
Jan 10, 2019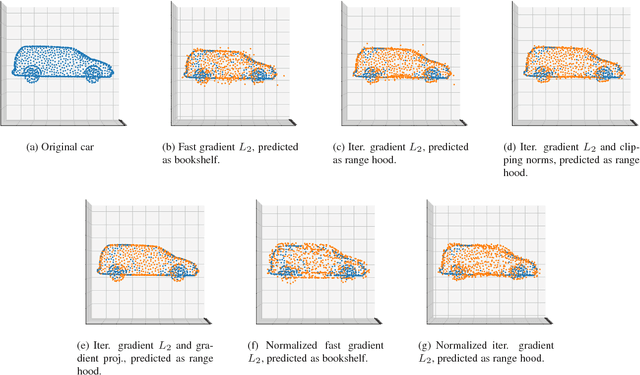
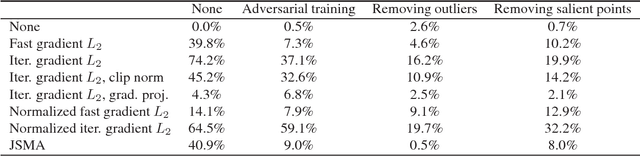
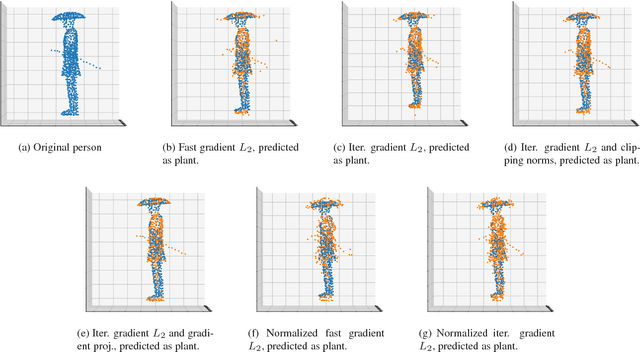

3D object classification and segmentation using deep neural networks has been extremely successful. As the problem of identifying 3D objects has many safety-critical applications, the neural networks have to be robust against adversarial changes to the input data set. There is a growing body of research on generating human-imperceptible adversarial attacks and defenses against them in the 2D image classification domain. However, 3D objects have various differences with 2D images, and this specific domain has not been rigorously studied so far. We present a preliminary evaluation of adversarial attacks on deep 3D point cloud classifiers, namely PointNet and PointNet++, by evaluating both white-box and black-box adversarial attacks that were proposed for 2D images and extending those attacks to reduce the perceptibility of the perturbations in 3D space. We also show the high effectiveness of simple defenses against those attacks by proposing new defenses that exploit the unique structure of 3D point clouds. Finally, we attempt to explain the effectiveness of the defenses through the intrinsic structures of both the point clouds and the neural network architectures. Overall, we find that networks that process 3D point cloud data are weak to adversarial attacks, but they are also more easily defensible compared to 2D image classifiers. Our investigation will provide the groundwork for future studies on improving the robustness of deep neural networks that handle 3D data.
Adversarial Defense by Stratified Convolutional Sparse Coding
Nov 30, 2018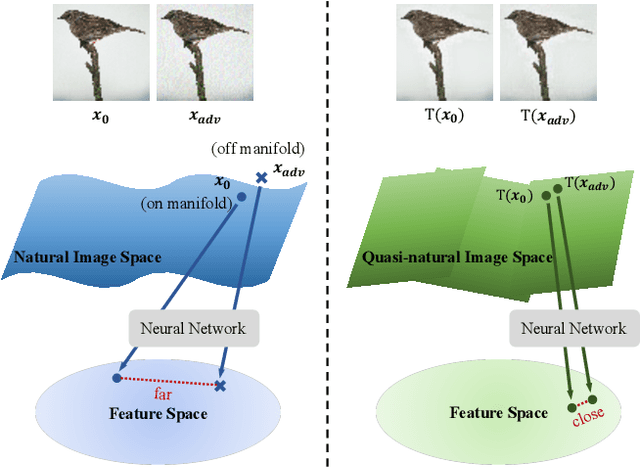
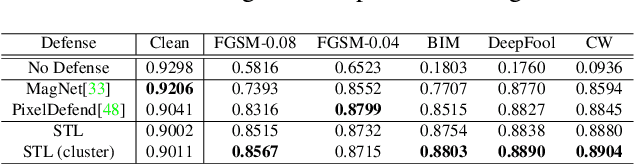
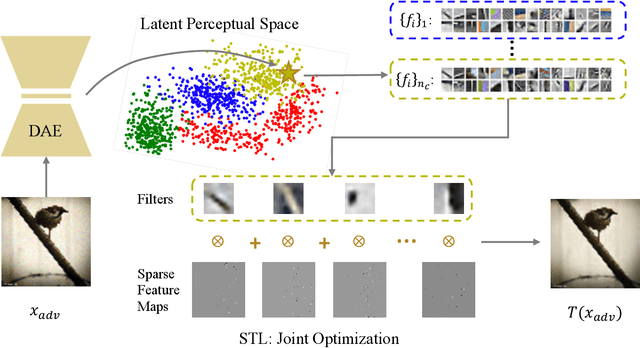
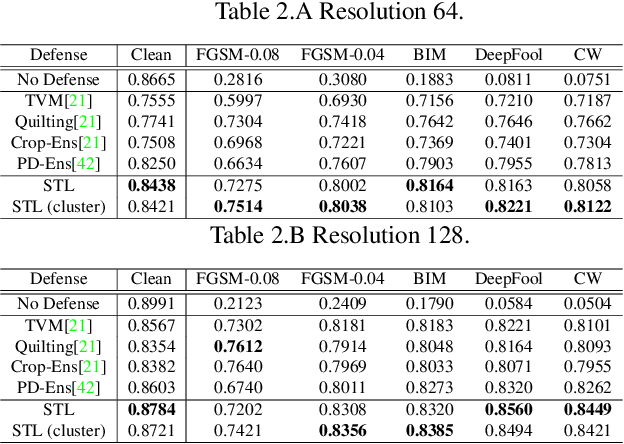
We propose an adversarial defense method that achieves state-of-the-art performance among attack-agnostic adversarial defense methods while also maintaining robustness to input resolution, scale of adversarial perturbation, and scale of dataset size. Based on convolutional sparse coding, we construct a stratified low-dimensional quasi-natural image space that faithfully approximates the natural image space while also removing adversarial perturbations. We introduce a novel Sparse Transformation Layer (STL) in between the input image and the first layer of the neural network to efficiently project images into our quasi-natural image space. Our experiments show state-of-the-art performance of our method compared to other attack-agnostic adversarial defense methods in various adversarial settings.
Deep Functional Dictionaries: Learning Consistent Semantic Structures on 3D Models from Functions
Oct 25, 2018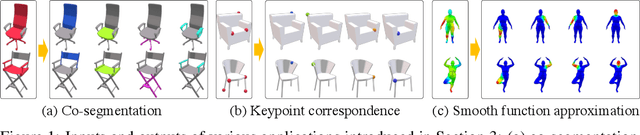

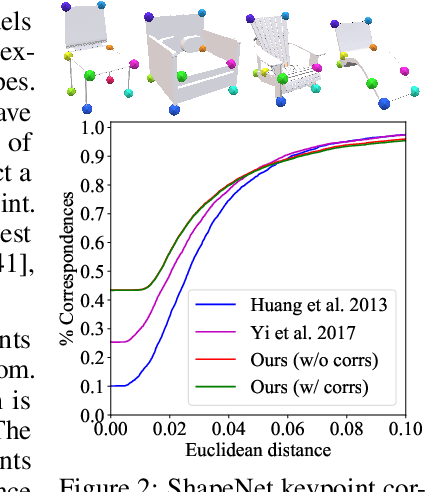

Various 3D semantic attributes such as segmentation masks, geometric features, keypoints, and materials can be encoded as per-point probe functions on 3D geometries. Given a collection of related 3D shapes, we consider how to jointly analyze such probe functions over different shapes, and how to discover common latent structures using a neural network --- even in the absence of any correspondence information. Our network is trained on point cloud representations of shape geometry and associated semantic functions on that point cloud. These functions express a shared semantic understanding of the shapes but are not coordinated in any way. For example, in a segmentation task, the functions can be indicator functions of arbitrary sets of shape parts, with the particular combination involved not known to the network. Our network is able to produce a small dictionary of basis functions for each shape, a dictionary whose span includes the semantic functions provided for that shape. Even though our shapes have independent discretizations and no functional correspondences are provided, the network is able to generate latent bases, in a consistent order, that reflect the shared semantic structure among the shapes. We demonstrate the effectiveness of our technique in various segmentation and keypoint selection applications.
SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation
Nov 23, 2017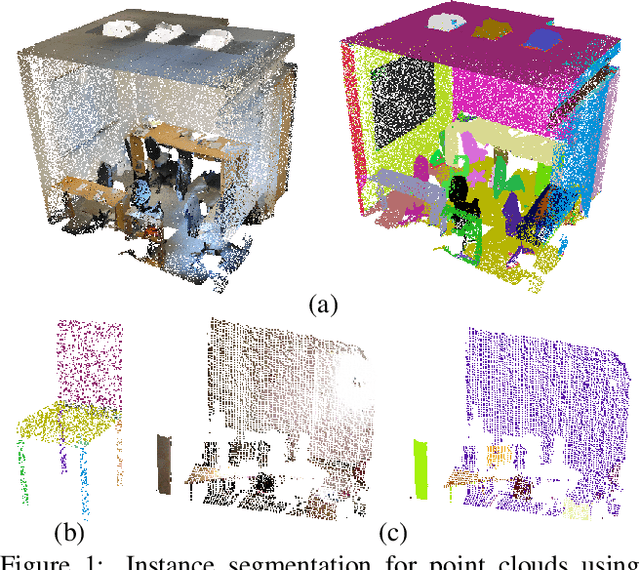

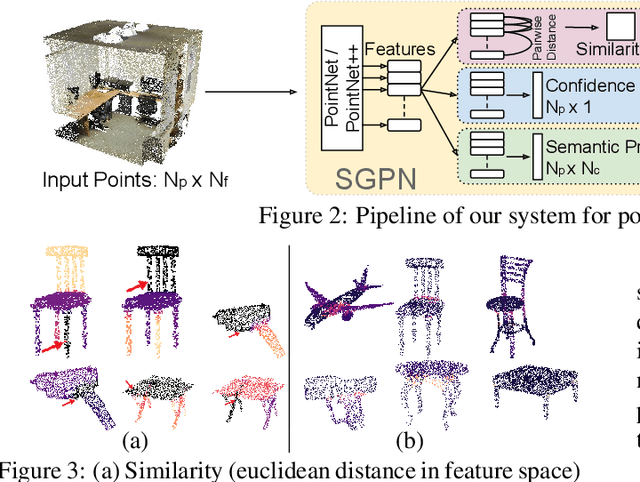

We introduce Similarity Group Proposal Network (SGPN), a simple and intuitive deep learning framework for 3D object instance segmentation on point clouds. SGPN uses a single network to predict point grouping proposals and a corresponding semantic class for each proposal, from which we can directly extract instance segmentation results. Important to the effectiveness of SGPN is its novel representation of 3D instance segmentation results in the form of a similarity matrix that indicates the similarity between each pair of points in embedded feature space, thus producing an accurate grouping proposal for each point. To the best of our knowledge, SGPN is the first framework to learn 3D instance-aware semantic segmentation on point clouds. Experimental results on various 3D scenes show the effectiveness of our method on 3D instance segmentation, and we also evaluate the capability of SGPN to improve 3D object detection and semantic segmentation results. We also demonstrate its flexibility by seamlessly incorporating 2D CNN features into the framework to boost performance.
Production-Level Facial Performance Capture Using Deep Convolutional Neural Networks
Jun 02, 2017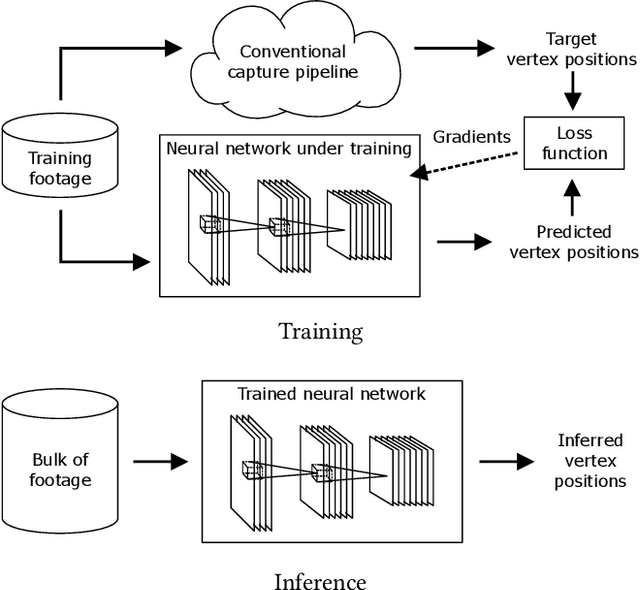

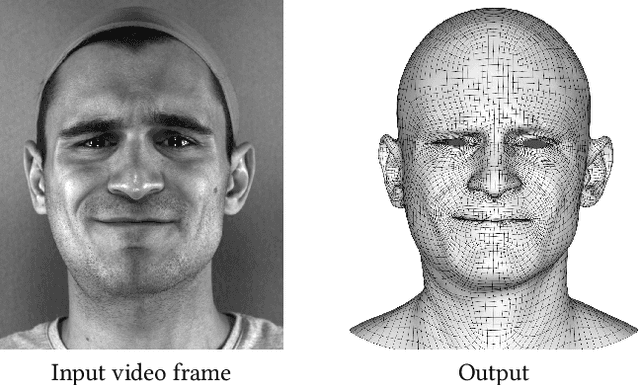

We present a real-time deep learning framework for video-based facial performance capture -- the dense 3D tracking of an actor's face given a monocular video. Our pipeline begins with accurately capturing a subject using a high-end production facial capture pipeline based on multi-view stereo tracking and artist-enhanced animations. With 5-10 minutes of captured footage, we train a convolutional neural network to produce high-quality output, including self-occluded regions, from a monocular video sequence of that subject. Since this 3D facial performance capture is fully automated, our system can drastically reduce the amount of labor involved in the development of modern narrative-driven video games or films involving realistic digital doubles of actors and potentially hours of animated dialogue per character. We compare our results with several state-of-the-art monocular real-time facial capture techniques and demonstrate compelling animation inference in challenging areas such as eyes and lips.