 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025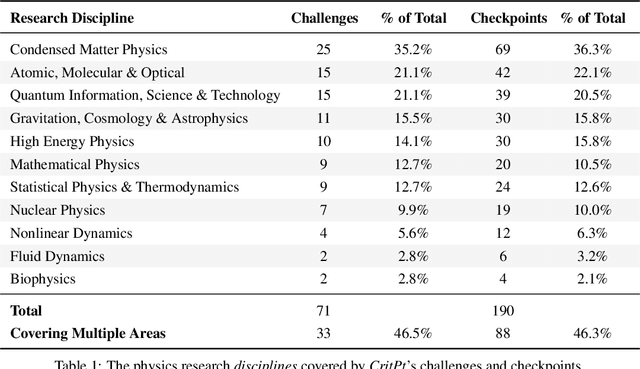
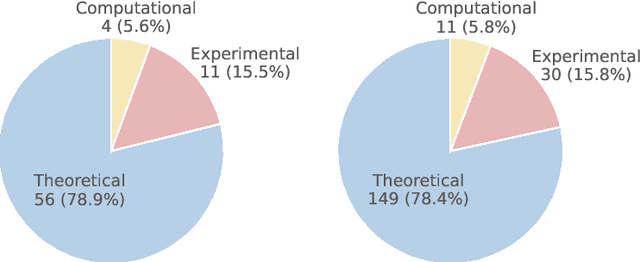
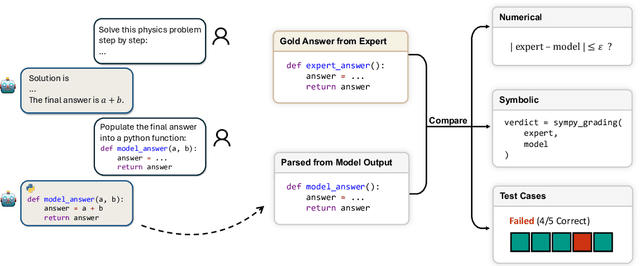

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
The Benefits of Being Distributional: Small-Loss Bounds for Reinforcement Learning
May 25, 2023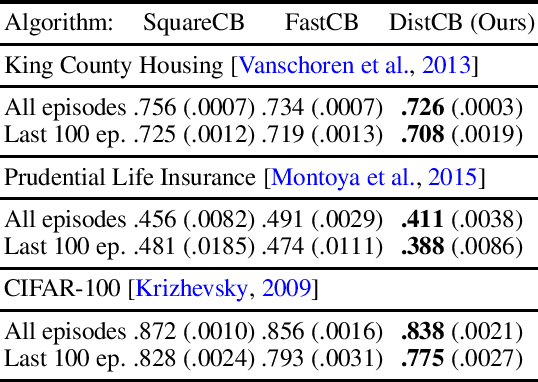
While distributional reinforcement learning (RL) has demonstrated empirical success, the question of when and why it is beneficial has remained unanswered. In this work, we provide one explanation for the benefits of distributional RL through the lens of small-loss bounds, which scale with the instance-dependent optimal cost. If the optimal cost is small, our bounds are stronger than those from non-distributional approaches. As warmup, we show that learning the cost distribution leads to small-loss regret bounds in contextual bandits (CB), and we find that distributional CB empirically outperforms the state-of-the-art on three challenging tasks. For online RL, we propose a distributional version-space algorithm that constructs confidence sets using maximum likelihood estimation, and we prove that it achieves small-loss regret in the tabular MDPs and enjoys small-loss PAC bounds in latent variable models. Building on similar insights, we propose a distributional offline RL algorithm based on the pessimism principle and prove that it enjoys small-loss PAC bounds, which exhibit a novel robustness property. For both online and offline RL, our results provide the first theoretical benefits of learning distributions even when we only need the mean for making decisions.
DiffuseExpand: Expanding dataset for 2D medical image segmentation using diffusion models
Apr 26, 2023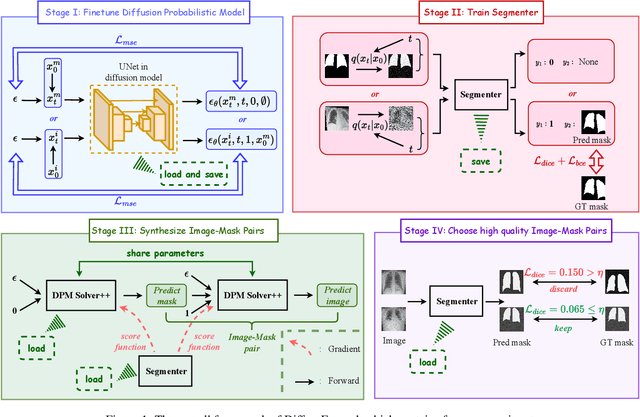



Dataset expansion can effectively alleviate the problem of data scarcity for medical image segmentation, due to privacy concerns and labeling difficulties. However, existing expansion algorithms still face great challenges due to their inability of guaranteeing the diversity of synthesized images with paired segmentation masks. In recent years, Diffusion Probabilistic Models (DPMs) have shown powerful image synthesis performance, even better than Generative Adversarial Networks. Based on this insight, we propose an approach called DiffuseExpand for expanding datasets for 2D medical image segmentation using DPM, which first samples a variety of masks from Gaussian noise to ensure the diversity, and then synthesizes images to ensure the alignment of images and masks. After that, DiffuseExpand chooses high-quality samples to further enhance the effectiveness of data expansion. Our comparison and ablation experiments on COVID-19 and CGMH Pelvis datasets demonstrate the effectiveness of DiffuseExpand. Our code is released at https://anonymous.4open.science/r/DiffuseExpand.
Learning to recognize Abnormalities in Chest X-Rays with Location-Aware Dense Networks
Mar 12, 2018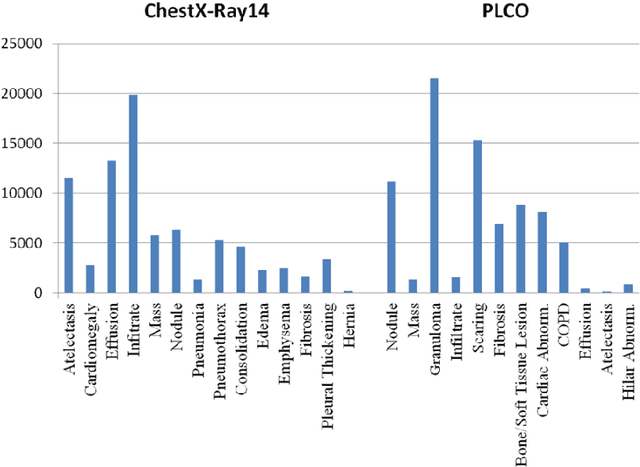
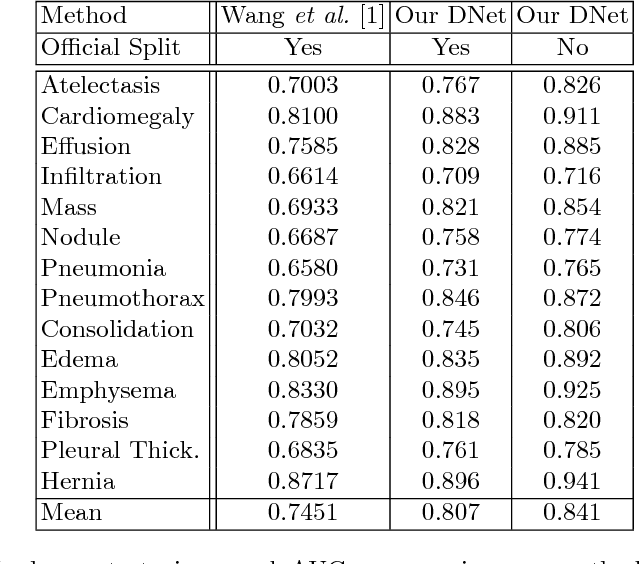
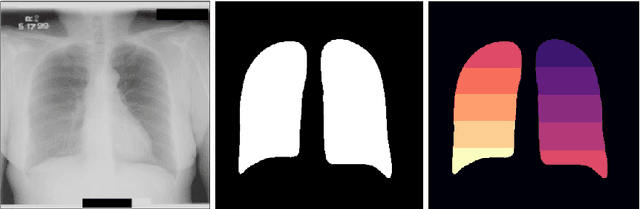

Chest X-ray is the most common medical imaging exam used to assess multiple pathologies. Automated algorithms and tools have the potential to support the reading workflow, improve efficiency, and reduce reading errors. With the availability of large scale data sets, several methods have been proposed to classify pathologies on chest X-ray images. However, most methods report performance based on random image based splitting, ignoring the high probability of the same patient appearing in both training and test set. In addition, most methods fail to explicitly incorporate the spatial information of abnormalities or utilize the high resolution images. We propose a novel approach based on location aware Dense Networks (DNetLoc), whereby we incorporate both high-resolution image data and spatial information for abnormality classification. We evaluate our method on the largest data set reported in the community, containing a total of 86,876 patients and 297,541 chest X-ray images. We achieve (i) the best average AUC score for published training and test splits on the single benchmarking data set (ChestX-Ray14), and (ii) improved AUC scores when the pathology location information is explicitly used. To foster future research we demonstrate the limitations of the current benchmarking setup and provide new reference patient-wise splits for the used data sets. This could support consistent and meaningful benchmarking of future methods on the largest publicly available data sets.
Learning to Prune Filters in Convolutional Neural Networks
Jan 23, 2018
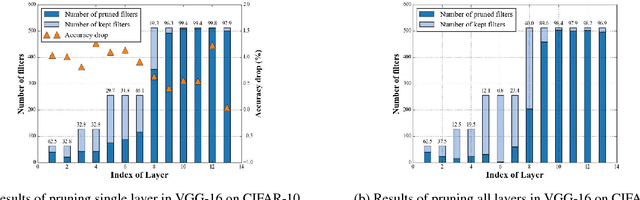

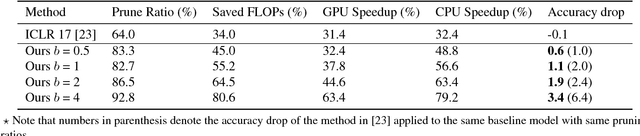
Many state-of-the-art computer vision algorithms use large scale convolutional neural networks (CNNs) as basic building blocks. These CNNs are known for their huge number of parameters, high redundancy in weights, and tremendous computing resource consumptions. This paper presents a learning algorithm to simplify and speed up these CNNs. Specifically, we introduce a "try-and-learn" algorithm to train pruning agents that remove unnecessary CNN filters in a data-driven way. With the help of a novel reward function, our agents removes a significant number of filters in CNNs while maintaining performance at a desired level. Moreover, this method provides an easy control of the tradeoff between network performance and its scale. Per- formance of our algorithm is validated with comprehensive pruning experiments on several popular CNNs for visual recognition and semantic segmentation tasks.
Scene Labeling using Gated Recurrent Units with Explicit Long Range Conditioning
Mar 28, 2017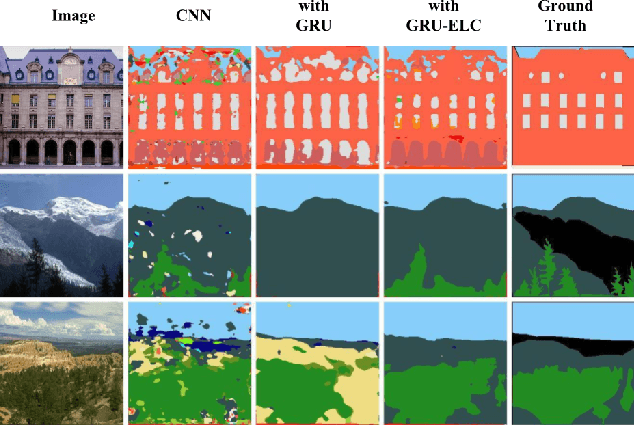
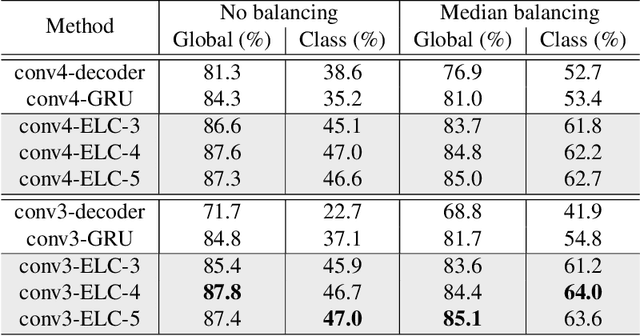
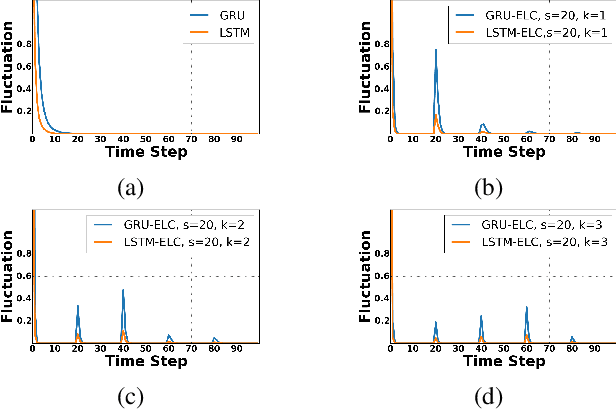
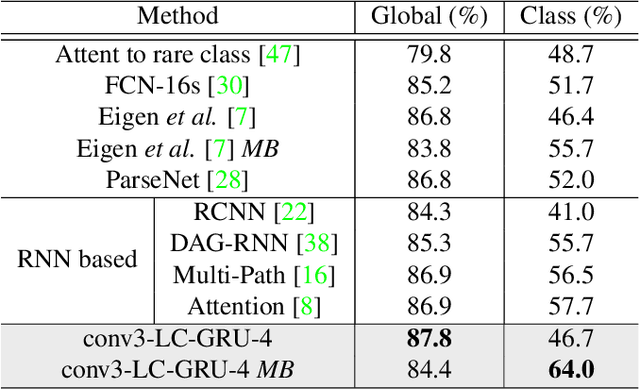
Recurrent neural network (RNN), as a powerful contextual dependency modeling framework, has been widely applied to scene labeling problems. However, this work shows that directly applying traditional RNN architectures, which unfolds a 2D lattice grid into a sequence, is not sufficient to model structure dependencies in images due to the "impact vanishing" problem. First, we give an empirical analysis about the "impact vanishing" problem. Then, a new RNN unit named Recurrent Neural Network with explicit long range conditioning (RNN-ELC) is designed to alleviate this problem. A novel neural network architecture is built for scene labeling tasks where one of the variants of the new RNN unit, Gated Recurrent Unit with Explicit Long-range Conditioning (GRU-ELC), is used to model multi scale contextual dependencies in images. We validate the use of GRU-ELC units with state-of-the-art performance on three standard scene labeling datasets. Comprehensive experiments demonstrate that the new GRU-ELC unit benefits scene labeling problem a lot as it can encode longer contextual dependencies in images more effectively than traditional RNN units.