 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Re-Identification by Multiple Views Knowledge Distillation
Paper and Code
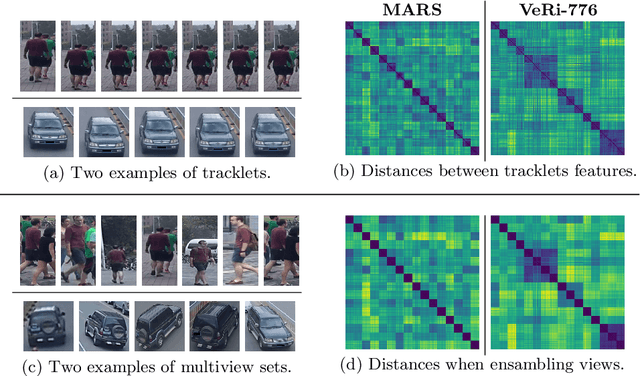
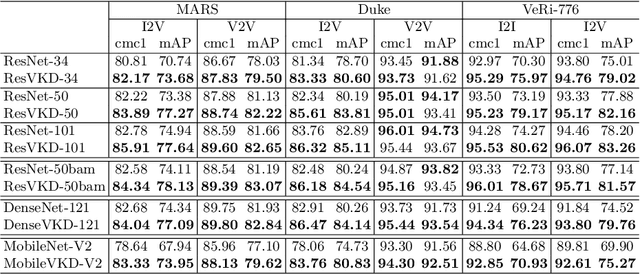

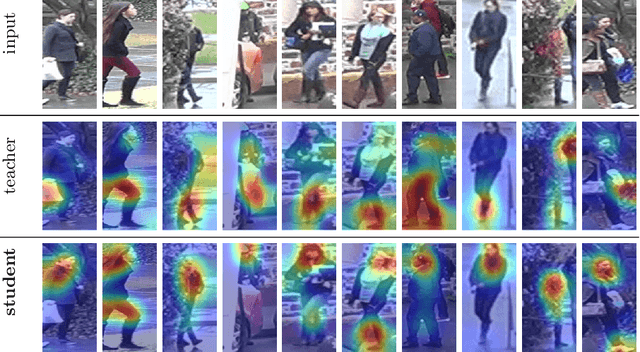
To achieve robustness in Re-Identification, standard methods leverage tracking information in a Video-To-Video fashion. However, these solutions face a large drop in performance for single image queries (e.g., Image-To-Video setting). Recent works address this severe degradation by transferring temporal information from a Video-based network to an Image-based one. In this work, we devise a training strategy that allows the transfer of a superior knowledge, arising from a set of views depicting the target object. Our proposal - Views Knowledge Distillation (VKD) - pins this visual variety as a supervision signal within a teacher-student framework, where the teacher educates a student who observes fewer views. As a result, the student outperforms not only its teacher but also the current state-of-the-art in Image-To-Video by a wide margin (6.3% mAP on MARS, 8.6% on Duke-Video-ReId and 5% on VeRi-776). A thorough analysis - on Person, Vehicle and Animal Re-ID - investigates the properties of VKD from a qualitatively and quantitatively perspective. Code is available at https://github.com/aimagelab/VKD.