 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoQuant: Quantization of Prototypical Parts For General and Fine-Grained Image Classification
Feb 06, 2026Prototypical parts-based models offer a "this looks like that" paradigm for intrinsic interpretability, yet they typically struggle with ImageNet-scale generalization and often require computationally expensive backbone finetuning. Furthermore, existing methods frequently suffer from "prototype drift," where learned prototypes lack tangible grounding in the training distribution and change their activation under small perturbations. We present ProtoQuant, a novel architecture that achieves prototype stability and grounded interpretability through latent vector quantization. By constraining prototypes to a discrete learned codebook within the latent space, we ensure they remain faithful representations of the training data without the need to update the backbone. This design allows ProtoQuant to function as an efficient, interpretable head that scales to large-scale datasets. We evaluate ProtoQuant on ImageNet and several fine-grained benchmarks (CUB-200, Cars-196). Our results demonstrate that ProtoQuant achieves competitive classification accuracy while generalizing to ImageNet and comparable interpretability metrics to other prototypical-parts-based methods.
OMENN: One Matrix to Explain Neural Networks
Dec 03, 2024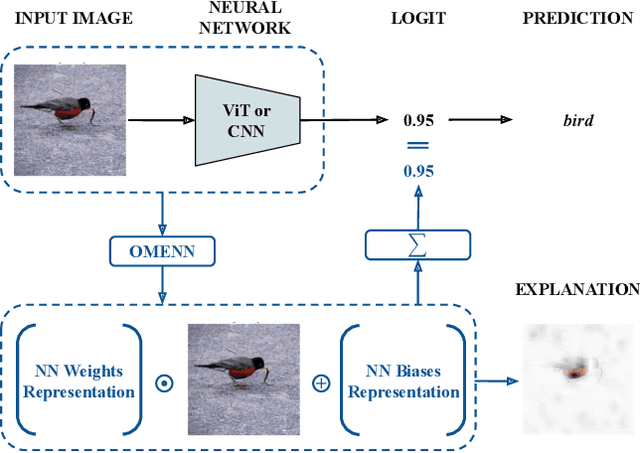
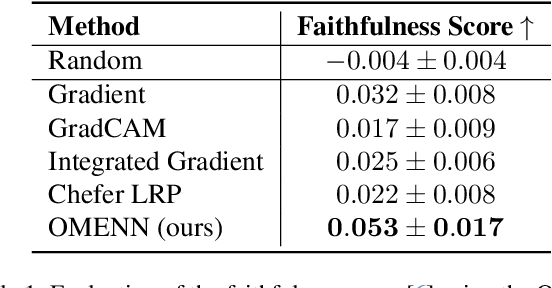
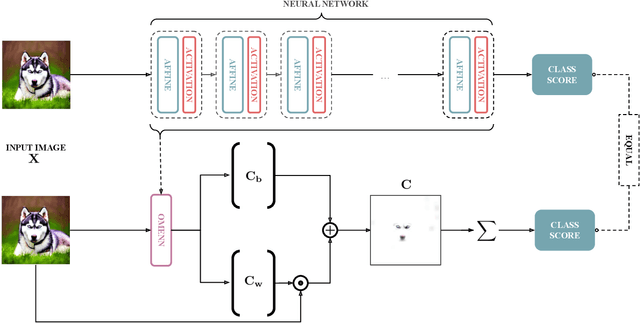
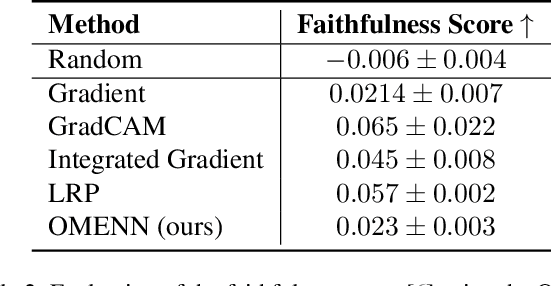
Deep Learning (DL) models are often black boxes, making their decision-making processes difficult to interpret. This lack of transparency has driven advancements in eXplainable Artificial Intelligence (XAI), a field dedicated to clarifying the reasoning behind DL model predictions. Among these, attribution-based methods such as LRP and GradCAM are widely used, though they rely on approximations that can be imprecise. To address these limitations, we introduce One Matrix to Explain Neural Networks (OMENN), a novel post-hoc method that represents a neural network as a single, interpretable matrix for each specific input. This matrix is constructed through a series of linear transformations that represent the processing of the input by each successive layer in the neural network. As a result, OMENN provides locally precise, attribution-based explanations of the input across various modern models, including ViTs and CNNs. We present a theoretical analysis of OMENN based on dynamic linearity property and validate its effectiveness with extensive tests on two XAI benchmarks, demonstrating that OMENN is competitive with state-of-the-art methods.