 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Preference Elicitation in Interactive and User-centered Algorithmic Recourse: An Initial Exploration
Apr 08, 2024

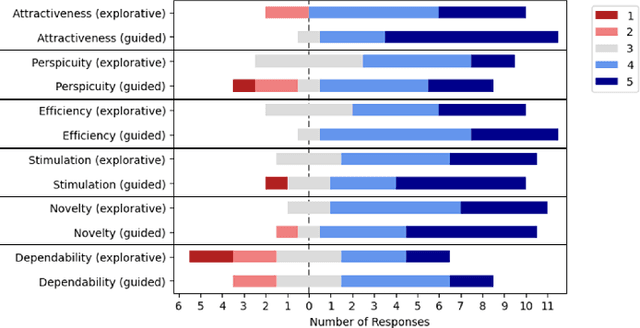
Algorithmic Recourse aims to provide actionable explanations, or recourse plans, to overturn potentially unfavourable decisions taken by automated machine learning models. In this paper, we propose an interaction paradigm based on a guided interaction pattern aimed at both eliciting the users' preferences and heading them toward effective recourse interventions. In a fictional task of money lending, we compare this approach with an exploratory interaction pattern based on a combination of alternative plans and the possibility of freely changing the configurations by the users themselves. Our results suggest that users may recognize that the guided interaction paradigm improves efficiency. However, they also feel less freedom to experiment with "what-if" scenarios. Nevertheless, the time spent on the purely exploratory interface tends to be perceived as a lack of efficiency, which reduces attractiveness, perspicuity, and dependability. Conversely, for the guided interface, more time on the interface seems to increase its attractiveness, perspicuity, and dependability while not impacting the perceived efficiency. That might suggest that this type of interfaces should combine these two approaches by trying to support exploratory behavior while gently pushing toward a guided effective solution.
Annotation and Classification of Relevant Clauses in Terms-and-Conditions Contracts
Feb 22, 2024

In this paper, we propose a new annotation scheme to classify different types of clauses in Terms-and-Conditions contracts with the ultimate goal of supporting legal experts to quickly identify and assess problematic issues in this type of legal documents. To this end, we built a small corpus of Terms-and-Conditions contracts and finalized an annotation scheme of 14 categories, eventually reaching an inter-annotator agreement of 0.92. Then, for 11 of them, we experimented with binary classification tasks using few-shot prompting with a multilingual T5 and two fine-tuned versions of two BERT-based LLMs for Italian. Our experiments showed the feasibility of automatic classification of our categories by reaching accuracies ranging from .79 to .95 on validation tasks.