 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Indexed Active Learning for Matching Heterogeneous Entity Representations
Paper and Code
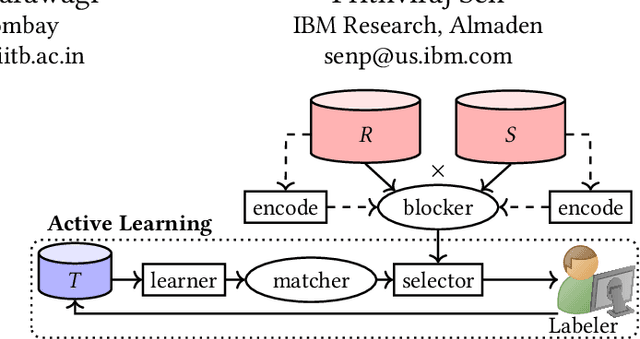
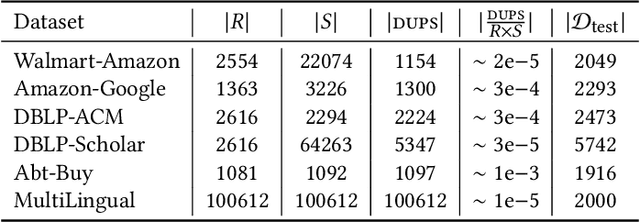
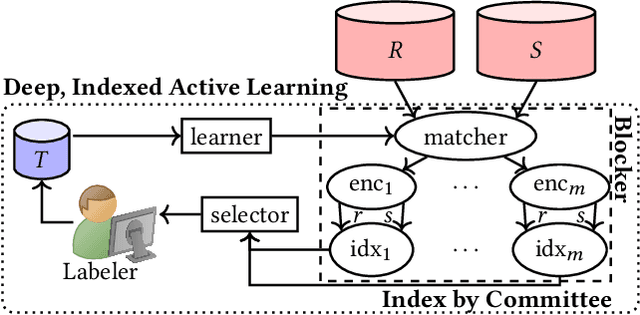
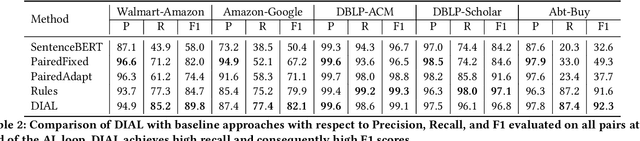
Given two large lists of records, the task in entity resolution (ER) is to find the pairs from the Cartesian product of the lists that correspond to the same real world entity. Typically, passive learning methods on tasks like ER require large amounts of labeled data to yield useful models. Active Learning is a promising approach for ER in low resource settings. However, the search space, to find informative samples for the user to label, grows quadratically for instance-pair tasks making active learning hard to scale. Previous works, in this setting, rely on hand-crafted predicates, pre-trained language model embeddings, or rule learning to prune away unlikely pairs from the Cartesian product. This blocking step can miss out on important regions in the product space leading to low recall. We propose DIAL, a scalable active learning approach that jointly learns embeddings to maximize recall for blocking and accuracy for matching blocked pairs. DIAL uses an Index-By-Committee framework, where each committee member learns representations based on powerful transformer models. We highlight surprising differences between the matcher and the blocker in the creation of the training data and the objective used to train their parameters. Experiments on five benchmark datasets and a multilingual record matching dataset show the effectiveness of our approach in terms of precision, recall and running time. Code is available at https://github.com/ArjitJ/DIAL