 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical token pruning for foundation models in few-shot conversational virtual assistant systems
Aug 21, 2024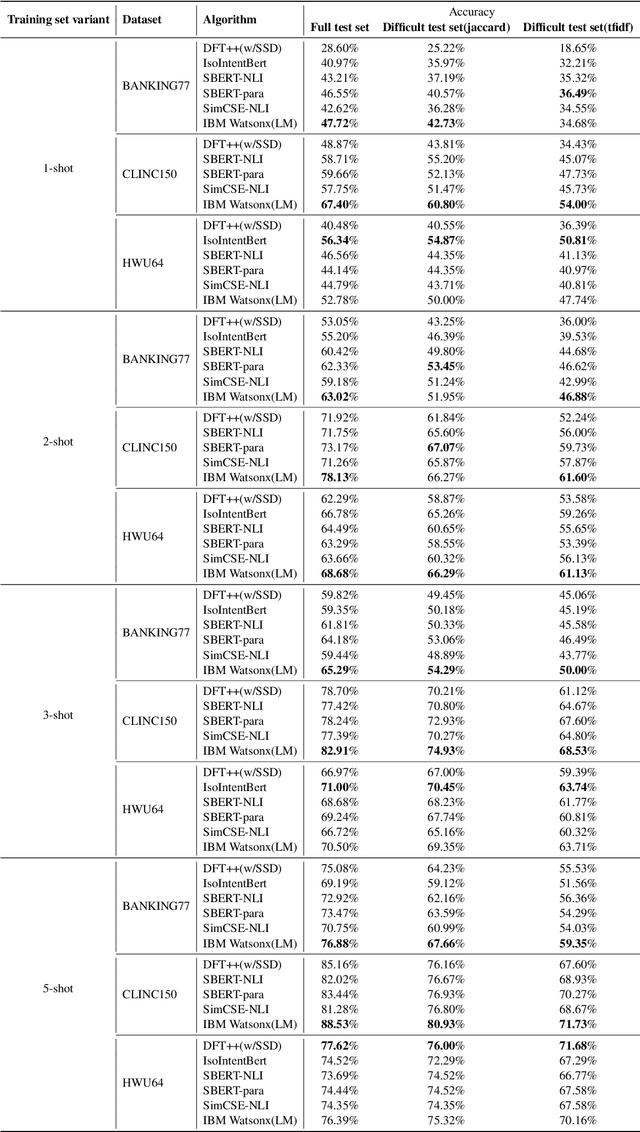
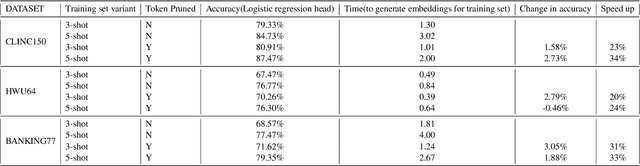
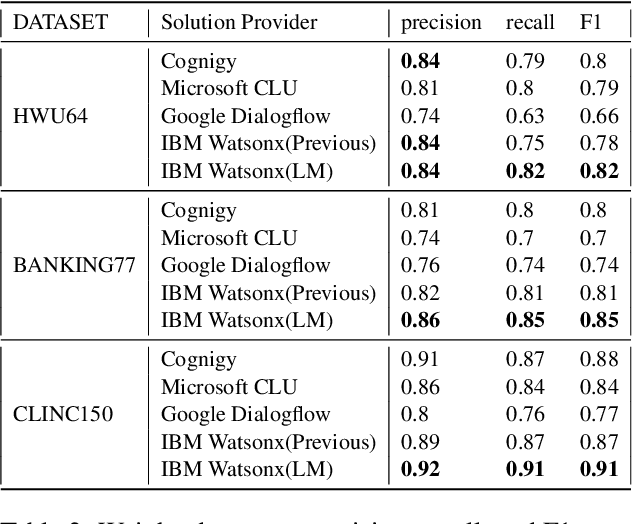
In an enterprise Virtual Assistant (VA) system, intent classification is the crucial component that determines how a user input is handled based on what the user wants. The VA system is expected to be a cost-efficient SaaS service with low training and inference time while achieving high accuracy even with a small number of training samples. We pretrain a transformer-based sentence embedding model with a contrastive learning objective and leverage the embedding of the model as features when training intent classification models. Our approach achieves the state-of-the-art results for few-shot scenarios and performs better than other commercial solutions on popular intent classification benchmarks. However, generating features via a transformer-based model increases the inference time, especially for longer user inputs, due to the quadratic runtime of the transformer's attention mechanism. On top of model distillation, we introduce a practical multi-task adaptation approach that configures dynamic token pruning without the need for task-specific training for intent classification. We demonstrate that this approach improves the inference speed of popular sentence transformer models without affecting model performance.