 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Instance-Aware Domain-Adaptive Panoptic Segmentation
Apr 04, 2024
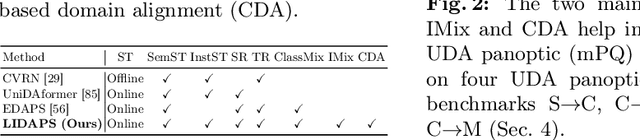
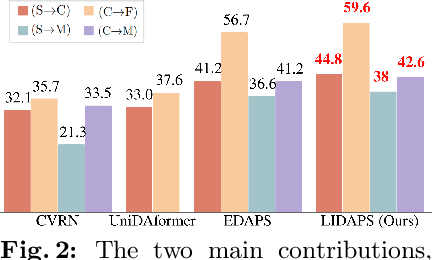
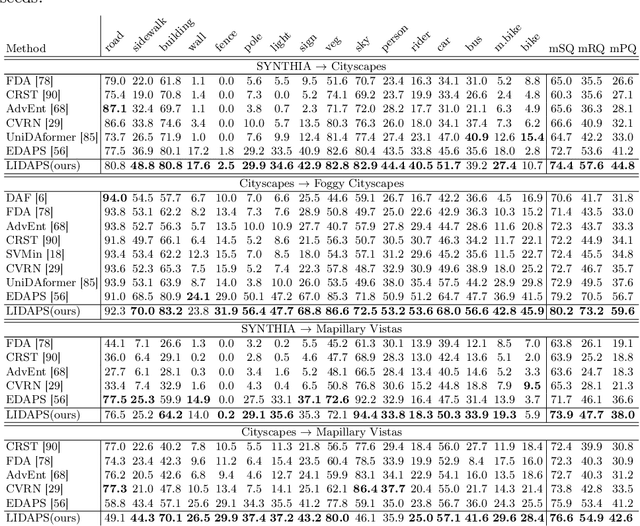
The increasing relevance of panoptic segmentation is tied to the advancements in autonomous driving and AR/VR applications. However, the deployment of such models has been limited due to the expensive nature of dense data annotation, giving rise to unsupervised domain adaptation (UDA). A key challenge in panoptic UDA is reducing the domain gap between a labeled source and an unlabeled target domain while harmonizing the subtasks of semantic and instance segmentation to limit catastrophic interference. While considerable progress has been achieved, existing approaches mainly focus on the adaptation of semantic segmentation. In this work, we focus on incorporating instance-level adaptation via a novel instance-aware cross-domain mixing strategy IMix. IMix significantly enhances the panoptic quality by improving instance segmentation performance. Specifically, we propose inserting high-confidence predicted instances from the target domain onto source images, retaining the exhaustiveness of the resulting pseudo-labels while reducing the injected confirmation bias. Nevertheless, such an enhancement comes at the cost of degraded semantic performance, attributed to catastrophic forgetting. To mitigate this issue, we regularize our semantic branch by employing CLIP-based domain alignment (CDA), exploiting the domain-robustness of natural language prompts. Finally, we present an end-to-end model incorporating these two mechanisms called LIDAPS, achieving state-of-the-art results on all popular panoptic UDA benchmarks.
Fast Point-cloud to Mesh Reconstruction for Deformable Object Tracking
Nov 05, 2023The world around us is full of soft objects that we as humans learn to perceive and deform with dexterous hand movements from a young age. In order for a Robotic hand to be able to control soft objects, it needs to acquire online state feedback of the deforming object. While RGB-D cameras can collect occluded information at a rate of 30 Hz, the latter does not represent a continuously trackable object surface. Hence, in this work, we developed a method that can create deforming meshes of deforming point clouds at a speed of above 50 Hz for different categories of objects. The reconstruction of meshes from point clouds has been long studied in the field of Computer graphics under 3D reconstruction and 4D reconstruction, however both lack the speed and generalizability needed for robotics applications. Our model is designed using a point cloud auto-encoder and a Real-NVP architecture. The latter is a continuous flow neural network with manifold-preservation properties. Our model takes a template mesh which is the mesh of an object in its canonical state and then deforms the template mesh to match a deformed point cloud of the object. Our method can perform mesh reconstruction and tracking at a rate of 58 Hz for deformations of six different ycb categories. An instance of a downstream application can be the control algorithm for a robotic hand that requires online feedback from the state of a manipulated object which would allow online grasp adaptation in a closed-loop manner. Furthermore, the tracking capacity that our method provides can help in the system identification of deforming objects in a marker-free approach. In future work, we will extend our method to more categories of objects and real world deforming point clouds
A Generative Model for Digital Camera Noise Synthesis
Mar 17, 2023



Noise synthesis is a challenging low-level vision task aiming to generate realistic noise given a clean image along with the camera settings. To this end, we propose an effective generative model which utilizes clean features as guidance followed by noise injections into the network. Specifically, our generator follows a UNet-like structure with skip connections but without downsampling and upsampling layers. Firstly, we extract deep features from a clean image as the guidance and concatenate a Gaussian noise map to the transition point between the encoder and decoder as the noise source. Secondly, we propose noise synthesis blocks in the decoder in each of which we inject Gaussian noise to model the noise characteristics. Thirdly, we propose to utilize an additional Style Loss and demonstrate that this allows better noise characteristics supervision in the generator. Through a number of new experiments, we evaluate the temporal variance and the spatial correlation of the generated noise which we hope can provide meaningful insights for future works. Finally, we show that our proposed approach outperforms existing methods for synthesizing camera noise.