 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-LSTM: a Differentiable Recurrent Surface for Asynchronous Event-Based Data
Paper and Code

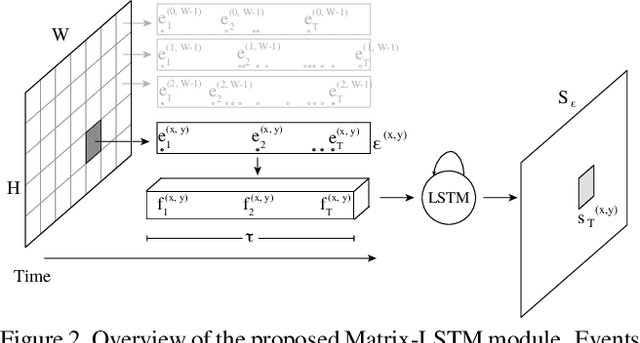

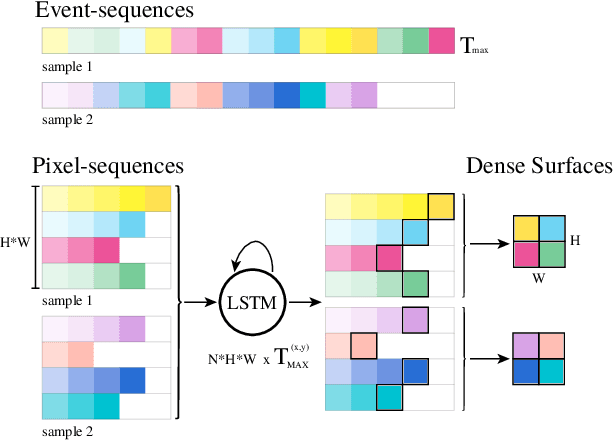
Dynamic Vision Sensors (DVSs) asynchronously stream events in correspondence of pixels subject to brightness changes. Differently from classic vision devices, they produce a sparse representation of the scene. Therefore, to apply standard computer vision algorithms, events need to be integrated into a frame or event-surface. This is usually attained through hand-crafted grids that reconstruct the frame using ad-hoc heuristics. In this paper, we propose Matrix-LSTM, a grid of Long Short-Term Memory (LSTM) cells to learn end-to-end a task-dependent event-surfaces. Compared to existing reconstruction approaches, our learned event-surface shows good flexibility and expressiveness improving the baselines on optical flow estimation on the MVSEC benchmark and the state-of-the-art of event-based object classification on the N-Cars dataset.