 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity of Neural Policy Mirror Descent for Policy Optimization on Low-Dimensional Manifolds
Paper and Code
Sep 25, 2023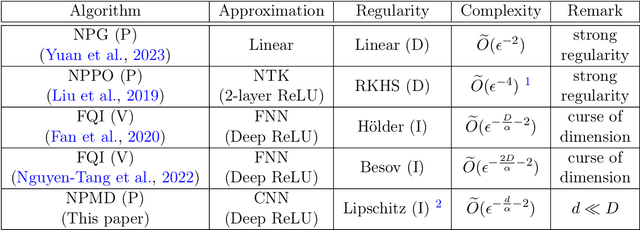
Policy-based algorithms equipped with deep neural networks have achieved great success in solving high-dimensional policy optimization problems in reinforcement learning. However, current analyses cannot explain why they are resistant to the curse of dimensionality. In this work, we study the sample complexity of the neural policy mirror descent (NPMD) algorithm with convolutional neural networks (CNN) as function approximators. Motivated by the empirical observation that many high-dimensional environments have state spaces possessing low-dimensional structures, such as those taking images as states, we consider the state space to be a $d$-dimensional manifold embedded in the $D$-dimensional Euclidean space with intrinsic dimension $d\ll D$. We show that in each iteration of NPMD, both the value function and the policy can be well approximated by CNNs. The approximation errors are controlled by the size of the networks, and the smoothness of the previous networks can be inherited. As a result, by properly choosing the network size and hyperparameters, NPMD can find an $\epsilon$-optimal policy with $\widetilde{O}(\epsilon^{-\frac{d}{\alpha}-2})$ samples in expectation, where $\alpha\in(0,1]$ indicates the smoothness of environment. Compared to previous work, our result exhibits that NPMD can leverage the low-dimensional structure of state space to escape from the curse of dimensionality, providing an explanation for the efficacy of deep policy-based algorithms.