 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood regularity creates large learning rate implicit biases: edge of stability, balancing, and catapult
Paper and Code
Oct 26, 2023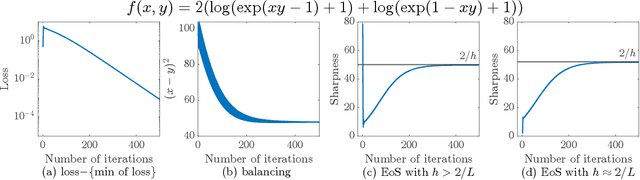

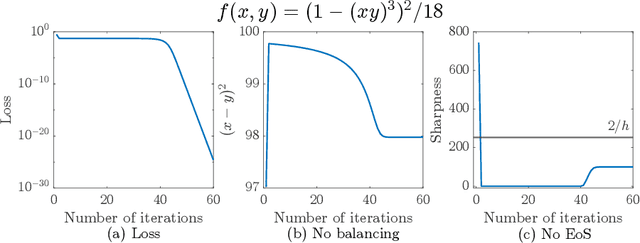
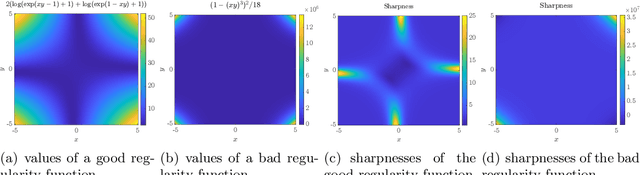
Large learning rates, when applied to gradient descent for nonconvex optimization, yield various implicit biases including the edge of stability (Cohen et al., 2021), balancing (Wang et al., 2022), and catapult (Lewkowycz et al., 2020). These phenomena cannot be well explained by classical optimization theory. Though significant theoretical progress has been made in understanding these implicit biases, it remains unclear for which objective functions would they occur. This paper provides an initial step in answering this question, namely that these implicit biases are in fact various tips of the same iceberg. They occur when the objective function of optimization has some good regularity, which, in combination with a provable preference of large learning rate gradient descent for moving toward flatter regions, results in these nontrivial dynamical phenomena. To establish this result, we develop a new global convergence theory under large learning rates, for a family of nonconvex functions without globally Lipschitz continuous gradient, which was typically assumed in existing convergence analysis. A byproduct is the first non-asymptotic convergence rate bound for large-learning-rate gradient descent optimization of nonconvex functions. We also validate our theory with experiments on neural networks, where different losses, activation functions, and batch normalization all can significantly affect regularity and lead to very different training dynamics.