 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Fine-Grained Symmetry Inference and Enforcement for Rigorous Crystal Structure Prediction
Feb 19, 2026Crystal structure prediction (CSP), which aims to predict the three-dimensional atomic arrangement of a crystal from its composition, is central to materials discovery and mechanistic understanding. Existing deep learning models often treat crystallographic symmetry only as a soft heuristic or rely on space group and Wyckoff templates retrieved from known structures, which limits both physical fidelity and the ability to discover genuinely new material structures. In contrast to retrieval-based methods, our approach leverages large language models to encode chemical semantics and directly generate fine-grained Wyckoff patterns from composition, effectively circumventing the limitations inherent to database lookups. Crucially, we incorporate domain knowledge into the generative process through an efficient constrained-optimization search that rigorously enforces algebraic consistency between site multiplicities and atomic stoichiometry. By integrating this symmetry-consistent template into a diffusion backbone, our approach constrains the stochastic generative trajectory to a physically valid geometric manifold. This framework achieves state-of-the-art performance across stability, uniqueness, and novelty (SUN) benchmarks, alongside superior matching performance, thereby establishing a new paradigm for the rigorous exploration of targeted crystallographic space. This framework enables efficient expansion into previously uncharted materials space, eliminating reliance on existing databases or a priori structural knowledge.
From Emergence to Control: Probing and Modulating Self-Reflection in Language Models
Jun 13, 2025Self-reflection -- the ability of a large language model (LLM) to revisit, evaluate, and revise its own reasoning -- has recently emerged as a powerful behavior enabled by reinforcement learning with verifiable rewards (RLVR). While self-reflection correlates with improved reasoning accuracy, its origin and underlying mechanisms remain poorly understood. In this work, {\it we first show that self-reflection is not exclusive to RLVR fine-tuned models: it already emerges, albeit rarely, in pretrained models}. To probe this latent ability, we introduce Reflection-Inducing Probing, a method that injects reflection-triggering reasoning traces from fine-tuned models into pretrained models. This intervention raises self-reflection frequency of Qwen2.5 from 0.6\% to 18.6\%, revealing a hidden capacity for reflection. Moreover, our analysis of internal representations shows that both pretrained and fine-tuned models maintain hidden states that distinctly separate self-reflective from non-reflective contexts. Leveraging this observation, {\it we then construct a self-reflection vector, a direction in activation space associated with self-reflective reasoning}. By manipulating this vector, we enable bidirectional control over the self-reflective behavior for both pretrained and fine-tuned models. Experiments across multiple reasoning benchmarks show that enhancing these vectors improves reasoning performance by up to 12\%, while suppressing them reduces computational cost, providing a flexible mechanism to navigate the trade-off between reasoning quality and efficiency without requiring additional training. Our findings further our understanding of self-reflection and support a growing body of work showing that understanding model internals can enable precise behavioral control.
Tangram: A Challenging Benchmark for Geometric Element Recognizing
Aug 25, 2024



Significant advancements in Large Multimodal Models (LMMs) have enabled them to tackle complex problems involving visual-mathematical reasoning. However, their ability to identify geometric elements remains understudied. To bridge this gap, we introduce Tangram, a novel benchmark designed to evaluate the performance of LMMs on geometric element recognition. Tangram includes 1,080 diverse geometric diagrams sourced from primary and secondary school exams, competitions, and textbooks, covering from simple basic geometric shapes to complex combinations. Each diagram is associated with four questions, resulting in a total of 4,320 visual-question-answer pairs. Unlike existing benchmarks that seek higher-level cognition and reasoning, Tangram focuses on the understanding of geometric elements, requiring models to perform a "simple but interesting" counting task. Systematic evaluation of 10 prominent LMMs, such as GPT-4o and Claude 3.5 Sonnet, shows that even in the seemingly simple task, these models still face significant challenges. Notably, the overall accuracy of the top performer across all tested models is only 56.8%, marking a significant gap when compared to human performance. These findings highlight the limitations of current multimodal artificial intelligence systems in handling basic perception tasks, and will inspire the development of the next generation of expert-level multimodal foundational models. The Tangram and evaluation code will be available soon.
FCDS: Fusing Constituency and Dependency Syntax into Document-Level Relation Extraction
Mar 04, 2024



Document-level Relation Extraction (DocRE) aims to identify relation labels between entities within a single document. It requires handling several sentences and reasoning over them. State-of-the-art DocRE methods use a graph structure to connect entities across the document to capture dependency syntax information. However, this is insufficient to fully exploit the rich syntax information in the document. In this work, we propose to fuse constituency and dependency syntax into DocRE. It uses constituency syntax to aggregate the whole sentence information and select the instructive sentences for the pairs of targets. It exploits the dependency syntax in a graph structure with constituency syntax enhancement and chooses the path between entity pairs based on the dependency graph. The experimental results on datasets from various domains demonstrate the effectiveness of the proposed method. The code is publicly available at this url.
Harmonizing Covariance and Expressiveness for Deep Hamiltonian Regression in Crystalline Material Research: a Hybrid Cascaded Regression Framework
Jan 15, 2024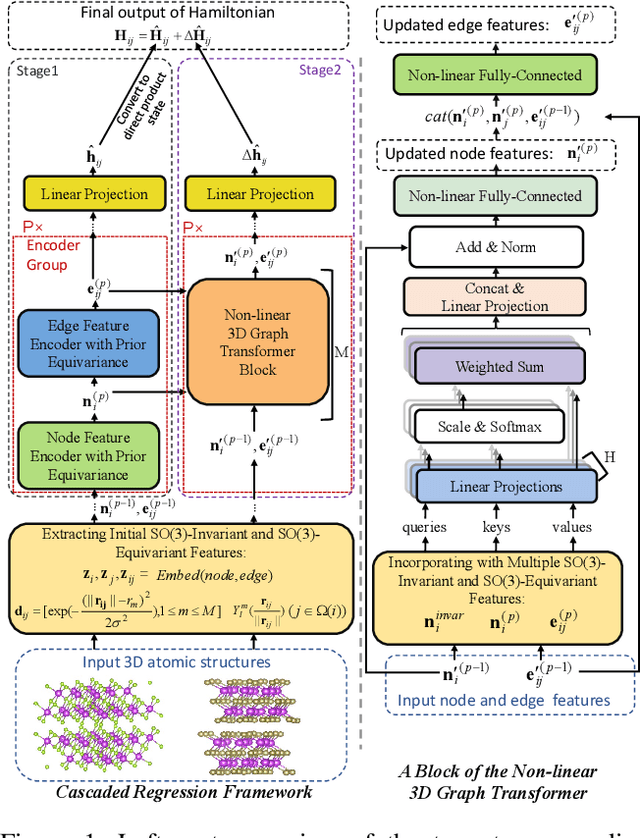
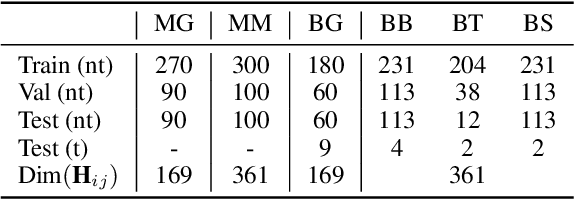
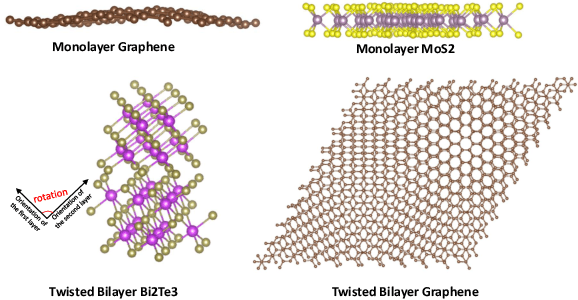
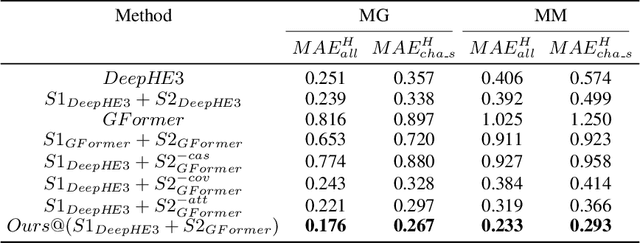
Deep learning for Hamiltonian regression of quantum systems in material research necessitates satisfying the covariance laws, among which achieving SO(3)-equivariance without sacrificing the expressiveness capability of networks remains an elusive challenge due to the restriction to non-linear mappings on guaranteeing theoretical equivariance. To alleviate the covariance-expressiveness dilemma, we propose a hybrid framework with two cascaded regression stages. The first stage, i.e., a theoretically-guaranteed covariant neural network modeling symmetry properties of 3D atom systems, predicts baseline Hamiltonians with theoretically covariant features extracted, assisting the second stage in learning covariance. Meanwhile, the second stage, powered by a non-linear 3D graph Transformer network we propose for structural modeling of atomic systems, refines the first stage's output as a fine-grained prediction of Hamiltonians with better expressiveness capability. The combination of a theoretically covariant yet inevitably less expressive model with a highly expressive non-linear network enables precise, generalizable predictions while maintaining robust covariance under coordinate transformations. Our method achieves state-of-the-art performance in Hamiltonian prediction for electronic structure calculations, confirmed through experiments on six crystalline material databases. The codes and configuration scripts are available in the supplementary material.