 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOUT: A Situated and Multi-Modal Human-Robot Dialogue Corpus
Nov 19, 2024



We introduce the Situated Corpus Of Understanding Transactions (SCOUT), a multi-modal collection of human-robot dialogue in the task domain of collaborative exploration. The corpus was constructed from multiple Wizard-of-Oz experiments where human participants gave verbal instructions to a remotely-located robot to move and gather information about its surroundings. SCOUT contains 89,056 utterances and 310,095 words from 278 dialogues averaging 320 utterances per dialogue. The dialogues are aligned with the multi-modal data streams available during the experiments: 5,785 images and 30 maps. The corpus has been annotated with Abstract Meaning Representation and Dialogue-AMR to identify the speaker's intent and meaning within an utterance, and with Transactional Units and Relations to track relationships between utterances to reveal patterns of the Dialogue Structure. We describe how the corpus and its annotations have been used to develop autonomous human-robot systems and enable research in open questions of how humans speak to robots. We release this corpus to accelerate progress in autonomous, situated, human-robot dialogue, especially in the context of navigation tasks where details about the environment need to be discovered.
* 14 pages, 7 figures
Balancing Efficiency and Coverage in Human-Robot Dialogue Collection
Oct 07, 2018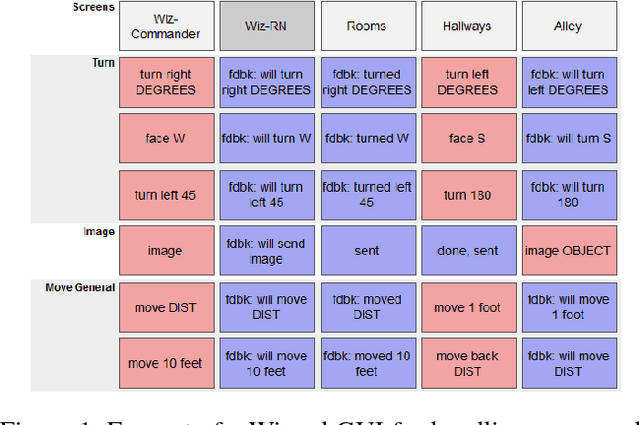
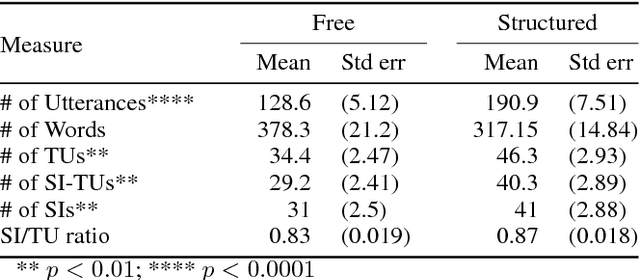
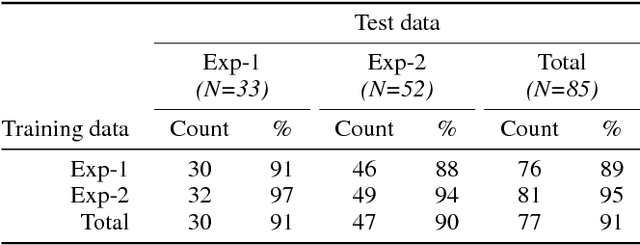
We describe a multi-phased Wizard-of-Oz approach to collecting human-robot dialogue in a collaborative search and navigation task. The data is being used to train an initial automated robot dialogue system to support collaborative exploration tasks. In the first phase, a wizard freely typed robot utterances to human participants. For the second phase, this data was used to design a GUI that includes buttons for the most common communications, and templates for communications with varying parameters. Comparison of the data gathered in these phases show that the GUI enabled a faster pace of dialogue while still maintaining high coverage of suitable responses, enabling more efficient targeted data collection, and improvements in natural language understanding using GUI-collected data. As a promising first step towards interactive learning, this work shows that our approach enables the collection of useful training data for navigation-based HRI tasks.
ScoutBot: A Dialogue System for Collaborative Navigation
Jul 21, 2018
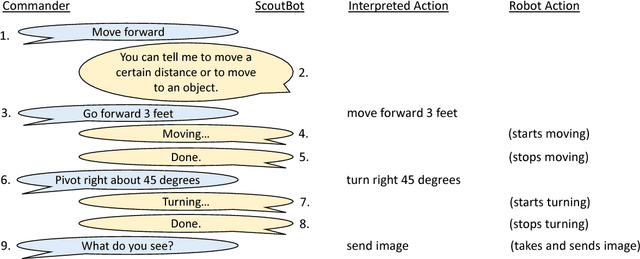
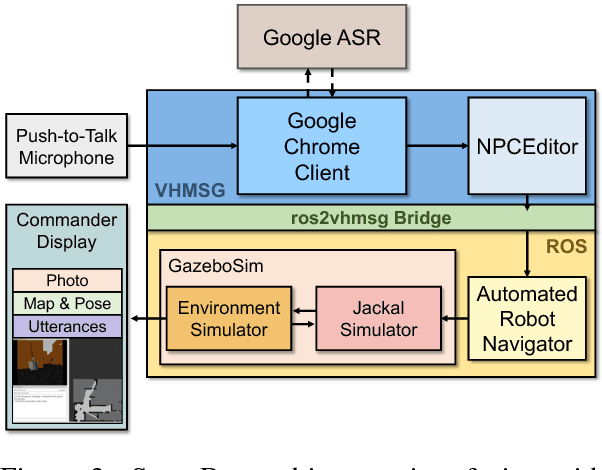

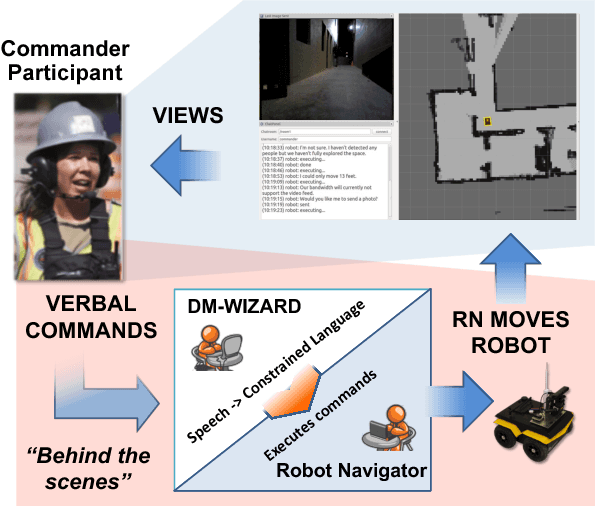
ScoutBot is a dialogue interface to physical and simulated robots that supports collaborative exploration of environments. The demonstration will allow users to issue unconstrained spoken language commands to ScoutBot. ScoutBot will prompt for clarification if the user's instruction needs additional input. It is trained on human-robot dialogue collected from Wizard-of-Oz experiments, where robot responses were initiated by a human wizard in previous interactions. The demonstration will show a simulated ground robot (Clearpath Jackal) in a simulated environment supported by ROS (Robot Operating System).
Laying Down the Yellow Brick Road: Development of a Wizard-of-Oz Interface for Collecting Human-Robot Dialogue
Oct 17, 2017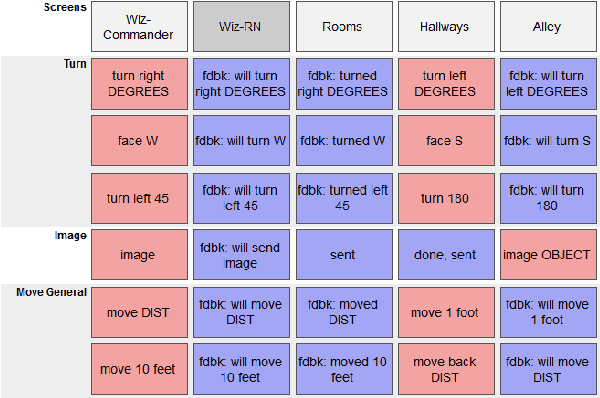
We describe the adaptation and refinement of a graphical user interface designed to facilitate a Wizard-of-Oz (WoZ) approach to collecting human-robot dialogue data. The data collected will be used to develop a dialogue system for robot navigation. Building on an interface previously used in the development of dialogue systems for virtual agents and video playback, we add templates with open parameters which allow the wizard to quickly produce a wide variety of utterances. Our research demonstrates that this approach to data collection is viable as an intermediate step in developing a dialogue system for physical robots in remote locations from their users - a domain in which the human and robot need to regularly verify and update a shared understanding of the physical environment. We show that our WoZ interface and the fixed set of utterances and templates therein provide for a natural pace of dialogue with good coverage of the navigation domain.
An Active Learning Based Approach For Effective Video Annotation And Retrieval
Apr 27, 2015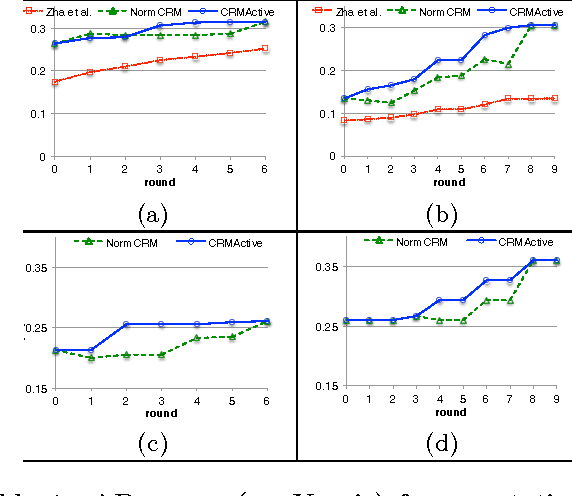
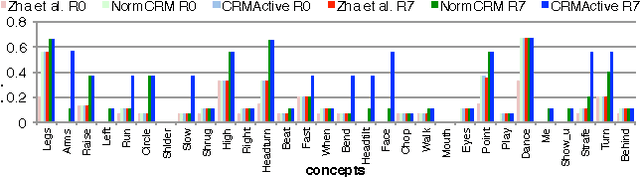

Conventional multimedia annotation/retrieval systems such as Normalized Continuous Relevance Model (NormCRM) [16] require a fully labeled training data for a good performance. Active Learning, by determining an order for labeling the training data, allows for a good performance even before the training data is fully annotated. In this work we propose an active learning algorithm, which combines a novel measure of sample uncertainty with a novel clustering-based approach for determining sample density and diversity and integrate it with NormCRM. The clusters are also iteratively refined to ensure both feature and label-level agreement among samples. We show that our approach outperforms multiple baselines both on a recent, open character animation dataset and on the popular TRECVID corpus at both the tasks of annotation and text-based retrieval of videos.