 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Gelfond Rationality Principle Towards More Comprehensive Foundational Principles for Answer Set Semantics
Jul 02, 2025Non-monotonic logic programming is the basis for a declarative problem solving paradigm known as answer set programming (ASP). Departing from the seminal definition by Gelfond and Lifschitz in 1988 for simple normal logic programs, various answer set semantics have been proposed for extensions. We consider two important questions: (1) Should the minimal model property, constraint monotonicity and foundedness as defined in the literature be mandatory conditions for an answer set semantics in general? (2) If not, what other properties could be considered as general principles for answer set semantics? We address the two questions. First, it seems that the three aforementioned conditions may sometimes be too strong, and we illustrate with examples that enforcing them may exclude expected answer sets. Second, we evolve the Gelfond answer set (GAS) principles for answer set construction by refining the Gelfond's rationality principle to well-supportedness, minimality w.r.t. negation by default and minimality w.r.t. epistemic negation. The principle of well-supportedness guarantees that every answer set is constructible from if-then rules obeying a level mapping and is thus free of circular justification, while the two minimality principles ensure that the formalism minimizes knowledge both at the level of answer sets and of world views. Third, to embody the refined GAS principles, we extend the notion of well-supportedness substantially to answer sets and world views, respectively. Fourth, we define new answer set semantics in terms of the refined GAS principles. Fifth, we use the refined GAS principles as an alternative baseline to intuitively assess the existing answer set semantics. Finally, we analyze the computational complexity.
Efficient Token-Guided Image-Text Retrieval with Consistent Multimodal Contrastive Training
Jun 15, 2023



Image-text retrieval is a central problem for understanding the semantic relationship between vision and language, and serves as the basis for various visual and language tasks. Most previous works either simply learn coarse-grained representations of the overall image and text, or elaborately establish the correspondence between image regions or pixels and text words. However, the close relations between coarse- and fine-grained representations for each modality are important for image-text retrieval but almost neglected. As a result, such previous works inevitably suffer from low retrieval accuracy or heavy computational cost. In this work, we address image-text retrieval from a novel perspective by combining coarse- and fine-grained representation learning into a unified framework. This framework is consistent with human cognition, as humans simultaneously pay attention to the entire sample and regional elements to understand the semantic content. To this end, a Token-Guided Dual Transformer (TGDT) architecture which consists of two homogeneous branches for image and text modalities, respectively, is proposed for image-text retrieval. The TGDT incorporates both coarse- and fine-grained retrievals into a unified framework and beneficially leverages the advantages of both retrieval approaches. A novel training objective called Consistent Multimodal Contrastive (CMC) loss is proposed accordingly to ensure the intra- and inter-modal semantic consistencies between images and texts in the common embedding space. Equipped with a two-stage inference method based on the mixed global and local cross-modal similarity, the proposed method achieves state-of-the-art retrieval performances with extremely low inference time when compared with representative recent approaches.
Vision-Language Navigation with Random Environmental Mixup
Jun 15, 2021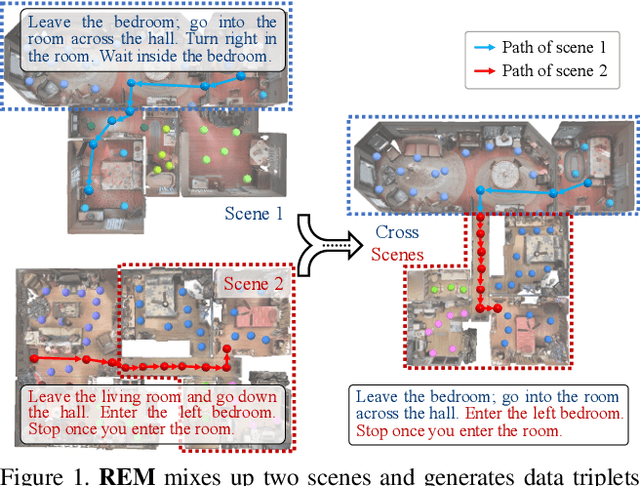
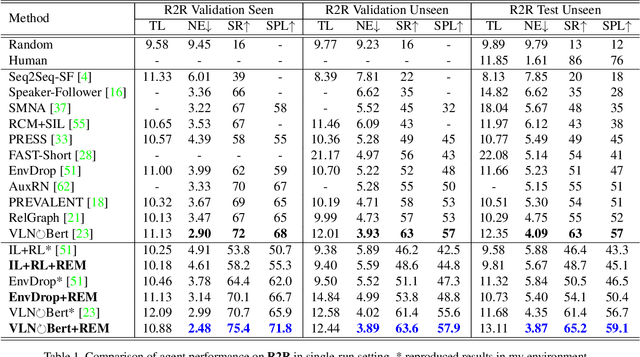
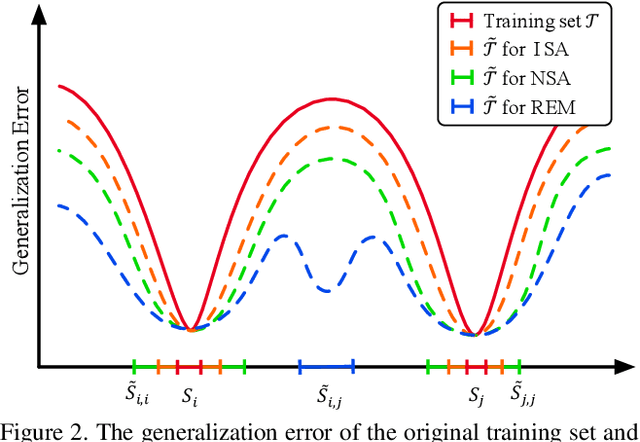
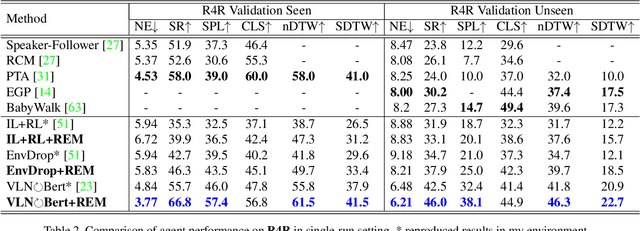
Vision-language Navigation (VLN) tasks require an agent to navigate step-by-step while perceiving the visual observations and comprehending a natural language instruction. Large data bias, which is caused by the disparity ratio between the small data scale and large navigation space, makes the VLN task challenging. Previous works have proposed various data augmentation methods to reduce data bias. However, these works do not explicitly reduce the data bias across different house scenes. Therefore, the agent would overfit to the seen scenes and achieve poor navigation performance in the unseen scenes. To tackle this problem, we propose the Random Environmental Mixup (REM) method, which generates cross-connected house scenes as augmented data via mixuping environment. Specifically, we first select key viewpoints according to the room connection graph for each scene. Then, we cross-connect the key views of different scenes to construct augmented scenes. Finally, we generate augmented instruction-path pairs in the cross-connected scenes. The experimental results on benchmark datasets demonstrate that our augmentation data via REM help the agent reduce its performance gap between the seen and unseen environment and improve the overall performance, making our model the best existing approach on the standard VLN benchmark.
City-Scale Multi-Camera Vehicle Tracking Guided by Crossroad Zones
May 14, 2021

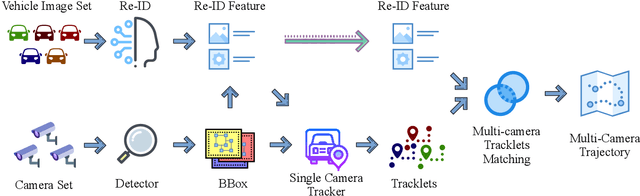

Multi-Target Multi-Camera Tracking has a wide range of applications and is the basis for many advanced inferences and predictions. This paper describes our solution to the Track 3 multi-camera vehicle tracking task in 2021 AI City Challenge (AICITY21). This paper proposes a multi-target multi-camera vehicle tracking framework guided by the crossroad zones. The framework includes: (1) Use mature detection and vehicle re-identification models to extract targets and appearance features. (2) Use modified JDETracker (without detection module) to track single-camera vehicles and generate single-camera tracklets. (3) According to the characteristics of the crossroad, the Tracklet Filter Strategy and the Direction Based Temporal Mask are proposed. (4) Propose Sub-clustering in Adjacent Cameras for multi-camera tracklets matching. Through the above techniques, our method obtained an IDF1 score of 0.8095, ranking first on the leaderboard. The code have released: https://github.com/LCFractal/AIC21-MTMC.
Constraint Monotonicity, Epistemic Splitting and Foundedness Are Too Strong in Answer Set Programming
Oct 01, 2020Recently, some researchers in the community of answer set programming introduced the notions of subjective constraint monotonicity, epistemic splitting, and foundedness for epistemic logic programs, aiming to use them as main criteria/intuitions to compare different answer set semantics proposed in the literature on how they comply with these intuitions. In this note we demonstrate that these three properties are too strong and may exclude some desired answer sets/world views. Therefore, such properties should not be used as necessary conditions for answer set semantics.
Unity Style Transfer for Person Re-Identification
Mar 04, 2020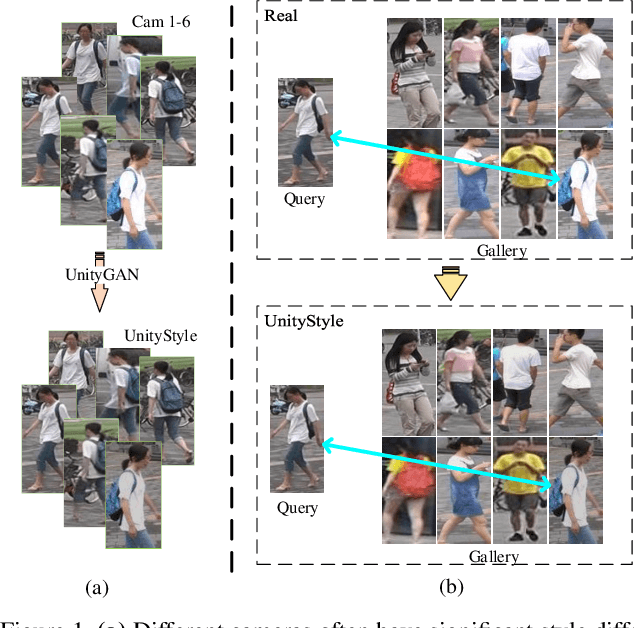


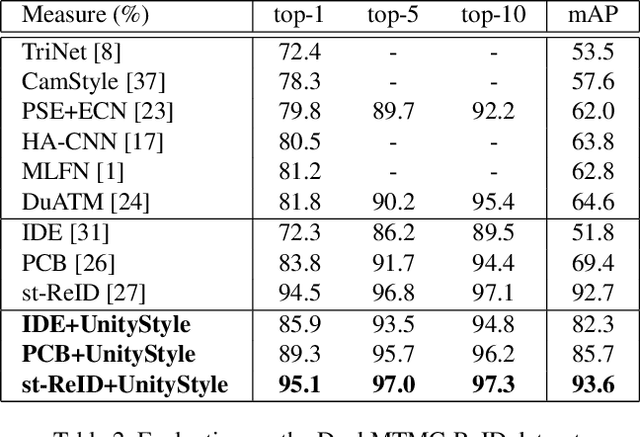
Style variation has been a major challenge for person re-identification, which aims to match the same pedestrians across different cameras. Existing works attempted to address this problem with camera-invariant descriptor subspace learning. However, there will be more image artifacts when the difference between the images taken by different cameras is larger. To solve this problem, we propose a UnityStyle adaption method, which can smooth the style disparities within the same camera and across different cameras. Specifically, we firstly create UnityGAN to learn the style changes between cameras, producing shape-stable style-unity images for each camera, which is called UnityStyle images. Meanwhile, we use UnityStyle images to eliminate style differences between different images, which makes a better match between query and gallery. Then, we apply the proposed method to Re-ID models, expecting to obtain more style-robust depth features for querying. We conduct extensive experiments on widely used benchmark datasets to evaluate the performance of the proposed framework, the results of which confirm the superiority of the proposed model.
Dual-Path Convolutional Image-Text Embedding with Instance Loss
Jul 17, 2018



Matching images and sentences demands a fine understanding of both modalities. In this paper, we propose a new system to discriminatively embed the image and text to a shared visual-textual space. In this field, most existing works apply the ranking loss to pull the positive image / text pairs close and push the negative pairs apart from each other. However, directly deploying the ranking loss is hard for network learning, since it starts from the two heterogeneous features to build inter-modal relationship. To address this problem, we propose the instance loss which explicitly considers the intra-modal data distribution. It is based on an unsupervised assumption that each image / text group can be viewed as a class. So the network can learn the fine granularity from every image/text group. The experiment shows that the instance loss offers better weight initialization for the ranking loss, so that more discriminative embeddings can be learned. Besides, existing works usually apply the off-the-shelf features, i.e., word2vec and fixed visual feature. So in a minor contribution, this paper constructs an end-to-end dual-path convolutional network to learn the image and text representations. End-to-end learning allows the system to directly learn from the data and fully utilize the supervision. On two generic retrieval datasets (Flickr30k and MSCOCO), experiments demonstrate that our method yields competitive accuracy compared to state-of-the-art methods. Moreover, in language based person retrieval, we improve the state of the art by a large margin. The code has been made publicly available.
Unsupervised Feature Selection with Adaptive Structure Learning
Apr 03, 2015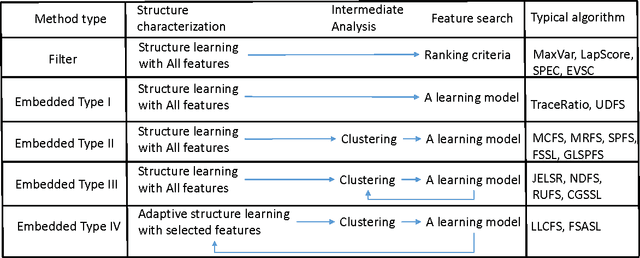
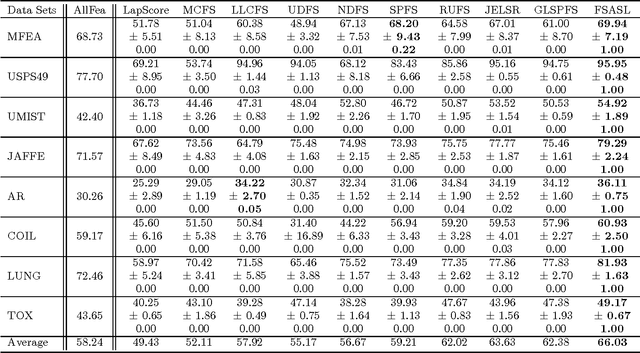

The problem of feature selection has raised considerable interests in the past decade. Traditional unsupervised methods select the features which can faithfully preserve the intrinsic structures of data, where the intrinsic structures are estimated using all the input features of data. However, the estimated intrinsic structures are unreliable/inaccurate when the redundant and noisy features are not removed. Therefore, we face a dilemma here: one need the true structures of data to identify the informative features, and one need the informative features to accurately estimate the true structures of data. To address this, we propose a unified learning framework which performs structure learning and feature selection simultaneously. The structures are adaptively learned from the results of feature selection, and the informative features are reselected to preserve the refined structures of data. By leveraging the interactions between these two essential tasks, we are able to capture accurate structures and select more informative features. Experimental results on many benchmark data sets demonstrate that the proposed method outperforms many state of the art unsupervised feature selection methods.
Embedding Description Logic Programs into Default Logic
Nov 07, 2011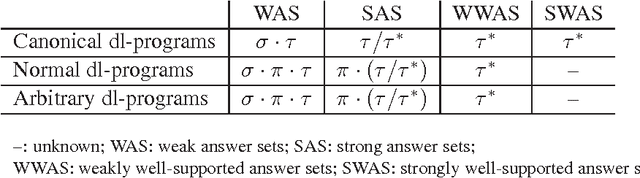
Description logic programs (dl-programs) under the answer set semantics formulated by Eiter {\em et al.} have been considered as a prominent formalism for integrating rules and ontology knowledge bases. A question of interest has been whether dl-programs can be captured in a general formalism of nonmonotonic logic. In this paper, we study the possibility of embedding dl-programs into default logic. We show that dl-programs under the strong and weak answer set semantics can be embedded in default logic by combining two translations, one of which eliminates the constraint operator from nonmonotonic dl-atoms and the other translates a dl-program into a default theory. For dl-programs without nonmonotonic dl-atoms but with the negation-as-failure operator, our embedding is polynomial, faithful, and modular. In addition, our default logic encoding can be extended in a simple way to capture recently proposed weakly well-supported answer set semantics, for arbitrary dl-programs. These results reinforce the argument that default logic can serve as a fruitful foundation for query-based approaches to integrating ontology and rules. With its simple syntax and intuitive semantics, plus available computational results, default logic can be considered an attractive approach to integration of ontology and rules.
Loop Formulas for Description Logic Programs
Jul 23, 2010
Description Logic Programs (dl-programs) proposed by Eiter et al. constitute an elegant yet powerful formalism for the integration of answer set programming with description logics, for the Semantic Web. In this paper, we generalize the notions of completion and loop formulas of logic programs to description logic programs and show that the answer sets of a dl-program can be precisely captured by the models of its completion and loop formulas. Furthermore, we propose a new, alternative semantics for dl-programs, called the {\em canonical answer set semantics}, which is defined by the models of completion that satisfy what are called canonical loop formulas. A desirable property of canonical answer sets is that they are free of circular justifications. Some properties of canonical answer sets are also explored.
* 29 pages, 1 figures (in pdf), a short version appeared in ICLP'10